Data pipelines play a crucial role in modern data processing. They automate the flow of python data pipeline from various sources to destinations, ensuring efficiency and scalability. A data pipeline consists of several stages, including extraction, transformation, and loading (ETL). Python excels in building python data pipelines due to its simplicity, flexibility, and extensive libraries like Pandas and NumPy. Python frameworks such as Luigi and Apache Beam further enhance the development of robust and scalable pipelines.
Understanding Data Pipelines
What is a Data Pipeline?
Definition and Purpose
A data pipeline automates the flow of data from various sources to destinations. This process involves extracting, transforming, and loading (ETL) data. Data pipelines ensure data moves efficiently and reliably. Data pipelines support tasks like data collection, cleaning, transformation, and integration. These pipelines play a vital role in managing data for analytics and machine learning.
Key Components
Data pipelines consist of several key components:
Data Sources: These include databases, APIs, and files.
Data Extraction: This stage retrieves data from the sources.
Data Transformation: This step cleans and enriches the data.
Data Loading: This final stage writes the data to the destination, such as a database or data warehouse.
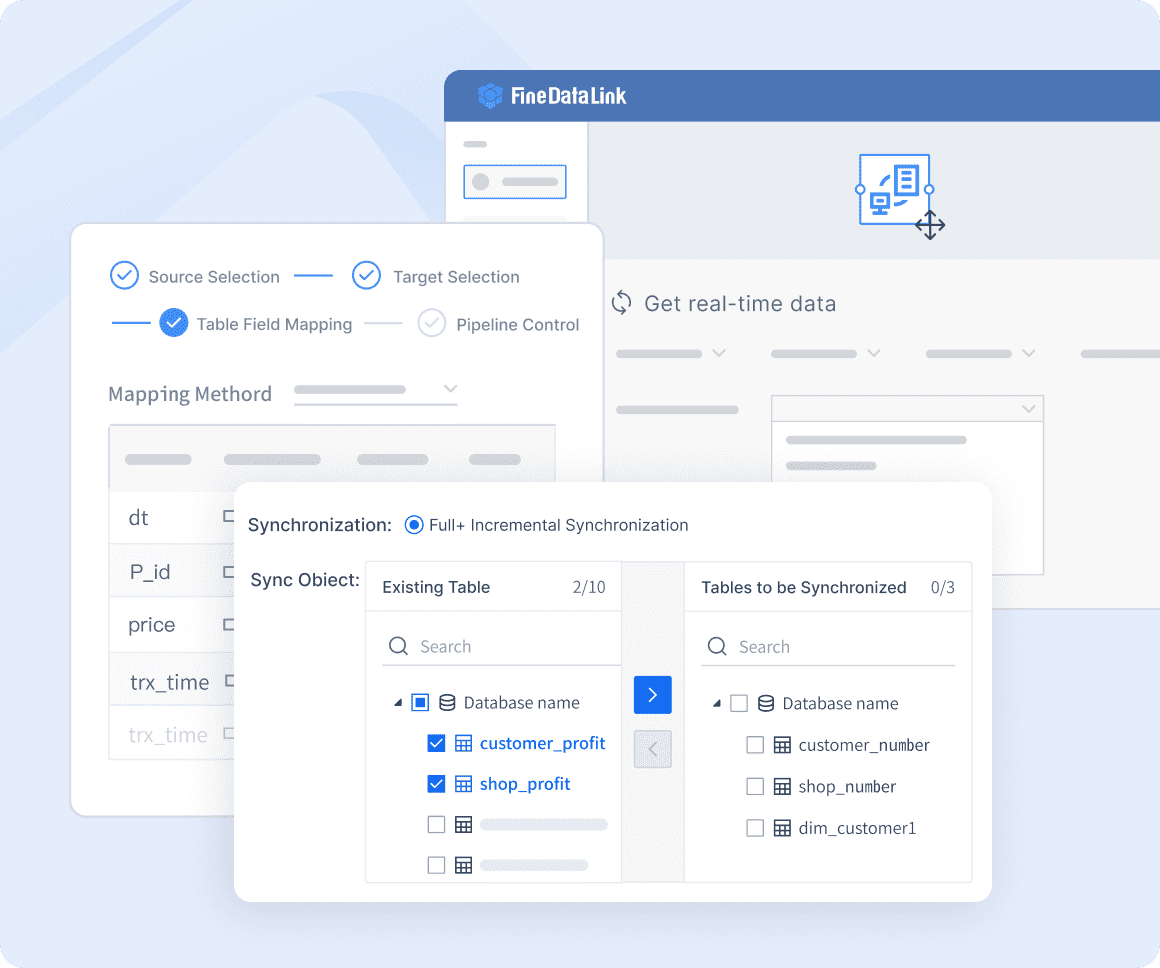
FineDataLink: Efficient ELT and ETL Data Development
Benefits of Using Data Pipelines
Automation
Data pipelines automate repetitive tasks. This automation reduces manual intervention. Automated pipelines ensure consistent data processing. This consistency improves data quality and reliability.
