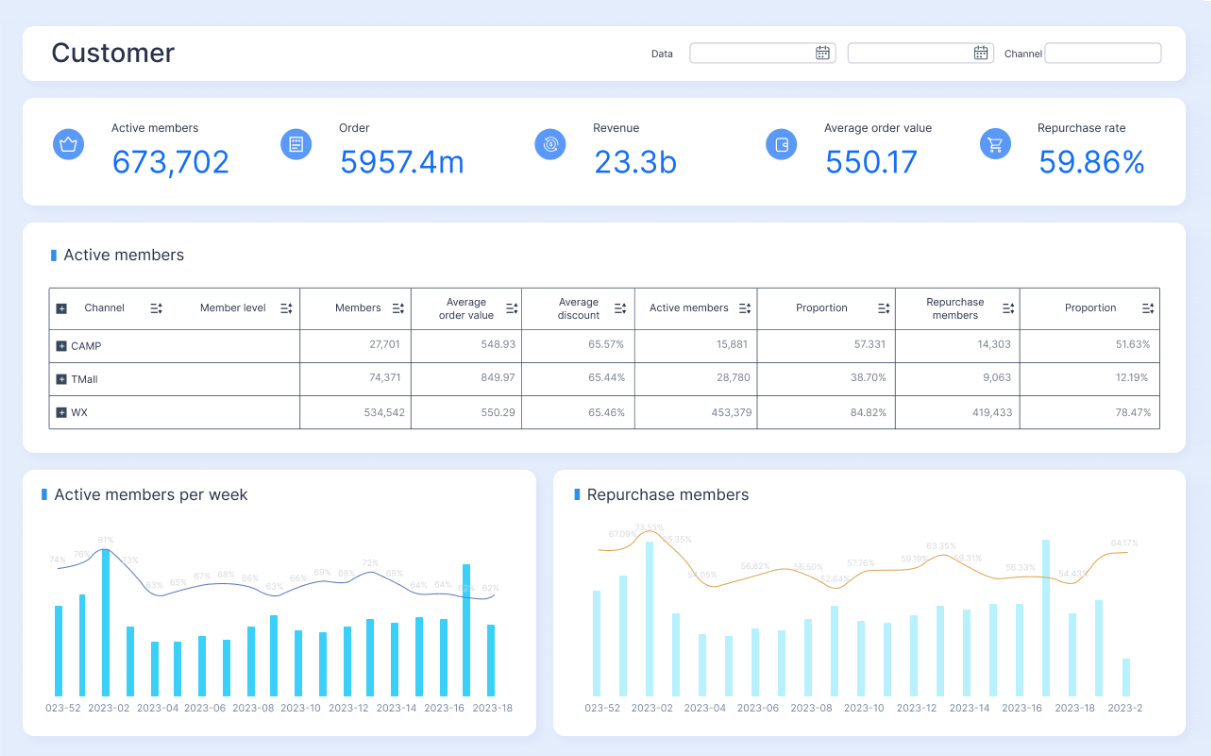
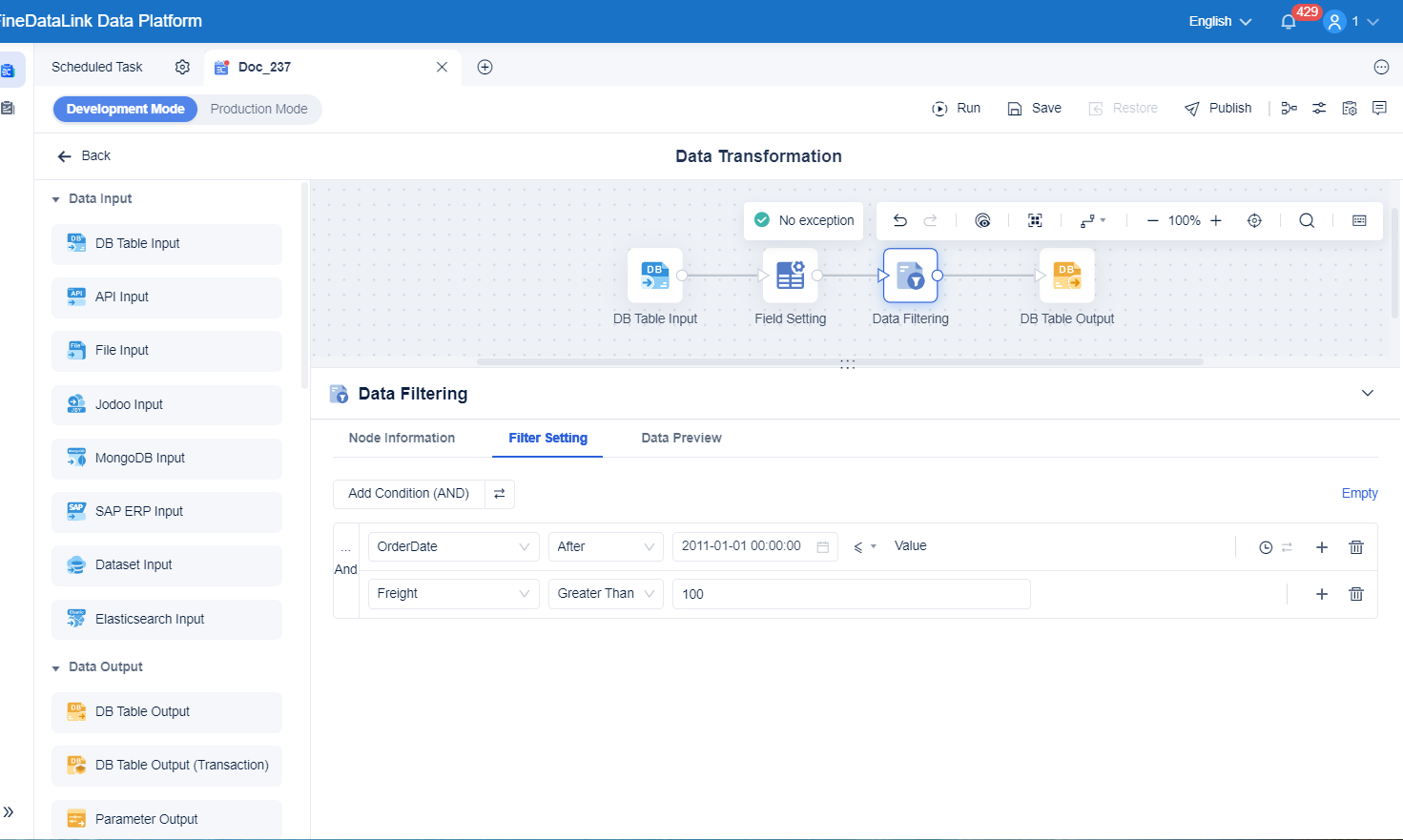
Choosing between Data Lakehouse vs Data Warehouse is not a theoretical architecture debate. It is an operating decision that affects analytics speed, governance quality, cloud cost, and how confidently teams can use data every day.
For most enterprises, the right answer depends on five factors:
Who uses the data
What kinds of data you manage
Which workloads matter most
How strict governance must be
How much flexibility you need as requirements change
A finance team building board-ready KPI dashboards has very different needs from a product team analyzing clickstream events or a data science team training models on years of raw history. That is why the best platform is rarely the one with the most features on paper. It is the one that best fits the people, data types, and workload patterns in your business.
In this guide, we will break down the Data Lakehouse vs Data Warehouse decision through seven practical use cases. The goal is simple: help you identify which architecture is the safer choice, which is the more flexible choice, and when a hybrid approach makes the most business sense.
Data Lakehouse vs Data Warehouse: How to Make the Right Choice
The core decision is not “Which platform is more modern?” It is “Which platform best supports our business outcomes with the least friction?”
