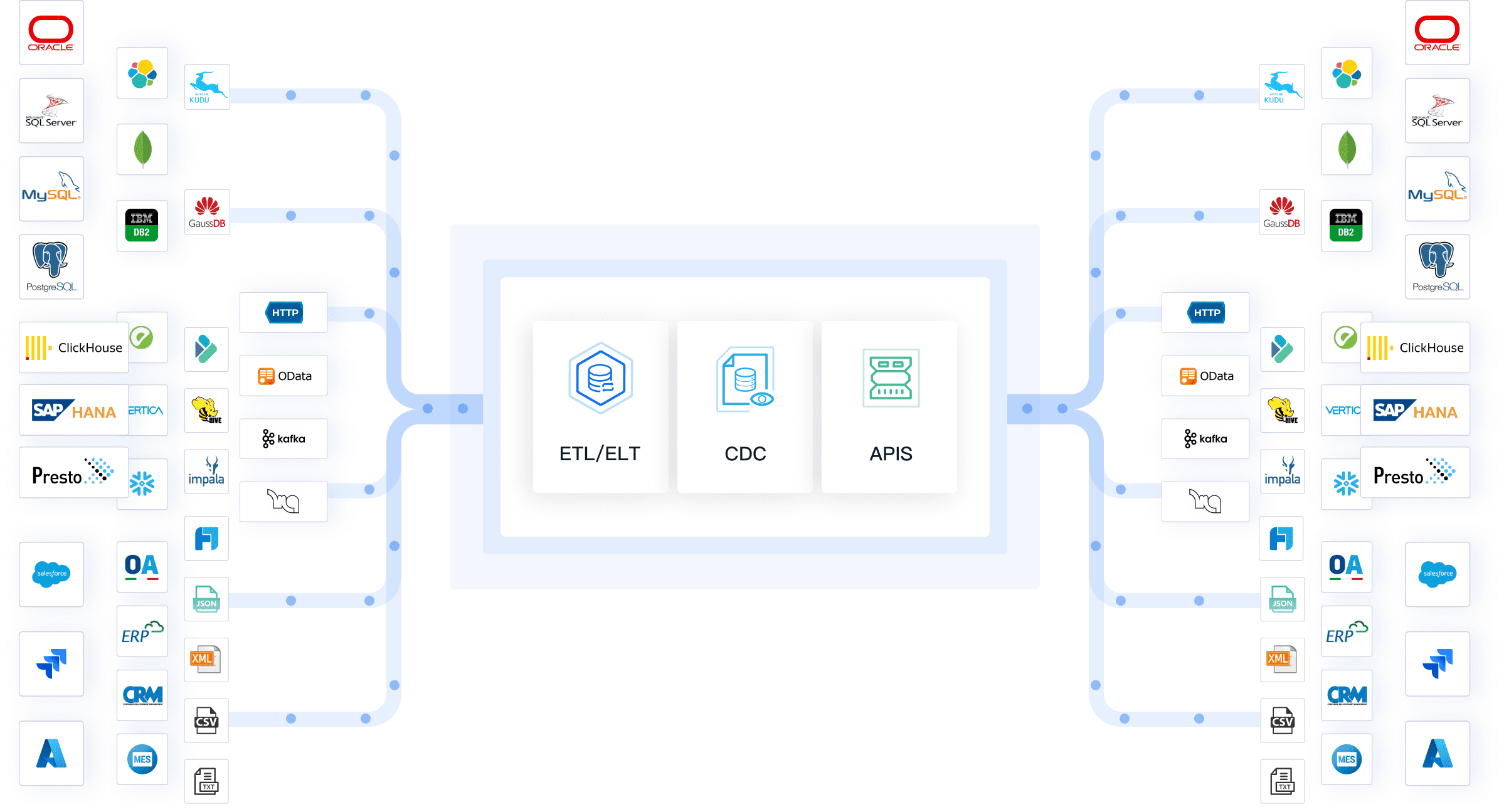
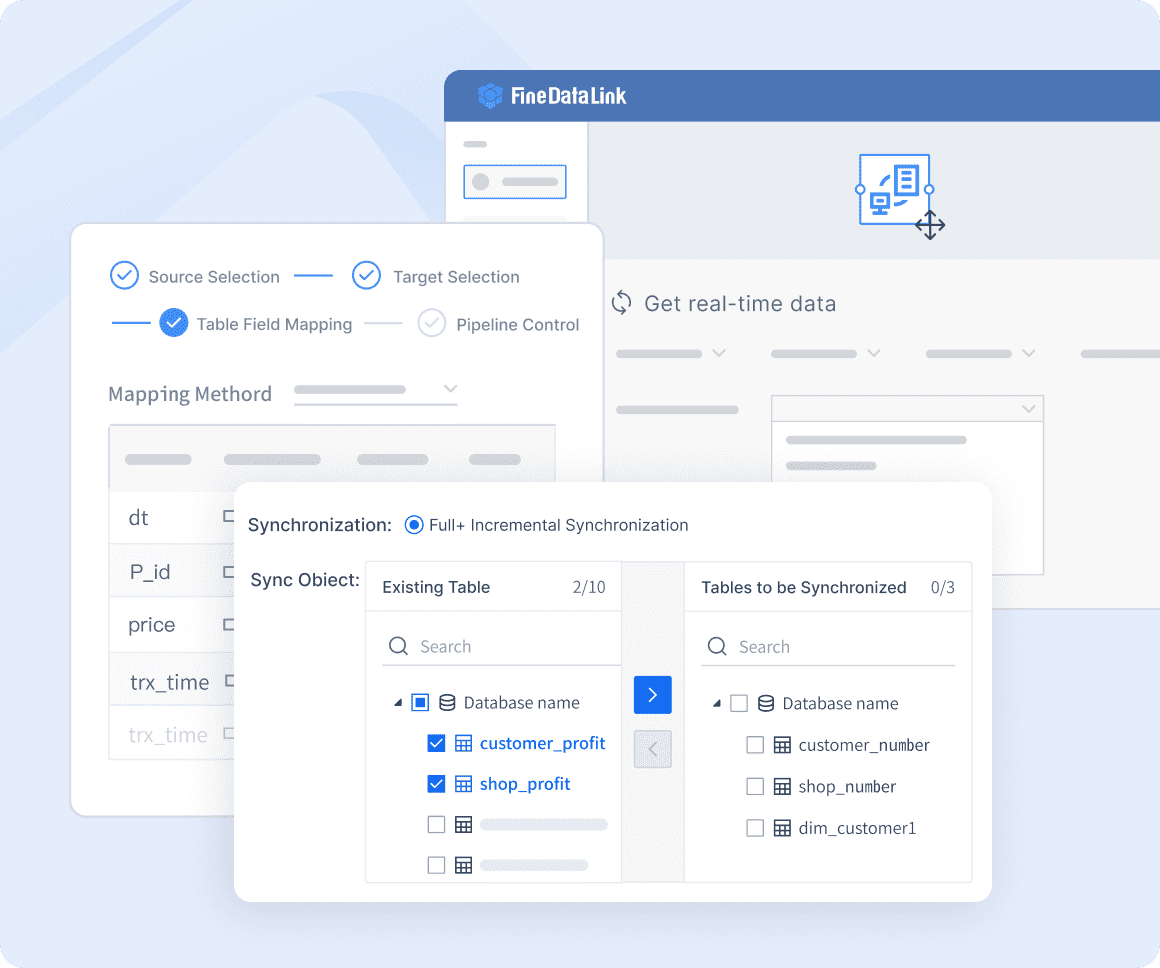
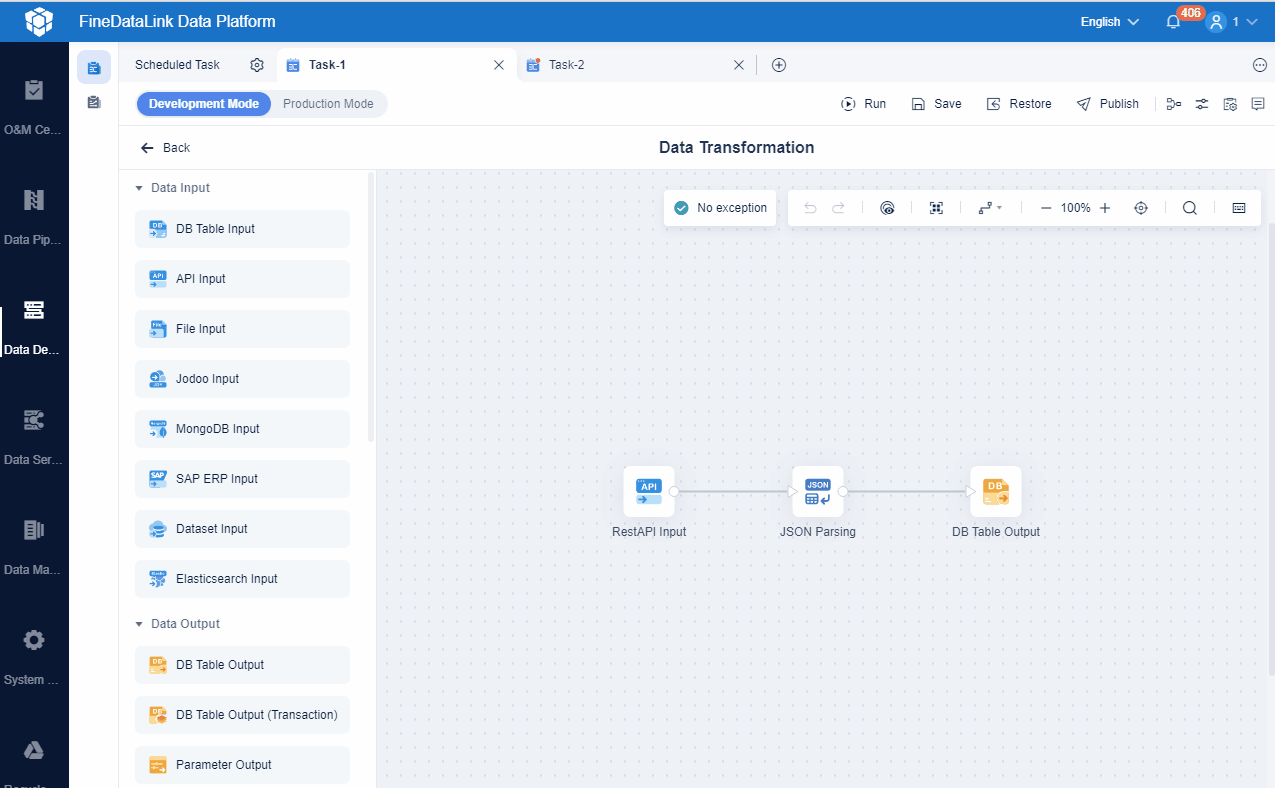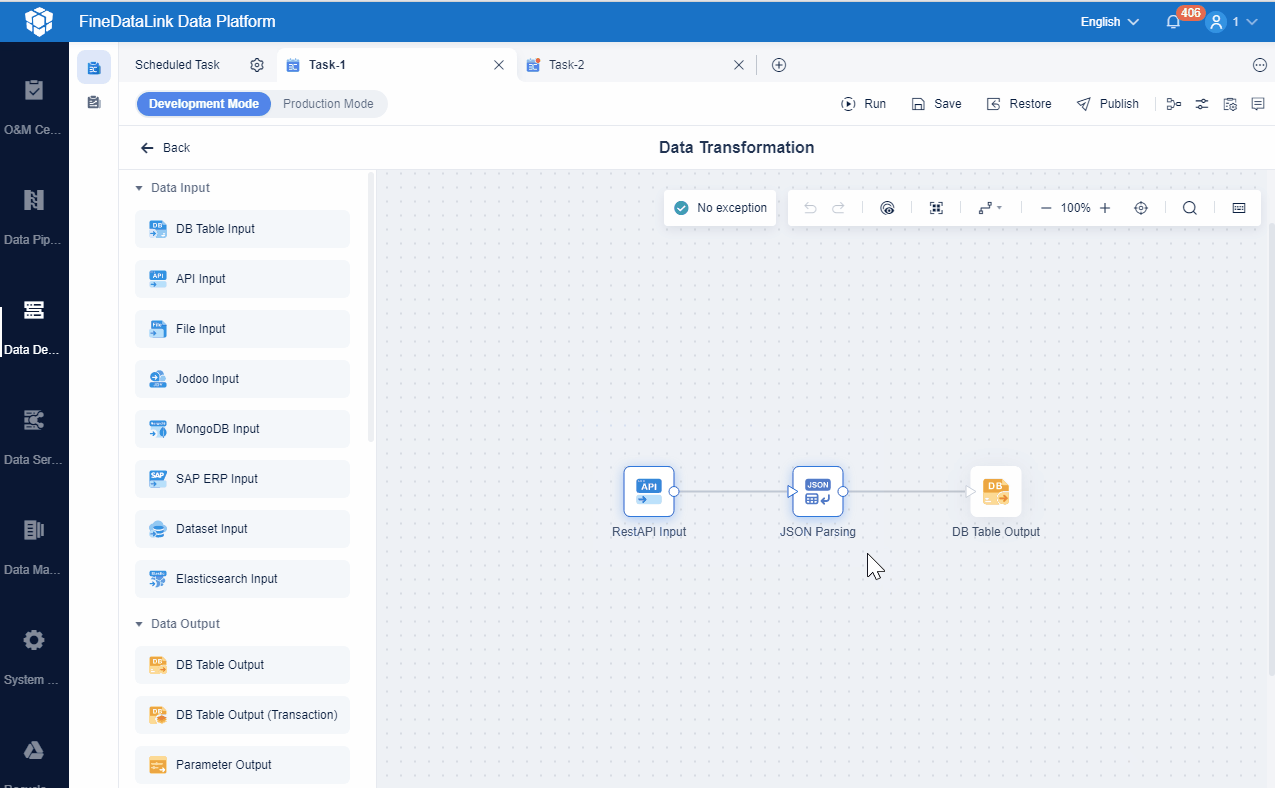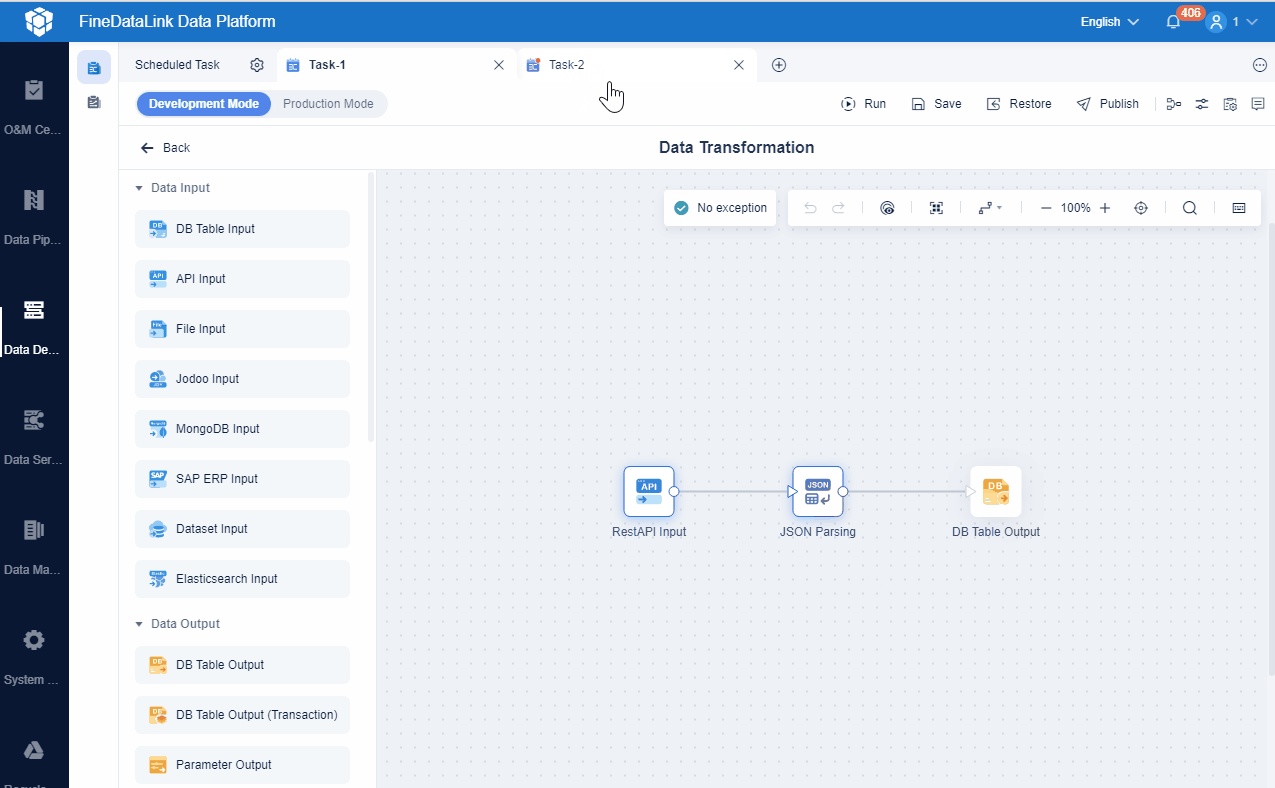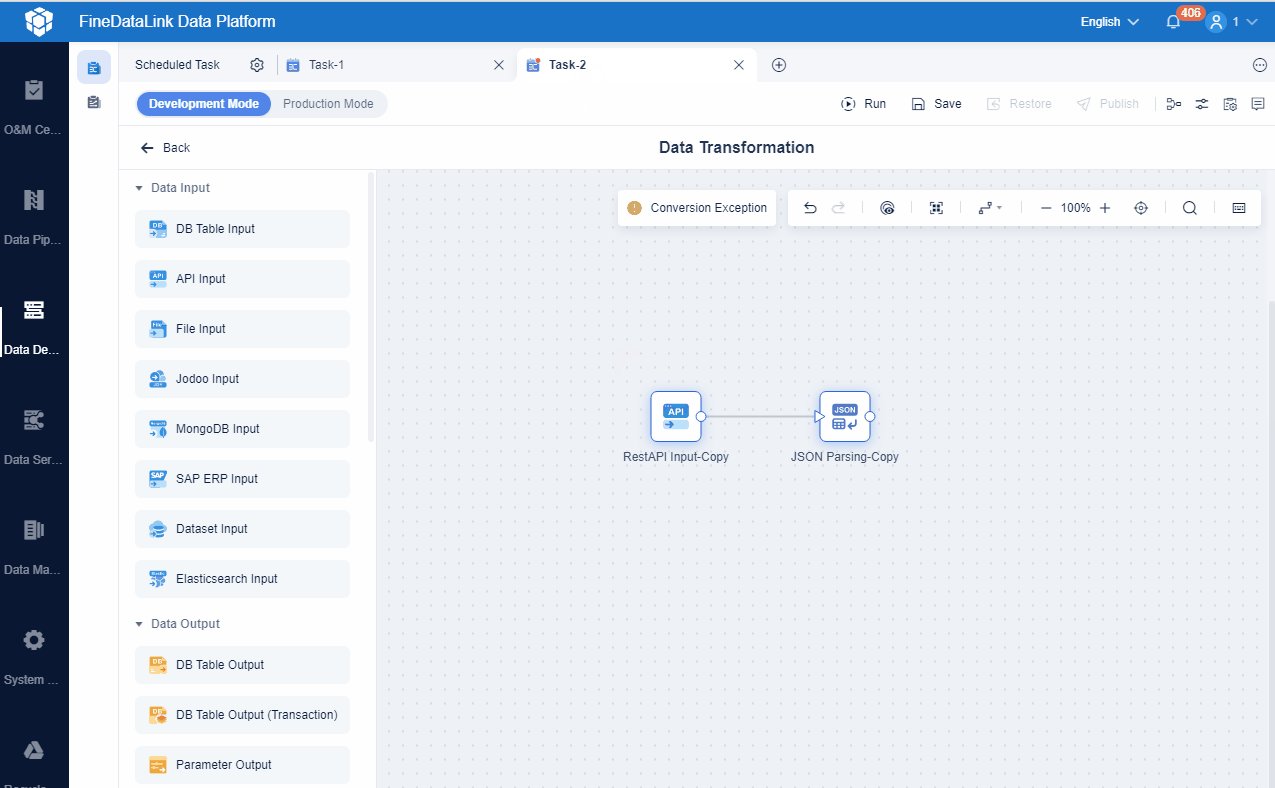
Data pipeline automation refers to the process of automatically moving and transforming data between different systems without manual intervention. You use it to streamline how your organization collects, processes, and delivers information for business needs. This approach helps you overcome common data management challenges, such as:
Data silos
Data security and privacy concerns
Scalability issues
Lack of data governance
Resistance to change
Technological obsolescence
As more companies seek real-time insights, the demand for automated solutions continues to rise. The market for data pipeline tools is projected to reach $48.3 billion by 2030, showing the growing importance of automation in business intelligence and analytics.