Efficiency
Data pipelines enhance efficiency by streamlining data workflows. Efficient pipelines minimize delays in data processing. This speed allows faster access to insights. Quick access to data supports timely decision-making.
Scalability
Data pipelines offer scalability to handle growing data volumes. Scalable pipelines adapt to increasing data sources and destinations. This adaptability ensures the pipeline remains effective as data needs evolve. Scalability supports the expansion of data-driven projects.
Crafting efficient pipelines benefits data science professionals by supporting tasks like data collection, cleaning, transformation, and integration. These pipelines play a vital role in AI and data science by automating the process of transforming raw data into actionable insights.
Understanding these aspects of data pipelines highlights their importance in modern data processing. Data pipelines ensure smooth, efficient, and scalable data management.
Setting Up Your Environment
Required Tools and Libraries
Python Installation
Start by installing Python. Visit the official Python website to download the latest version. Follow the installation instructions specific to your operating system. Ensure that the installation includes pip, Python's package installer.
Key Libraries
Several libraries enhance data pipeline development in Python:
Apache Beam: Handles both batch and stream processing.
Airflow: Schedules and monitors workflows.
Configuring Your Development Environment
IDE Setup
Choose an Integrated Development Environment (IDE) to streamline coding. Popular choices include PyCharm, VS Code, and Jupyter Notebook. These IDEs offer features like code completion, debugging tools, and integrated terminals.
PyCharm: Provides a robust environment with advanced features for professional developers.
VS Code: Offers flexibility with numerous extensions for Python development.
Create a virtual environment to manage dependencies. This practice isolates project-specific libraries, preventing conflicts with other projects.
Create a virtual environment:
Use venv (a built-in module)
python -m venv myenv
Activate the virtual environment:
On Windows:
myenv\Scripts\activate
On macOS and Linux:
source myenv/bin/activate
Install project dependencies within the activated virtual environment. This setup ensures a clean and manageable development environment. Properly configuring the development environment lays a strong foundation for building efficient and scalable data pipelines.
Designing Your Python Data Pipeline
Defining Data Sources
Types of Data Sources
Data sources serve as the starting point for any python data pipeline. Common data sources include databases, APIs, and flat files. Databases store structured data in tables. Examples include MySQL, PostgreSQL, and SQLite. APIs provide access to data over the web. Popular APIs include Twitter API, Google Maps API, and RESTful services. Flat files contain data in a simple text format. CSV and JSON files are common examples.