A data warehouse is typically the better fit when you need curated, structured, highly governed data for repeatable reporting and fast SQL analytics. A data lakehouse is often stronger when you need one environment to support mixed data types, large-scale ingestion, data engineering, analytics, and machine learning together.
That distinction matters because the same company can have multiple valid answers at once.
Executives want trusted dashboards.
Analysts want fast SQL and stable definitions.
Data engineers want scalable pipelines.
Data scientists want access to raw and refined data.
Compliance teams want lineage, retention, and auditability.
The best option depends on who uses the data and how fast it needs to move. If reporting logic changes slowly and trust matters more than flexibility, a warehouse is usually the simplest answer. If teams need to work with logs, events, files, streams, and BI tables in one foundation, a lakehouse becomes much more attractive.
This article covers seven real-world scenarios:
Finance and executive reporting
Marketing and product analytics
Data science and machine learning
Operations telemetry and IoT
Self-service business analytics
Enterprise-wide data platforms
Regulated industries with strict governance
By the end, you should have a practical shortlist rather than a vague architecture preference.
Data Lakehouse vs Data Warehouse: Core Differences That Shape the Decision
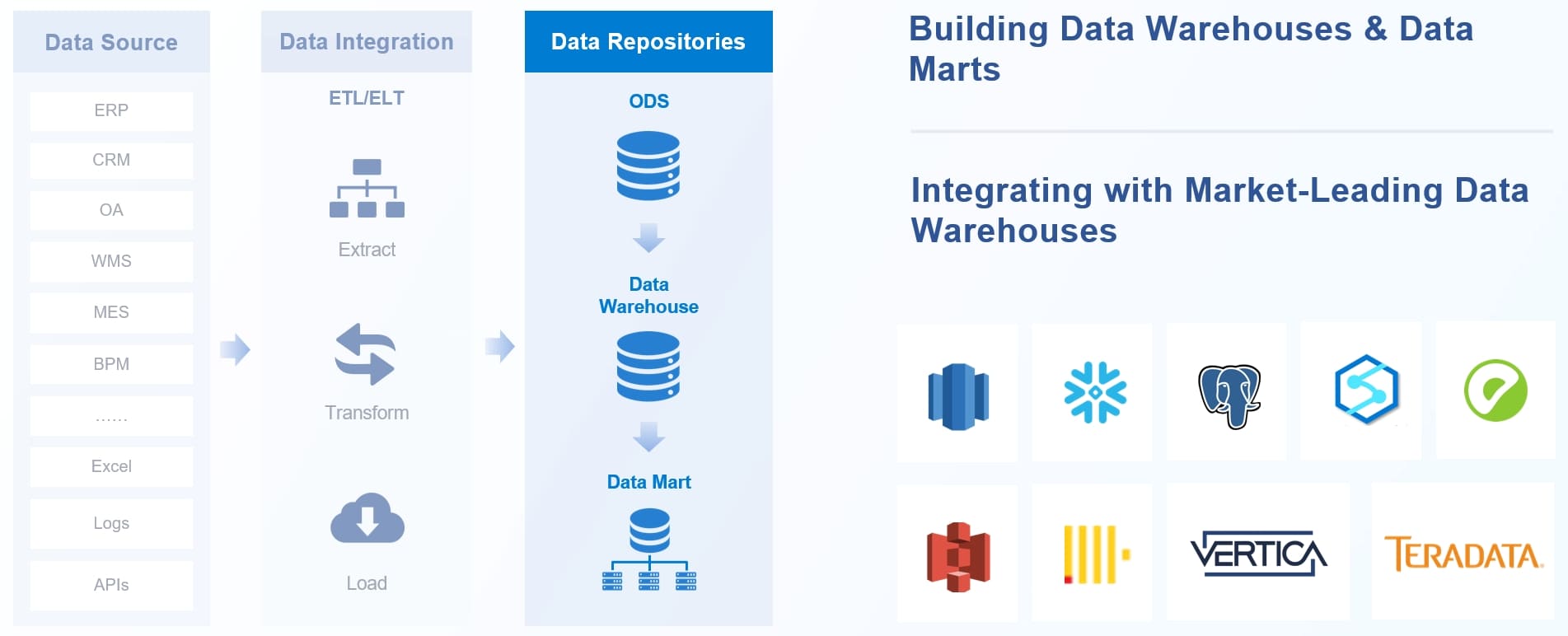
Architecture, storage, and compute model
A data warehouse is usually designed as a centralized analytics platform optimized for structured data and SQL-based reporting. In many warehouse environments, storage, metadata, optimization, and query execution are tightly managed as one integrated service. That makes operations simpler for business analytics teams and often improves performance consistency.