Data Pipeline Automation
What Is a Data Pipeline?
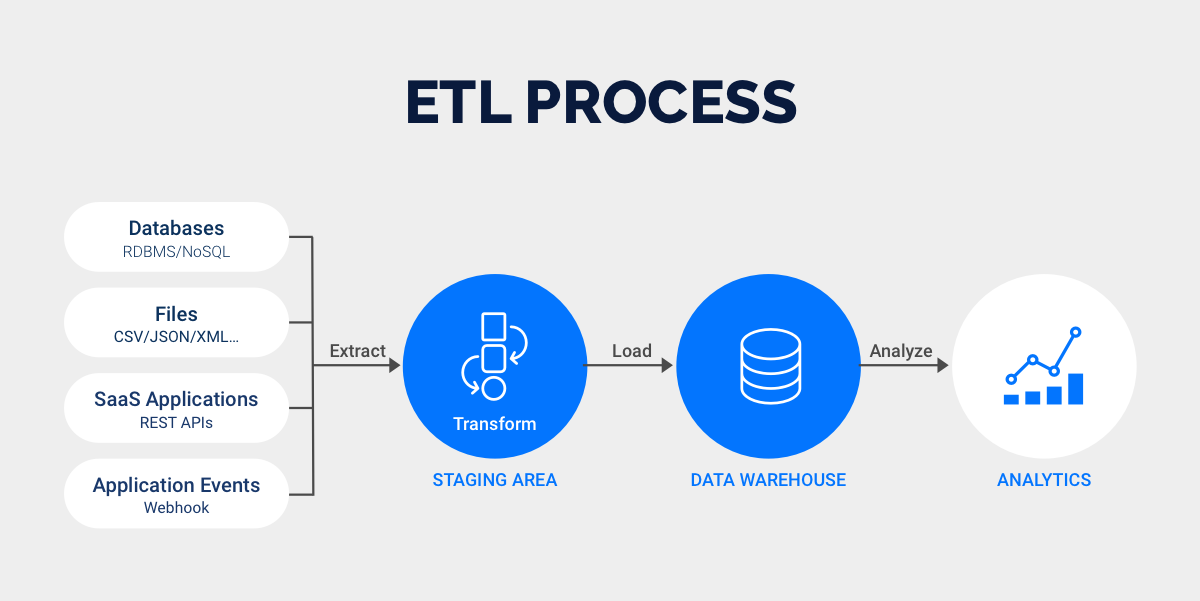
A data pipeline is a set of processes that move data from one system to another. You use it to ingest, process, store, and output large volumes of data efficiently. Data pipelines play a crucial role in enterprise data management by ensuring data quality and integration. This helps you make better decisions and improve operational efficiency. Across industries like e-commerce and finance, data pipelines transform how organizations handle information.
You can break down a typical data pipeline into several key components and stages:
Data Sources: These are the origin points of data, such as databases, logs, and APIs.
Data Ingestion: This stage involves acquiring data from sources using batch processing or real-time streaming.
Data Processing: Here, you clean and transform data to prepare it for analysis or storage.
Transformation: You convert data into a usable format for downstream applications.
Data Storage: Processed data is stored in systems like data warehouses or data lakes.
Orchestration: This manages the flow of data through each stage.
Monitoring and Logging: You continuously oversee the pipeline to identify issues.
Error Handling and Retry Mechanisms: These manage errors and retries in the pipeline.
Security and Compliance: You ensure the pipeline follows data protection regulations.
Each stage works together to deliver accurate and timely data to your business intelligence tools and analytics platforms.
How Automation Works
Data pipeline automationuses technology to move and transform data across systems without manual intervention. When you automate these processes, you increase the speed and accuracy of data transfers. Automation tools handle complex tasks and minimize human errors, which is essential for organizations that manage large volumes of data.
You can schedule data loading based on specific time intervals or triggers. This ensures timely and accurate updates across your systems. Automation also lets you combine different tasks into a single monitored workflow. As a result, you improve data accuracy and availability in real time. You reduce the need for manual intervention, which helps you make faster decisions based on reliable data.
Data pipeline automation supports real-time data processing. For example, in healthcare, automated data pipelines integrate information from electronic health records and wearable devices. This enables real-time patient monitoring and timely responses to health risks. In manufacturing, automated pipelines collect and process sensor data from equipment, helping you detect issues early and optimize production. In retail, automation allows you to track inventory and customer behavior, so you can adjust your strategies quickly.