Connecting to Data Sources
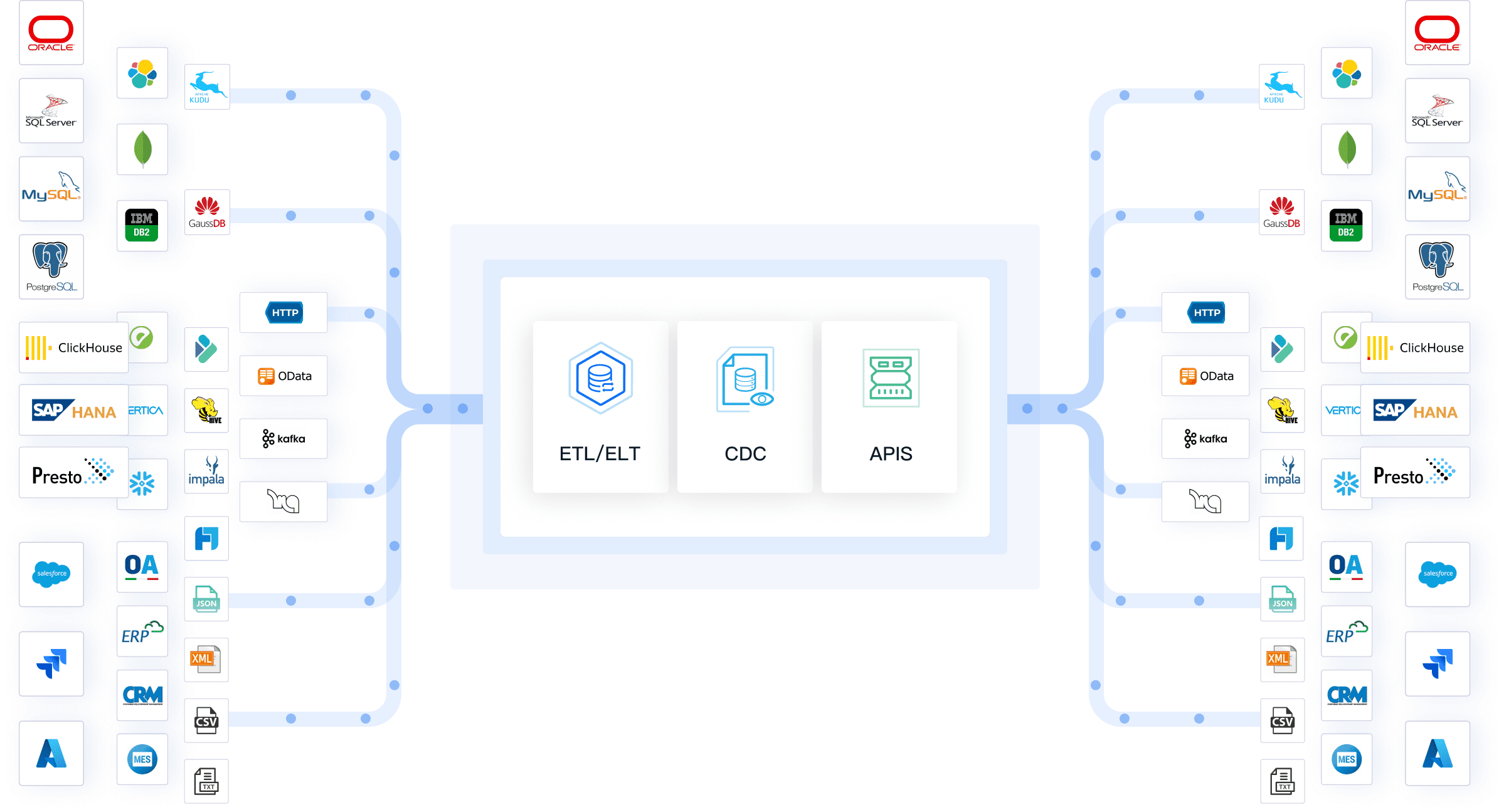
Connecting to data sources demands the use of specialized methods and libraries. For databases, libraries such as SQLAlchemy and psycopg2 are essential for establishing connections and executing queries. When working with APIs, the requests library is commonly used to manage HTTP requests and responses. However, for a more comprehensive and streamlined approach, FanRuan's FineDataLink offers an integrated solution, simplifying API interactions while enhancing data integration capabilities. For handling flat files, libraries like pandas and csv are ideal for efficiently reading, writing, and processing data. FineDataLink further elevates this process by providing robust tools for seamless data integration across various sources, ensuring optimal performance and reliability.
Data cleaning involves removing errors and inconsistencies. Use libraries like pandas for this task. Common cleaning tasks include handling missing values, removing duplicates, and correcting data types. Clean data ensures accurate analysis and reliable results.
Data Enrichment
Data enrichmentenhances the dataset by adding valuable information. Use external data sources to enrich the existing data. For instance, add geographical coordinates to addresses using a geocoding API. Enriched data provides deeper insights and improves decision-making.