A data lakehouse uses low-cost object storage and separates storage from compute more explicitly. It combines open storage patterns with warehouse-like table management, metadata, transaction support, and query engines. This model gives organizations more flexibility to scale storage and compute independently.
Here is the practical impact:
Dimension
Data Warehouse
Data Lakehouse
Storage model
Curated analytical storage
Open object storage with table layer
Compute model
Integrated and optimized for BI
Decoupled, flexible, multi-engine
Scalability
Strong for analytics growth
Strong for mixed workloads and large volumes
Flexibility
Best for structured analytics
Best for mixed data and evolving use cases
Operational simplicity
Usually higher for BI teams
Usually higher for engineering-led teams
A warehouse often wins on simplicity and predictable BI performance. A lakehouse often wins on flexibility, scale, and multi-workload support.
After complex architecture explanations, stakeholders often need a visual that maps storage, compute, and consumption layers clearly.
Structured, semi-structured, and unstructured data support
This is one of the clearest dividing lines in the Data Lakehouse vs Data Warehouse comparison.
A data warehouse is strongest when most of your data is structured and modeled into clean relational tables. Think:
Sales facts
Financial metrics
Customer dimensions
Operational KPIs
Standardized reporting marts
A data lakehouse is better suited when your environment includes a mix of:
Structured tables
JSON events
Application logs
IoT telemetry
Documents
Images or media files
Rapidly changing upstream schemas
Warehouses typically rely more heavily on schema-on-write discipline. Data is cleaned, conformed, and modeled before broad business use. That improves trust and consistency, but it can slow ingestion when source structures change frequently.
Lakehouses are more accommodating of schema evolution. Teams can ingest data earlier, preserve raw detail, and refine it in stages. This is especially useful when source systems are messy, event-heavy, or still evolving.
In practical terms:
Choose a warehouse for stable BI tables and controlled reporting models.
Choose a lakehouse when data variety is high and future use cases are not fully known yet.
Governance, performance, and cost trade-offs
Governance, performance, and cost are where architecture decisions become executive decisions.
A data warehouse often provides stronger default controls for:
Trusted business definitions
Role-based access
Curated data models
Consistent SQL performance
High concurrency for dashboards and reports
A data lakehouse can also support strong governance, but it usually requires more deliberate design across metadata, catalogs, access policies, lineage, and table management. When done well, it can support enterprise-grade control with broader flexibility. When done poorly, it can become harder to manage.
Performance trade-offs are workload-specific:
For repetitive BI queries and dashboard concurrency, warehouses often have the edge.
For large-scale ingestion, raw data retention, feature engineering, and mixed compute engines, lakehouses often have the edge.
Cost trade-offs also vary:
Warehouses may be more expensive for storing massive raw or historical data.
Lakehouses usually offer lower-cost storage at scale.
Warehouses often provide more cost predictability for standard analytics.
Lakehouses may require more platform engineering discipline to prevent inefficiency.
If your priority is audited metrics and dashboard responsiveness, a warehouse is frequently the safer choice. If your priority is storing everything cheaply and supporting many advanced workloads, a lakehouse is often the stronger foundation.