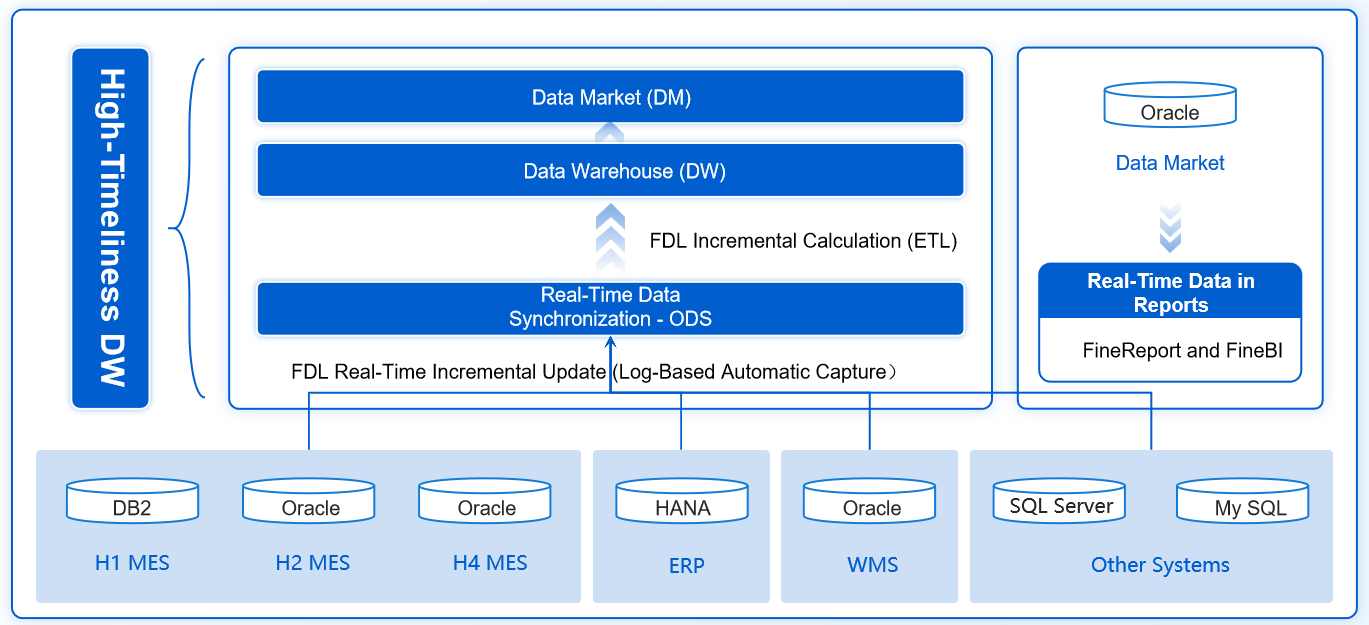
After you understand the value of data pipeline automation, you can explore modern solutions that make these processes even easier. FineDataLink is one such platform. It supports real-time synchronization, ETL/ELT, and API integration, helping you build efficient and reliable data pipelines for your business.
You can unlock many advantages when you automate your data pipelines. Thebenefits of data pipeline automationreach across industries and business sizes. You see improvements in efficiency, data quality, scalability, and cost savings. Let’s explore how these benefits impact your organization.
Efficiency and Speed
Automating your data pipelines increases the speed and accuracy of data movement. You no longer need to rely on manual processes that slow down your workflow. Automated systems handle large volumes of data quickly and consistently. You can process information in real time and deliver insights faster.
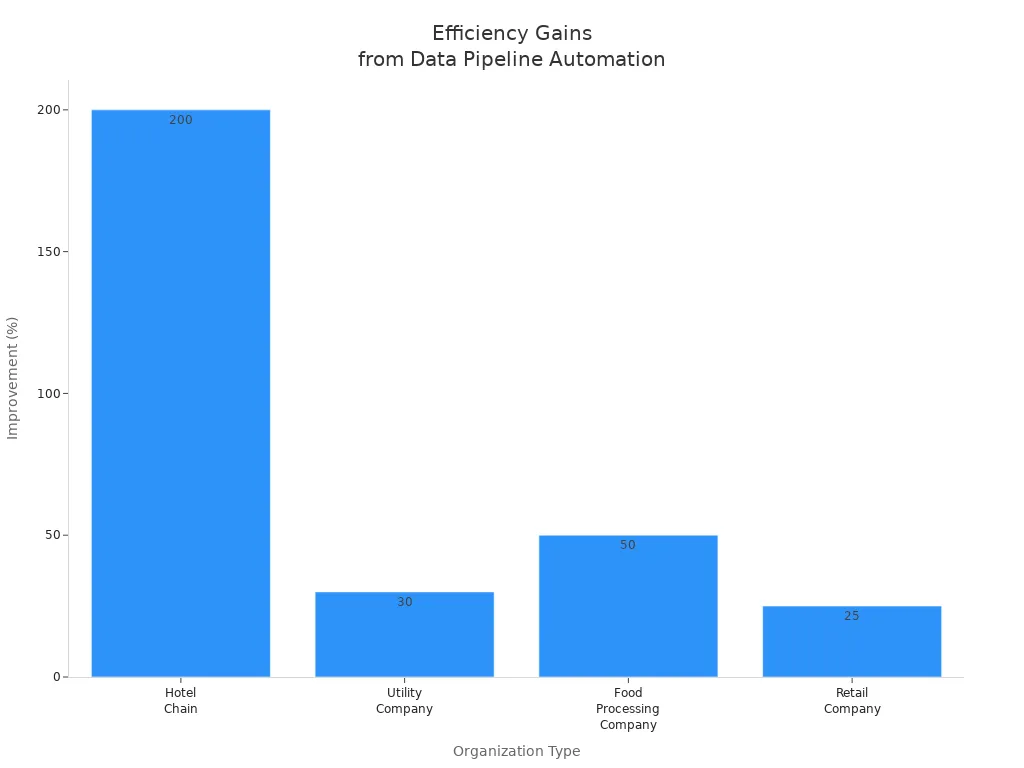
Here is a table showing how different organizations improved efficiency and speed after adopting data pipeline automation:
Organization Type
Improvement Description
Measurable Result
Financial Institution
Achieves 99.9% data accuracy through automation
Reliable reports and compliance
Hotel Chain
Scales data pipeline for increased booking data
200% increase in data handling
Utility Company
Uses dashboards for real-time monitoring
Reduces system downtime by 30%
Food Processing Company
Improves workflow efficiency through automated scheduling
50% increase in efficiency
Retail Company
Implements fault tolerance in data pipeline
Reduces system downtime by 25%
You can see measurable results in throughput, latency, and error rates. Automated pipelines support high throughput and low latency, which means you get timely data for decision-making. You also reduce errors, which improves reliability.
Automating data pipelines reduces the time and effort needed for data-related tasks. You can focus on critical business activities instead of repetitive manual work.
Data Quality and Reliability
You need accurate and reliable data to make informed decisions. Data pipeline automation helps you achieve this by minimizing human errors and ensuring consistent data processing. Automated systems cleanse and validate data as it moves through the pipeline.
Here is a table showing the impact of automation on data quality and reliability:
Organization
Impact on Data Quality and Reliability
Benefits
HomeGoods Plus
Real-time monitoring and automated alerts improved reliability of business insights.
Reduced time-to-insight from days to minutes, enabling faster, data-driven decisions.
General
Automation and orchestration tools streamline data processing, reducing errors and improving efficiency.
Enhanced data governance and compliance through robust frameworks and data lineage tracking.
General
Continuous monitoring helps identify and resolve data quality issues in real-time.
Ensures that data used for analysis is accurate and reliable, supporting informed decisions.
