You want to find the best ELT tools for seamless data ingestion in 2025. The right platform helps you move, transform, and manage data from many sources with speed and accuracy. Here are the 11 best ELT tools for seamless data ingestion:
FineDataLink
Estuary
AWS Glue
Hevo Data
Apache NiFi
Stitch
Talend
Fivetran
Airbyte
Informatica PowerCenter
Matillion
Your choice impacts how well you keep data reliable and efficient. Features like real-time and batch ingestion, built-in transformation, and support for many data sources make a big difference. Recent industry reports show that organizations using structured automation for data workflows reach nearly 70% adoption by 2025. See the latest statistics below:
Statistic Description
Value
Cloud deployment market share
66.8%
Organizations adopting multi-cloud strategies
89%
Adoption rate of structured automation by 2025
~70%
This guide gives you practical insights whether you work in a technical or non-technical role.
What Are ELT Tools and Data Ingestion
ELT Tools Explained
You often hear about elt tools when you work with modern data architectures. These tools help you move and transform data from many sources. ELT stands for Extract, Load, Transform. You first extract data from places like databases, SaaS platforms, or cloud storage. Next, you load raw data into a data warehouse. Finally, you transform data inside the warehouse using its powerful compute resources.
The shift from ETL to ELT happened because cloud data warehouses can handle large datasets quickly. You get faster processing and more flexible data handling. ELT tools let you keep raw data, so you can change how you transform it later. This approach supports agile data pipelines and helps you manage both structured and unstructured data.
Here is a simple breakdown of the ELT process:
Phase
Description
Extract
You pull data from different source systems, including NoSQL and SaaS apps.
Load
You load raw data directly into the data warehouse.
Transform
You use the warehouse’s compute power to transform data for analysis.
ELT tools differ from traditional ETL tools in several ways:
ELT uses the data warehouse’s own compute resources.
ELT supports flexible pipelines and works well with semi-structured or raw data.
Why Data Ingestion Matters
Data ingestion is the process of moving data from its source into a platform for analysis. You need reliable data ingestion to make sure your data is accurate and ready for business intelligence. Data ingestion tools automate this process, saving you time and reducing errors.
You face many challenges with data ingestion. Manual processes slow you down and can cause mistakes. Changes in data structure can break your pipelines. Job failures may lead to data loss or stale data. Duplicate data can make management harder. Security is also important, since data passes through many stages.
Data ingestion supports your business in many ways:
Real-time data ingestion gives you timely insights for quick decisions.
Scalability lets you handle more data as your business grows.
Data quality and consistency keep your analytics reliable.
Enhanced analytics help you make smarter choices.
Compliance and governance protect your data and meet regulations.
You need strong data ingestion tools to build a solid foundation for analytics and business intelligence. When you choose the right tools, you unlock the full value of your data.
Key Criteria for Data Ingestion Tools
When you choose elt tools for your business, you need to focus on several important criteria. These factors help you build strong data pipelines and ensure your data ingestion workflows run smoothly.
Scalability and Integration
Scalability means your data ingestion tools can handle more data as your business grows. You want tools that keep performance high, even when data volumes increase. Integration is also key. Your tools should connect with many data sources and work well with your current systems. This makes your data integration process more efficient and effective.
Aspect
Explanation
Scalability
Tools must handle increasing data volumes and velocities without performance degradation.
Integration capabilities
Compatibility with existing data infrastructure enhances efficiency and effectiveness in processing.
You should also look for features like user-friendly interfaces, support for different data formats, and strong interoperability. These features make it easier to manage data from many sources.
Automation and Workflow
Automation helps you save time and reduce mistakes. When you automate data ingestion, you make your data ingestion workflows more reliable and consistent. Large organizations often use automation to handle big data loads and keep processes running smoothly.
Reduces time and effort, ensures consistency and accuracy, handles large volumes, and improves reliability.
Automate where possible. This lets your team focus on more important tasks and improves the overall quality of your data.