Data Loading
Destination Options
Data loading involves writing the processed data to a destination. Common destinations include databases, data warehouses, and cloud storage. Databases like MySQL and PostgreSQL store structured data. Data warehouses like Amazon Redshift and Google BigQuery handle large volumes of data. Cloud storage solutions like AWS S3 and Google Cloud Storage store unstructured data.
Writing Data to Destinations
Writing data to destinations requires specific methods and libraries. For databases, use library like psycopg2. This kind of libraries facilitate data insertion and updates. For data warehouses, use library like boto3 for AWS or tool like FineDataLink. These libraries handle data uploads and management. For cloud storage, use libraries like boto3 or google-cloud-storage. These libraries manage file uploads and downloads. Efficiently designing a python data pipeline involves careful selection of data sources, thorough data transformation, and proper data loading. This process ensures that the pipeline operates smoothly and delivers reliable results.
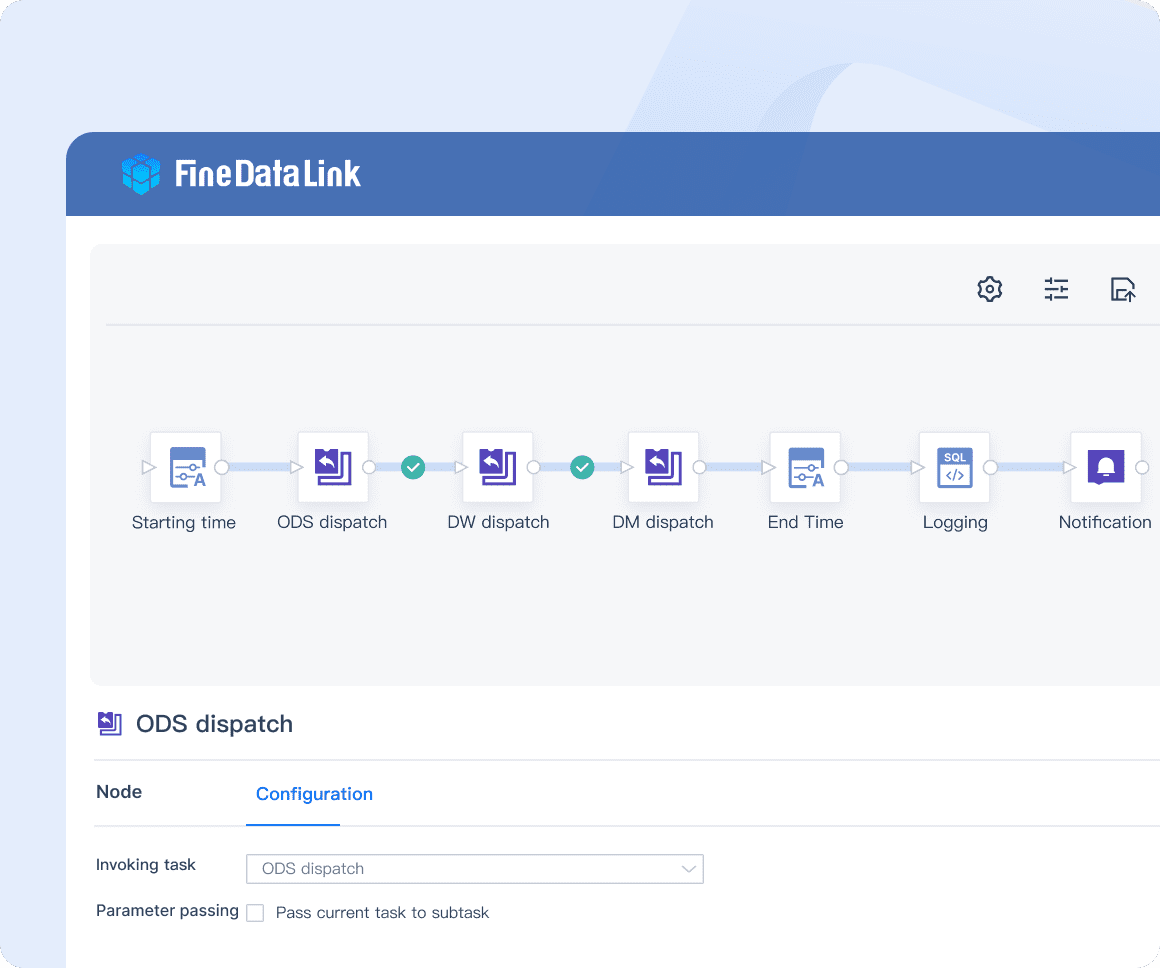
FineDataLink: Efficient Data Warehouse Construction- it can be used for data preprocessing and serves as an ETL tool for building data warehouses.