After a governance and cost discussion, a simple visual helps leadership understand trade-offs fast.
Data Lakehouse vs Data Warehouse: 7 Real-World Use Cases by Team, Data Type, and Workload
1. Finance and executive reporting teams with stable KPI dashboards
This is the classic data warehouse use case.
Finance, strategy, and executive teams need stable metrics, repeatable definitions, and auditable reporting logic. They do not want five versions of revenue, margin, pipeline, or cash flow. They want one trusted number, fast.
A warehouse is usually the best fit when:
Metrics are standardized
Auditability is critical
Reporting definitions change slowly
Dashboard response time matters
Access must be tightly controlled
The main advantage here is not just query speed. It is consistency. A warehouse supports curated semantic models, strong SQL performance, and controlled access patterns that reduce reporting disputes.
Typical workloads include:
Board reporting
Monthly close analysis
Budget vs actual tracking
Executive scorecards
Department KPI dashboards
In this scenario, a lakehouse can still play a role upstream for raw ingestion or historical storage, but the final consumption layer for executives is often best served through warehouse-style curated models.
After describing stable KPI use cases, a visual should reinforce trust and consistency.
2. Marketing and product teams analyzing clickstream and campaign data
This is where the data lakehouse often becomes more compelling.
Marketing and product teams work with high-volume, fast-changing, semi-structured data. They need to combine campaign data, app events, attribution logs, CRM records, web analytics, and product behavior signals. The shape of the analysis changes constantly.
A lakehouse is usually the better fit when:
Event volume is high
JSON and log-style data are common
Teams ask exploratory questions
Attribution logic changes often
Analysts and engineers must iterate quickly
Typical questions include:
Which channels drive high-value users?
Where do users drop in the onboarding flow?
Which campaign cohorts retain best after 30 days?
How do product events relate to conversion quality?
A traditional warehouse can still power downstream dashboards, but forcing all clickstream and event data into rigid models too early often slows analysis and limits flexibility.
A lakehouse allows teams to ingest raw events, evolve schemas, and enrich data incrementally. That makes it easier to support both ad hoc exploration and downstream reporting.
If teams later need curated dashboards for campaign ROI or funnel conversion, that refined layer can still be served in a highly business-friendly model.
After explaining exploratory event analytics, a visual should show funnel and attribution movement clearly.
3. Data science and machine learning teams working with raw and refined data
For data science and machine learning, the data lakehouse is usually the stronger default.
These teams need access to:
Raw historical data
Refined analytical tables
Large feature datasets
Experiment outputs
Multiple file formats
Notebook-friendly workflows
A warehouse can support some ML-adjacent analytics, but it is rarely ideal as the only foundation for experimentation-heavy work. Data scientists often need broad access to large volumes of source data before it has been fully modeled.
A lakehouse is a better fit when teams need to:
Build features from raw and curated data
Train models on long time horizons
Use notebooks and distributed processing
Work with Parquet, JSON, text, images, or embeddings
Run iterative experiments without heavy remodelling each time
This is especially valuable when ML pipelines depend on both business tables and raw operational signals.
For enterprises building modern AI-ready pipelines, the key is not just storage. It is also reliable data movement across systems. This is where tools like FineDataLink can become useful in the broader architecture. If your lakehouse strategy depends on syncing operational sources, CDC pipelines, and multi-system delivery into analytics environments, integration reliability directly affects model quality and reporting freshness.
After discussing feature engineering and experimentation, the ideal visual is workflow-oriented.
4. Operations teams monitoring IoT, logs, or application telemetry
Operations data changes the decision fast.
IoT streams, machine telemetry, system logs, and application events arrive continuously, often at high volume and inconsistent quality. Keeping all of that in a warehouse can become expensive and operationally awkward.
A data lakehouse is often the better fit when:
Ingestion is continuous
Retention periods are long
Data quality varies by source
Real-time or near-real-time analysis is needed
Downstream reporting still matters
The trade-off is important:
A lakehouse is strong for low-cost retention and scalable ingestion.