Security and Cost
Security protects your data and keeps your business compliant with regulations. Look for elt tools that offer features like role-based access, encryption, and support for standards such as GDPR or HIPAA. You also want to control costs. Some data ingestion tools use fixed-fee pricing, which helps you plan your budget. Others use usage-based models, which can change based on how much data you process.
Security Feature
Description
Regulatory compliance
Awareness of standards like GDPR, SOC2, HIPAA, etc.
Owning your data
Ensuring the provider does not retain data longer than necessary.
Roles with varying levels of access
Availability of different access roles from administrator to read-only.
Column blocking and hashing
Ability to encrypt or omit personally identifiable information (PII) from synced tables.
You should consider the total cost of ownership, including setup, training, and maintenance. Choosing the right pricing model helps you balance your budget with your operational needs.
Tip: Always match your data transformation capabilities and real-time data ingestion needs with the features offered by your chosen data integration tools.
Top 11 ELT Tools for Data Ingestion Platforms in 2025
Choosing the right ELT tools for your organization can transform how you manage data ingestion and build automated data pipelines. You need data ingestion platforms that offer robust data transformation capabilities, support real-time data ingestion, and simplify data integration and migration. Here are the top 11 data integration platforms you should consider for 2025.
1. FineDataLink by FanRuan
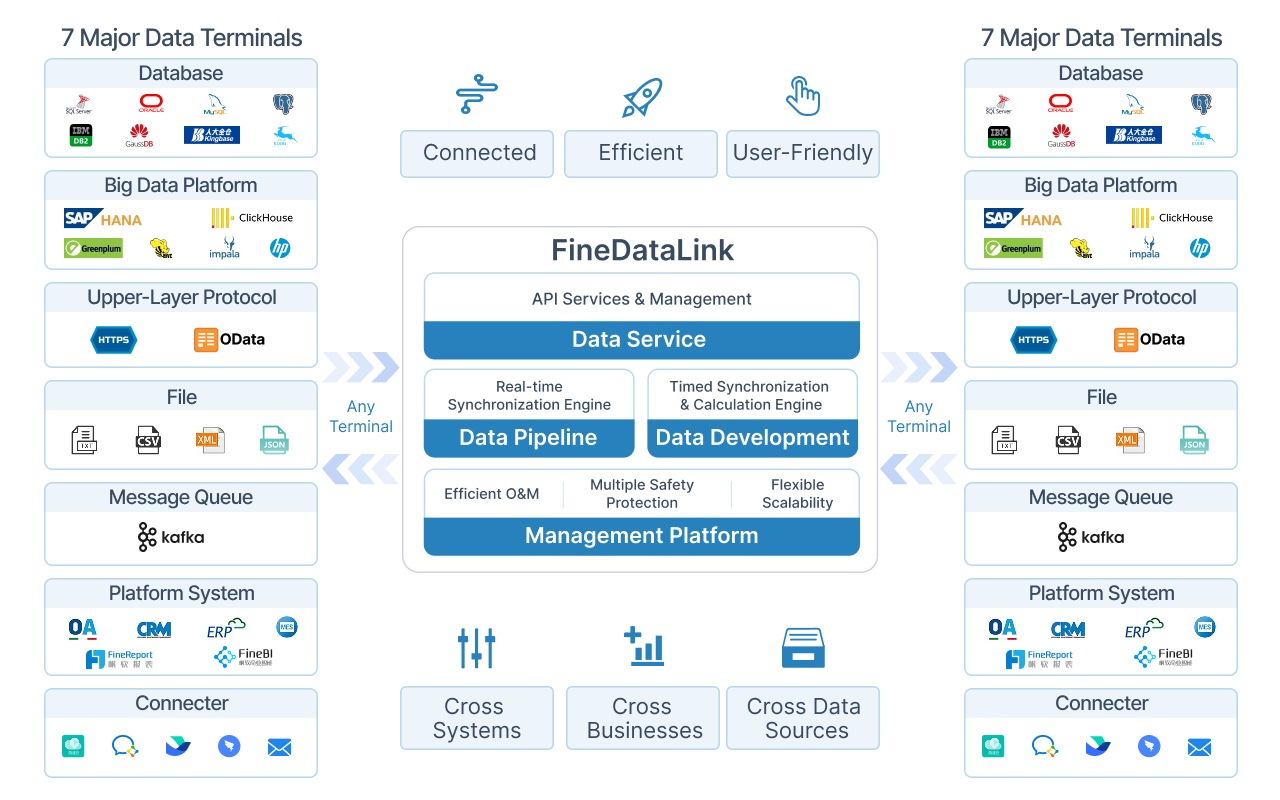
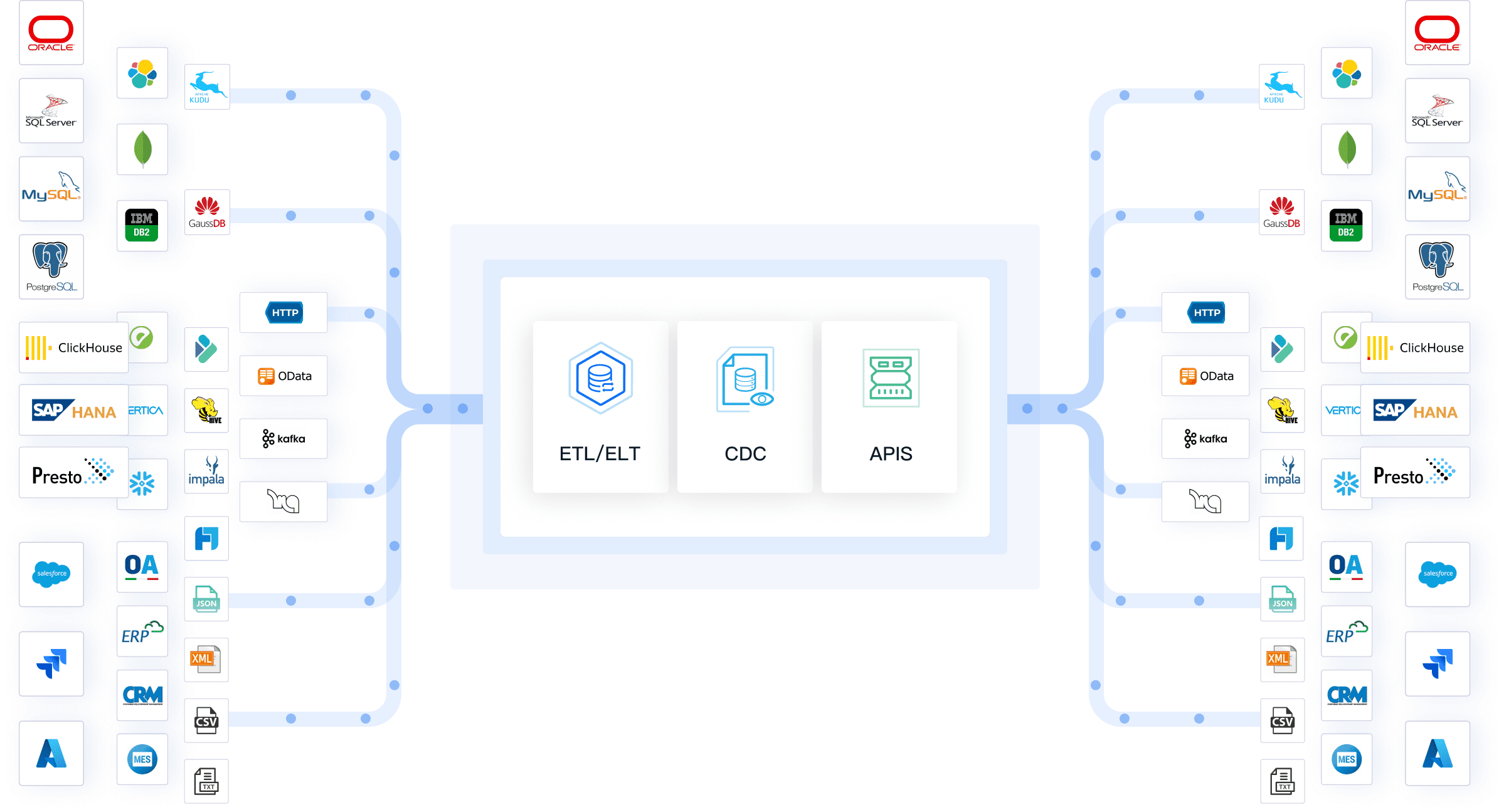