Organizing code effectively ensures maintainability and readability. Start by creating separate modules for different stages of the pipeline. For instance, create modules for data extraction, transformation, and loading. Use functions to encapsulate specific tasks within each module. This approach promotes modularity and reusability. Adopt a consistent naming convention for functions and variables. Clear and descriptive names enhance code comprehension. Group related functions into classes if necessary.
Key Functions and Methods
Key functions and methods form the backbone of a data pipeline. Implement functions for connecting to data sources. Use libraries like SQLAlchemy for databases and requests for APIs. Develop transformation functions to clean and enrich data. Utilize pandas for efficient data manipulation.
Create functions for loading data into destinations. Employ libraries such as psycopg2 for databases and boto3 for cloud storage. Ensure that each function performs a single task. This design simplifies debugging and testing.
Testing the Pipeline
Unit Tests
Unit tests validate individual functions and methods. Use the framework in Python for this purpose. Write tests for each function to ensure correct behavior. Test edge cases and handle exceptions gracefully. Unit tests provide confidence in the reliability of the code. Structure unit tests in a separate directory. Name test files consistently to identify them easily. Run tests frequently during development. This practice catches errors early and maintains code quality.
Integration Tests
Integration tests verify the interaction between different components of the pipeline. These tests ensure that data flows correctly from extraction to loading. Use real or mock data sources for testing. Validate that the pipeline handles data transformations accurately.
Create integration tests for end-to-end scenarios. Simulate real-world conditions to test the pipeline's robustness. Monitor performance metrics during testing. Optimize the pipeline based on test results to improve efficiency.
Staying informed about new technologies and industry developments enhances the effectiveness of data pipelines. Reading industry publications and blogs, participating in online communities, and attending conferences keep professionals updated. Continuous learning ensures that pipelines leverage the latest advancements.
Monitoring and Maintenance
Monitoring Tools
Logging
Logging serves as a crucial component in monitoring data pipelines. Implement logging to track the flow of data through the pipeline. Use libraries like logging in Python to create detailed logs. These logs help identify issues and understand the pipeline's behavior. Store logs in a centralized location for easy access and analysis. Regularly review logs to detect anomalies or errors.
Alerting
Alerting systems notify stakeholders about pipeline issues. Set up alerts to monitor key performance indicators (KPIs). Use tools like Prometheus and Grafana for real-time monitoring and alerting. Configure alerts for failures, delays, and data quality issues. Ensure that alerts reach the right personnel through email, SMS, or other communication channels. Prompt responses to alerts minimize downtime and maintain pipeline efficiency.
Regular Maintenance
Updating Dependencies
Regularly update dependencies to keep the pipeline secure and efficient. Outdated libraries may contain vulnerabilities or bugs. Use tools like pip to check for updates. Schedule periodic reviews of all dependencies. Test the pipeline after updating to ensure compatibility and stability. Document any changes made during updates for future reference.
Performance Tuning
Performance tuning enhances the efficiency of the data pipeline. Identify bottlenecks by analyzing logs and monitoring metrics. Optimize code to reduce processing time and resource usage. Use profiling tools like cProfile to pinpoint slow functions. Consider scaling resources if the data volume increases. Regular performance tuning ensures that the pipeline remains robust and responsive.
Proper monitoring and maintenance extend the lifespan of a data pipeline. Logging and alerting provide insights into the pipeline's health. Regular updates and performance tuning keep the pipeline running smoothly. These practices ensure reliable and efficient data processing.
Building a Python data pipeline involves several key steps. Start by understanding the components and benefits of data pipelines. Set up the development environment with the necessary tools and libraries. Design the pipeline by defining data sources, performing transformations, and loading data into destinations. Implement the pipeline with well-structured code and thorough testing. Finally, continuous monitoring and maintenance are crucial.
Although these key points could be difficult to conduct, you can make use of FineDataLink to fulfill the complex task.