You eliminate common sources of data errors, such as typographical mistakes, inconsistent formatting, duplicate entries, missing fields, and transcription errors. Automation tools like OCR and RPA capture data accurately and validate formats, which ensures your data is complete and consistent.
You benefit from continuous monitoring and automated alerts. These features help you identify and resolve data quality issues before they affect your business.
As your business grows, you need data pipelines that can handle increasing volumes and complexity. Data pipeline automation enables you to scale your operations without sacrificing performance. Automated pipelines adapt to changes in data sources, formats, and business needs.
You avoid the limitations of traditional pipelines, such as high total cost of ownership, data silos, and inconsistent storage practices. Automated solutions provide flexible data modeling and unified storage, which supports growth and collaboration.
Here is a table comparing technical limitations in traditional pipelines versus automated solutions:
Limitation
Description
High TCO (Total Cost of Ownership)
Building, maintaining, and scaling traditional pipelines can be costly. Automated solutions lower these costs.
Data Silos
Traditional pipelines create silos. Automation breaks down barriers for cross-functional collaboration.
Limited Data Modeling
Manual data modeling leads to inefficiencies. Automation integrates modeling into the pipeline.
Inconsistent Data Storage
Specialized pipelines cause inconsistent storage. Automation ensures unified practices.
Lack of Scalability
Fixed sources and logic limit scalability. Automated pipelines adapt to changing data needs.
Governance and Compliance Challenges
Diverse sources complicate governance. Automation applies policies and standards consistently.
Scalable pipelines let you manage large data volumes and complex analytics as your business expands. You maintain effective reporting and analysis, even as your needs change.
Cost Savings
You can achieve significant cost savings by automating your data pipelines. Automation reduces manual effort, lowers error rates, and streamlines maintenance. You spend less on compliance, staffing, and rework.
Here is a table showing cost savings achieved by businesses using automated platforms:
Metric
Description
GDPR Compliance
Automation ensures compliance, avoiding fines up to €20 million or 4% of global revenue.
Insurance companies achieved a 55% cost reduction, translating to $1.93 million in annual savings.
Error Reduction
Significant decreases in error rates lead to reduced rework costs and improved compliance.
Maintenance Effort
Modern ETL automation significantly reduces maintenance efforts, allowing for innovation.
You see direct savings in operational costs and regulatory compliance. Insurance companies have reported a 55% reduction in ongoing costs, saving nearly $2 million each year. Financial institutions have reduced the need for compliance staff by automating regulatory reporting.
Automation frees your employees to focus on strategic tasks. You spend less time updating spreadsheets and more time driving business growth.