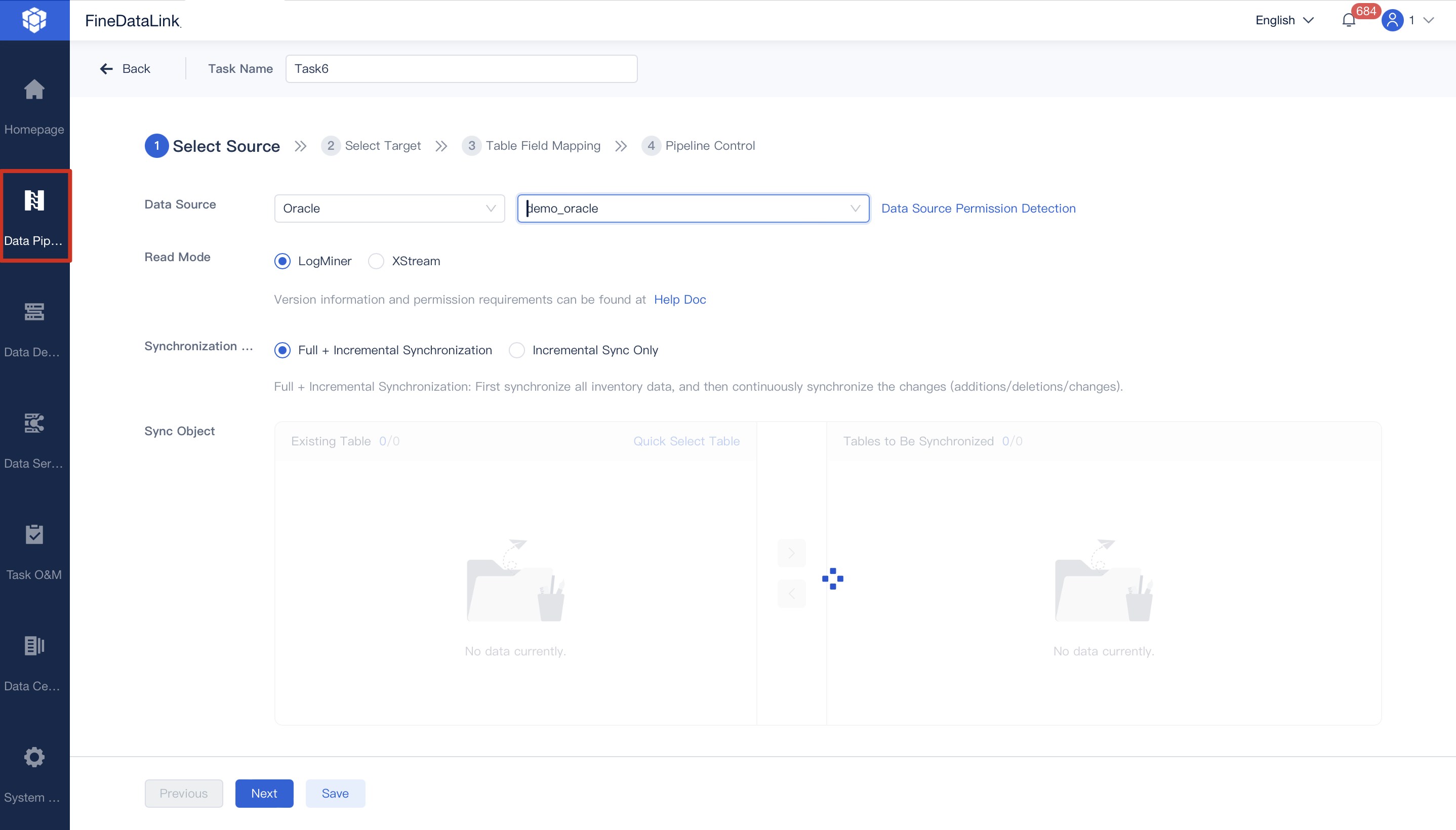
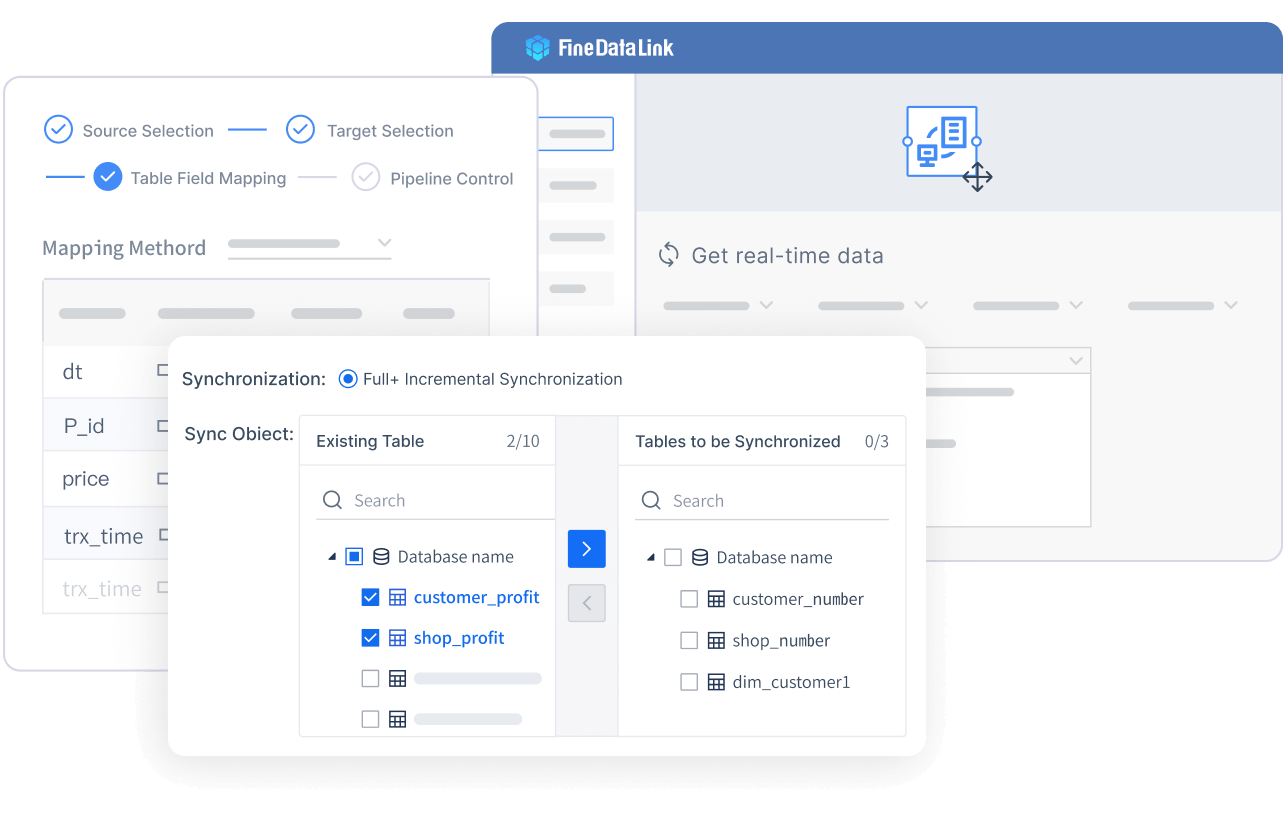
FineDataLink stands out as a modern data integration platform designed for seamless data ingestion across multiple sources. You can use it to synchronize data in real time, build efficient data pipelines, and manage both batch data ingestion and real-time data ingestion. FineDataLink supports over 100 data sources, making data source compatibility a key strength. Its visual interface and low-code approach improve ease of integration, so you can deploy and operate with minimal effort.