A warehouse is often stronger for highly curated downstream reporting.
Many operations teams need both.
A common pattern is:
Land raw telemetry in lakehouse storage
Clean and enrich it in stages
Push selected aggregates or KPI tables to a reporting layer
This gives teams flexibility without forcing every log line into a BI-optimized model from day one.
If near-real-time operational data must feed both dashboards and alerting workflows, data integration design matters as much as storage design. FineDataLink can be relevant here when organizations need stable, low-latency data pipelines between production systems and analytical environments without building every connector and sync process manually.
After discussing telemetry and retention, use a time-series operational visual.
5. Customer support and business teams needing self-service analytics
When the users are not data engineers or data scientists, usability beats flexibility.
Customer support leaders, sales managers, operations analysts, and line-of-business teams usually need:
In this case, curated semantic layers matter more than broad access to raw files. The goal is not maximum platform flexibility. The goal is broad adoption with low confusion.
A warehouse is usually best when:
Most users are SQL-light or dashboard-first
Business definitions must stay stable
Dashboard responsiveness is a priority
Access control must be simple and clear
The organization wants fewer interpretation errors
Lakehouse access can empower technical teams, but too much raw-data exposure often creates friction for business users. In self-service settings, a curated warehouse model usually outperforms a flexible raw-data environment.
6. Enterprise data platforms consolidating many domains in one foundation
This is one of the strongest data lakehouse scenarios.
When an enterprise wants one foundation for BI, data engineering, and ML, a lakehouse becomes attractive because it reduces fragmentation across domains and workloads.
This is especially relevant for organizations trying to avoid:
Duplicate pipelines
Separate storage layers by team
Repeated data copies
Inconsistent definitions across tools
Complex handoffs between engineering, analytics, and data science
A lakehouse is often the best fit when the goal is to support:
This does not mean every team should consume raw lakehouse tables directly. In mature enterprise platforms, the winning model is often one foundation, multiple serving layers. Raw and refined data live in the broader lakehouse environment, while business-facing consumption is still curated carefully.
This is also where robust data integration becomes strategic. A unified platform fails if source-to-target delivery is fragile. FineDataLink can be a practical addition when enterprises need to move and synchronize data across databases, applications, and cloud targets with lower engineering overhead and stronger operational continuity.
After discussing consolidated enterprise platforms, a domain-level architecture visual works best.
7. Regulated industries with strict governance and lineage requirements
Highly regulated environments require a more careful answer. There is no automatic winner.
Banking, insurance, healthcare, pharmaceuticals, and public sector teams often care most about:
Access control
Lineage
Reproducibility
Retention enforcement
Audit readiness
Policy-driven data use
A data warehouse is often the safer choice when governance needs are immediate, reporting is structured, and auditability must be simple to demonstrate.
A data lakehouse can also work well if the organization has the metadata, catalog, policy enforcement, and operational maturity to govern mixed data at scale. In some regulated enterprises, a lakehouse is preferred because it centralizes storage and preserves more detailed historical records. But it requires strong architectural discipline.
A practical rule:
If regulation primarily affects standardized reporting, a warehouse often wins.
If regulation affects broad data estates with multiple analytic and ML workloads, a governed lakehouse may be more strategic.
In many regulated environments, the answer is hybrid: retain broader enterprise data in a lakehouse foundation and publish controlled reporting products through warehouse-style curated layers.
After discussing lineage and policy enforcement, use a compliance-oriented visual.
A Practical Framework to Choose Between Data Lakehouse vs Data Warehouse
Start with workload and query patterns
Start with what people actually do, not what vendors claim.
If the majority of value comes from dashboard consumption, do not overcomplicate the environment. If the majority of value comes from mixed workloads and data flexibility, do not force everything into rigid warehouse models too early.
Evaluate team skills and operating model
Architecture decisions fail when they ignore the team operating the platform.