FineDataLink's low-code platform and drag-and-drop interface make data integration simple and cost-effective. You can connect over 100 data sources without extensive coding knowledge. Automation of data synchronization ensures your BI reports and dashboards stay up-to-date, saving you time and resources. You transform data during integration, which helps generate accurate reports and reduces the costs associated with correcting errors.
Customer stories highlight the real-world impact of data pipeline automation. For example, BOE Technology Group used automated data integration to reduce inventory costs by 5% and increase operational efficiency by 50%. The company built a unified data warehouse and standardized metrics, which enabled faster, data-driven decisions and improved performance across its factories.
When you adopt data pipeline automation, you gain centralized control, empower your teams, and save hundreds of thousands of dollars. You improve efficiency in data delivery, enhance data availability for self-service reporting, and free employees for more complex tasks.
The benefits of data pipeline automation extend beyond cost savings. You improve business performance metrics such as throughput, latency, error rate, processing time, data accuracy, completeness, consistency, validity, resource utilization, scalability, bottlenecks, and pipeline downtime. These improvements support real-time analytics and agile decision-making, helping your organization stay competitive.
Data Pipeline Automation: How To
Implementation Steps
You can automate data pipelines by following a clear set of steps. Start by assessing your current data workflow. Map out how data moves through your systems and identify bottlenecks. Choose the right data integration tools that fit your needs. Look for compatibility with your existing infrastructure and scalability for future growth. Design your automated workflow by defining transformation rules and error handling. Implement automated extraction and transformation by setting up connections to your data sources and scheduling updates. Optimize and monitor your pipeline by reviewing performance metrics and refining processes.
Implement automated data extraction and transformation.
Optimize and monitor your data pipeline.
When selecting a tool, consider these criteria:
Criteria
Description
Define Your Requirements
Identify essential features like real-time processing and scalability.
Consider Compatibility
Ensure the tool works with your current systems and BI platforms.
Evaluate Costs
Review licensing and maintenance expenses.
Test Before Committing
Use free trials or demos to assess usability.
Support and Community
Check for vendor support and user community resources.
FineDataLink offers a visual interface, real-time synchronization, and API integration. These features make it easier for you to automate data pipelines and streamline data pipeline management.
You should follow best practices to maintain and monitor automated data pipelines. Prioritize data integrity by validating data at every stage. Focus on scalability and flexibility by using platforms that support auto-scaling. Automate monitoring and maintenance with AI-driven systems. Implement end-to-end security using encryption and strict access controls.
Prioritize data integrity.
Focus on scalability and flexibility.
Automate monitoring and maintenance.
Implement end-to-end security.
Establish clear metrics such as throughput and latency. Use real-time monitoring tools to address issues quickly. Conduct periodic audits to ensure compliance and functionality.
Regular monitoring and validation help you maintain reliable and efficient data pipeline management.
Overcoming Challenges
You may face several challenges when you automate data pipelines. Data quality assurance is essential for accurate analytics. Data integration complexity arises from diverse sources and formats. Managing large data volumes requires scalable workflows. Data transformation needs careful planning. Security and privacy must be maintained throughout the process. Pipeline reliability is crucial to prevent disruptions.
Challenge
Description
Data quality assurance
Maintain consistent, high-quality data for accurate analytics.
Data integration complexity
Integrate data from diverse sources and formats.
Data volume and scalability
Optimize workflows to handle increasing data volumes.
Data transformation
Clean and structure raw data for analysis.
Data security and privacy
Ensure compliance and protect sensitive information.
Pipeline reliability
Build robust pipelines to prevent failures and disruptions.
FineDataLink helps you overcome these challenges with its low-code platform, visual workflow design, and support for over 100 data sources. You can automate data pipelines efficiently and improve your data pipeline management for better business outcomes.
Data pipeline automation drives business growth by transforming raw data into actionable insights and enabling faster decisions. You benefit from trusted data, automated checks, and efficient management of dynamic changes.
You gain cost savings and improved customer insights.
Automation streamlines data processing for timely decisions and better governance.
Trend
Description
Real-Time Data Pipelines
Organizations use instant data for operational efficiency.
Access a wealth of case studies, industry insights, and solution guides to accelerate digital transformation.
FAQ
What is data pipeline automation?
Data pipeline automation means you use technology to move, transform, and manage data between systems without manual work. You set up rules and workflows so your data flows automatically, which saves time and reduces errors.
Why should you automate your data pipelines?
You should automate your data pipelines to improve speed, accuracy, and reliability. Automation helps you process large data volumes quickly. You reduce manual errors and free up your team for more valuable tasks.
How does data pipeline automation improve data quality?
Data pipeline automation enforces consistent rules for data cleaning and validation. You catch errors early and ensure your data stays accurate and reliable. Automated monitoring alerts you to issues before they affect your business.
What challenges can you face with data pipeline automation?
You may face challenges like integrating data from many sources, handling complex formats, and ensuring security. You need to plan for scalability and monitor your pipelines to keep them running smoothly.
How can FineDataLink help with data pipeline automation?
FineDataLink offers a low-code platform for data pipeline automation. You can connect over 100 data sources, use drag-and-drop tools, and set up real-time synchronization. This makes building and managing automated pipelines much easier.