Supports relational, non-relational, interface, and file databases for flexible data ingestion.
Non-intrusive real-time synchronization
Synchronizes data across tables or entire databases with minimal latency.
Data service construction at low cost
Builds enterprise-level data assets using APIs for interconnection and sharing.
Efficient intelligent operation and maintenance
Flexible scheduling and real-time monitoring reduce operational workload.
High extensibility
Built-in Spark SQL allows you to call scripts for advanced data transformation.
Efficient data development
Dual-core engine supports both ELT and ETL processes for customized solutions.
Five data synchronization methods
Timestamp, trigger, full-table comparison, full-table increment, and log parsing.
You benefit from FineDataLink’s ability to handle real-time data integration, build scalable data pipeline architecture, and support data integration and migration projects. Its cost-effective design and strong data transformation tools make it a top choice for organizations seeking high-quality data integration platforms.
Tip: FineDataLink’s visual interface and low-code features help you reduce manual work and speed up deployment, especially when you need real-time data ingestion.
2.Estuary
Estuary is a cloud-native data integration platform that focuses on real-time data ingestion and streaming. You can use Estuary to connect various data sources and destinations, including cloud data warehouses. Users report that the interface feels intuitive after some initial learning. Estuary’s documentation sometimes challenges users, especially with complex connectors, but most resolve issues quickly.
Databricks excels in machine learning but may have SQL quirks under heavy load.
Redshift and Fabric sometimes face memory and reliability issues.
Estuary’s strength lies in its ability to deliver real-time processing and flexible data pipelines for modern data ingestion workflows.
3. AWS Glue
AWS Glue is a fully managed data integration platform that automates data ingestion, transformation, and loading. You can use AWS Glue to connect with a wide range of AWS services, making it ideal for organizations already using Amazon’s ecosystem.
AWS Glue supports over 70 data sources, including databases and streaming services. You can automate extraction, transformation, and loading directly into S3. Intelligent crawlers update metadata in the AWS Glue Data Catalog, simplifying data pipeline architecture and enhancing ease of integration.
4.Hevo Data
Hevo Data is a no-code data integration platform that simplifies data ingestion for both technical and non-technical users. You can set up automated data pipelines quickly and manage real-time data ingestion with minimal effort.
Ingest data without writing code, making it accessible for everyone.
Automated features
Real-time data ingestion and transformation happen automatically.
Fault-tolerant architecture
Secure and consistent data handling with zero data loss.
Schema management
Automatically detects and maps incoming data schemas.
Data transformation
Offers both code and no-code options for complex transformations.
Quick setup
Interactive UI allows for fast onboarding.
Scalability
Handles millions of records per minute as data volume grows.
Live support
24/7 customer support enhances user experience.
Hevo Data’s automated data pipelines and fault-tolerant design ensure your data ingestion workflows remain reliable and scalable.
5. Apache NiFi
Apache NiFi is an open-source data integration platform known for its scalability and security. You can use NiFi to build complex data pipelines and manage both batch and real-time data ingestion.
All nodes operate as peers, eliminating single points of failure.
Load balancing
Distributes data processing across nodes for better performance.
Horizontal scaling
Add nodes to manage increasing data volumes.
NiFi supports multiple authentication methods, including LDAP, Kerberos, OpenID Connect, and SAML.
You get fine-grained access control with role-based policies.
Data encryption protects information in transit and at rest.
Audit logging provides traceability for security events.
Apache NiFi’s robust security and scalability features make it a strong choice for enterprise-level data ingestion platforms.
6. Stitch
Stitch is a cloud-based data integration platform that focuses on simplicity and ease of integration. You can use Stitch to connect a wide range of data sources with pre-built connectors and automate data extraction based on your schedule.