A warehouse often fits best when the organization is:
SQL-first
BI-led
Governance-heavy
Focused on curated models
Light on platform engineering bandwidth
A lakehouse often fits best when the organization has:
Strong data engineering capability
Data science and ML needs
Mixed technical personas
Comfort with open formats and distributed processing
Many organizations do not choose from zero. They modernize from what already exists. That means the real question is often:
Should we extend our current warehouse?
Add a lakehouse foundation?
Move to a hybrid design over time?
This is where future flexibility matters. A warehouse may deliver faster short-term value for a reporting-led business. A lakehouse may offer stronger long-term adaptability as data volume, modality, and AI use cases grow.
Migration planning also matters. Poor data movement design creates stale dashboards, duplicated pipelines, and governance gaps. If your environment spans operational databases, SaaS systems, warehouses, and lakehouse targets, a reliable integration layer is critical. FineDataLink can be a sensible option when the priority is stable, scalable, low-latency data synchronization across heterogeneous systems.
Data Lakehouse vs Data Warehouse: Common Mistakes and a Simple Recommendation Matrix
Mistakes teams make when comparing options
The most common mistake in the Data Lakehouse vs Data Warehouse debate is choosing based on trendiness.
Other frequent mistakes include:
Choosing based only on storage cost
Choosing based only on one benchmark
Ignoring governance maturity
Underestimating self-service needs
Assuming one platform must do everything equally well
Failing to separate raw-data needs from business-consumption needs
A cheap storage layer is not a complete data platform. A fast benchmark is not proof of operational fit. A modern architecture is not automatically a simpler one.
Choose a warehouse when trust, standardization, and BI performance are your top priorities.
Choose a lakehouse when flexibility, data variety, and multi-workload support matter most.
Choose a hybrid model when you need both a scalable raw/refined foundation and highly curated business-facing serving layers.
After the matrix, a one-page decision visual can help non-technical stakeholders decide faster.
Data Lakehouse vs Data Warehouse Conclusion: Match the Platform to the Team and the Workload
There is no universal winner in Data Lakehouse vs Data Warehouse. The right choice depends on the combination of:
Data variety
User needs
Governance demands
Performance expectations
Operating model maturity
If your business runs on trusted, repeatable dashboards and structured reporting, a data warehouse is often the safest and highest-value option. If your organization needs one platform for mixed data, engineering, analytics, and machine learning, a data lakehouse is often the more strategic foundation. If both realities exist at once, a hybrid design is usually the most practical answer.
Use the seven use cases in this guide as a shortlist tool. Start with the team, the data type, and the workload. Then validate the decision against governance, cost, and integration realities.
That approach leads to better architecture decisions than any vendor-led feature checklist.
A data warehouse is built for structured, curated data and consistent SQL analytics, while a data lakehouse is designed to handle structured, semi-structured, and unstructured data in one platform. In practice, warehouses favor simplicity for BI, and lakehouses favor flexibility across analytics, engineering, and machine learning.
A business should choose a data warehouse when reporting definitions are stable, governance requirements are strict, and fast, reliable dashboard performance matters most. It is usually the better fit for finance, executive reporting, and repeatable business analytics.
Yes, a data lakehouse is often better for machine learning and data science because it can store raw history, logs, events, and files alongside refined tables. That makes it easier for technical teams to explore data, build features, and run large-scale experiments without moving data across multiple systems.
Not always, because many organizations still prefer a warehouse for highly governed reporting and a lakehouse for broader data workloads. A hybrid approach is common when different teams need different levels of control, performance, and flexibility.
Start with the users, data types, workload patterns, governance needs, and cost model. If your environment is mostly structured BI data, a warehouse is usually safer, but if you need one foundation for mixed data and evolving use cases, a lakehouse is often the stronger choice.
Product Trial
FineReport
Pixel-perfect reports · Interactive dashboards · Easy data entry · Digital twins