You can integrate SaaS applications, websites, and databases without manual coding.
Stitch operates on a consumption-based pricing model, which may lead to unpredictable costs as your data volume grows.
Stitch’s automated data pipelines and user-friendly interface help you streamline data ingestion workflows, especially when you need quick integration with multiple sources.
7. Talend
Talend is a flexible data integration platform that supports both open-source and enterprise deployments. You can synchronize data between systems, execute ETL and ELT processes, and move data quickly for real-time decision-making.
Talend’s open-source environment supports data planning, integration, processing, and cloud storage. You benefit from powerful data integration capabilities and faster responses to business requirements. Talend simplifies big data integration jobs, reducing development time compared to manual coding.
Talend provides strong data transformation tools for both simple and complex jobs.
You can use Talend to build scalable data pipelines and support real-time data ingestion.
Talend’s flexibility and open-source options make it a popular choice among organizations seeking customizable data integration platforms.
8. Fivetran
Fivetran is a fully managed data integration platform that automates data ingestion and transformation. You can use Fivetran to connect with over 700 prebuilt connectors, ensuring reliable coverage for various data needs.
Eliminates manual work, letting you focus on insights.
Prebuilt Connectors
Over 700 tested connectors for diverse data sources.
Built-in Transformations
Supports dbt transformations and reverse ETL.
Real-time Synchronization
Keeps data up-to-date for timely insights.
Automated Schema Drift Handling
Maintains data integrity and reduces maintenance.
Enterprise-grade Security
Ensures compliance and security for sensitive data.
Fully Managed Platform
Simplifies data ingestion, enhancing scalability and reliability.
Fivetran’s automated data pipelines and real-time data ingestion features help you build scalable data pipeline architecture with minimal effort.
9. Airbyte
Airbyte is an open-source data integration platform that offers cost-effective data ingestion and extensive connector support. You can modify and extend Airbyte to meet your specific needs, making it a flexible choice for many organizations.
Airbyte provides over 600 pre-built connectors for various data sources and destinations.
The intuitive interface simplifies setup and management of data pipelines.
Community support helps you resolve issues and collaborate on new features.
Airbyte’s open-source model eliminates expensive licensing fees and gives you control over your data integration platform.
10. Informatica PowerCenter
Informatica PowerCenter is a comprehensive data integration platform designed for large enterprises with complex data ingestion needs. You can use PowerCenter to extract, transform, and load data from multiple sources, apply business rules, and ensure data quality.
Simplifies integration of complex data structures with reusable transformations and workflows.
Data Governance and Quality
Tools for metadata management, data lineage tracking, and automated quality checks.
Hybrid and Multi-Cloud Support
Integrates data from on-premises and cloud platforms.
PowerCenter supports both batch and real-time processing.
You can customize workflows and build intricate data pipelines for your organization.
Data governance features help you maintain high data quality and compliance.
Informatica PowerCenter’s deep functionality and customization options make it ideal for enterprises with dedicated technical teams.
11. Matillion
Matillion is a cloud-native data integration platform built for scalability and flexibility. You can use Matillion to orchestrate ETL workflows, transform data, and integrate with various cloud data warehouses.
Matillion’s cloud-native architecture and data transformation capabilities make it a strong choice for organizations seeking scalable data integration platforms.
Note: When you select data ingestion platforms, always consider your data volume, data source compatibility, and the need for real-time data ingestion. The right data integration platform will help you build efficient data pipelines and unlock the full value of your data.
Comparing Data Ingestion Tools
Feature Comparison Table
You need to compare elt tools carefully before you choose the right one for your business. Each platform offers different features, connector counts, and deployment options. Some tools focus on open-source flexibility, while others provide fully managed services. The table below helps you see the main differences at a glance.
You see that Airbyte and Fivetran lead in connector support. Matillion and Hevo Data offer user-friendly interfaces and strong transformation features. AWS Glue and Informatica focus on integration and compliance for enterprise needs.
Best Use Cases
You should match data ingestion tools to your business needs. For example, if you work in retail or eCommerce, you can use automated data pipelines to build customer 360 analytics. In banking, you need real-time data integration for fraud detection. Healthcare organizations use data ingestion workflows to combine patient data from many sources. Cloud data warehouses help you centralize and analyze large volumes of data for AI and machine learning.
Use Case
Industry
ELT Solution
Key Benefits
Customer 360 analytics & personalization
Retail, eCommerce
Extract data from all channels, load into cloud warehouse, transform for unified profiles
Load raw sensor data into scalable platforms, transform for predictive analytics
Extended equipment life, reduced downtime
Real-time Analytics & Operational Dashboards
All Industries
Continuous data loading with frequent transformations for live metrics
Faster decision-making, dynamic responses
You can see that the right tool helps you solve industry-specific problems and scale your data pipelines as your business grows.
Choosing the Right Data Ingestion Platform
Assess Your Data Needs
You should start by understanding your data environment. List the types of data you collect, such as structured, semi-structured, or unstructured. Think about where your data comes from—databases, cloud apps, IoT devices, or files. Estimate how much data you handle each day and how fast you need to process it. Some businesses need real-time data, while others work with batch updates.
You should also consider your team’s technical skills. If you want a user-friendly platform, FineDataLink offers a visual, low-code interface that helps both technical and non-technical users manage data easily.
After you know your data needs, compare the features of different platforms. Make sure the tool supports all your data sources and can handle your data volume. Look for built-in integrations, automation, and strong data transformation options.
Use this checklist:
Check if the tool connects to your current data sources.
See if it supports both batch and real-time data ingestion.
Review automation features for scheduling and monitoring.
Confirm that the platform scales as your data grows.
Evaluate the interface for ease of use.
FineDataLink stands out with over 100 connectors, real-time synchronization, and flexible scheduling. Its drag-and-drop interface makes data pipeline setup simple, even for beginners.
You need to balance features with your budget. Pricing models can vary. Some platforms charge by data volume, others by connector count or compute time. Predictable pricing helps you plan costs as your data grows.
Support is also important. Reliable customer support can save you time and reduce downtime. Some platforms offer premium support for an extra fee, while others include it. FineDataLink provides detailed documentation, step-by-step guides, and responsive support, making it easier for you to solve problems quickly.
Tip: Always choose a platform that matches your current needs and can grow with your business. A good data ingestion tool will help you unlock the full value of your data.
You need to choose elt tools that match your business goals. The right platform helps you manage data ingestion, automate data pipelines, and improve data processing speed. You can scale your data workflows by using tools that support many data sources and formats. Automation reduces manual work and lets you focus on data-driven decision-making. Consider how each tool handles data integration and cost. Try shortlisted platforms and talk with your team to find the best fit for your data needs.
Access a wealth of case studies, industry insights, and solution guides to accelerate digital transformation.
FAQ
What is the difference between ELT tools and ETL tools?
You use ELT tools to extract and load data into cloud data warehouses before transforming it. ETL tools transform data before loading. ELT tools work well with modern data pipeline architecture and support real-time processing.
How do data ingestion tools help with real-time data integration?
You use data ingestion tools to automate real-time data ingestion. These tools move data from multiple sources into your data integration platform. Real-time data integration gives you up-to-date insights for data-driven decision-making.
Why should you consider data source compatibility when choosing data ingestion platforms?
You need data source compatibility to connect all your systems. Data ingestion platforms with broad compatibility let you build automated data pipelines. This ensures ease of integration and supports both batch data ingestion and real-time processing.
How do data transformation capabilities impact data ingestion workflows?
You rely on strong data transformation capabilities to clean, enrich, and prepare data for analysis. These features in data ingestion workflows help you create reliable data pipelines and improve the quality of your analytics.
What are the benefits of using a data integration platform for data integration and migration?
You benefit from a data integration platform by simplifying data integration and migration. These platforms support data transformation tools, automate data ingestion, and help you manage complex data pipelines across different environments.