Data engineering solutions collect, clean, transform, and deliver raw data from multiple sources into reliable, ready-to-use information that powers analytics and business decisions.You want to accelerate your data-driven future with the best data engineering solutions in 2025. Here are the top 10:
Each of these data engineering solutions excels in areas like scalability, real-time integration, automation, and cloud-native architecture. Modern teams often face challenges such as large-scale data ingestion, schema drift, and operational chaos. These data engineering solutions help you unify data, automate pipelines, and ensure high data quality.
You can use this guide to compare features and select the right data engineering solutions for your cloud migration services, cloud-based data platform, and cloud data solutions. Rely on robust data integration platforms and data migration services to unlock data-driven insights and power data analytics and visualization for your future.
Understanding Data Engineering Solutions
What Are Data Engineering Solutions?
You interact with data every day, but raw data alone cannot help you make decisions. Data engineering solutions help you collect, organize, and prepare this data so you can use it effectively. Industry experts define data engineering as the process of designing and building systems that collect and analyze raw data from many sources and formats. These solutions turn messy data into structured information, which supports your business goals and sparks innovation.
Data engineering solutions usually include several main functions:
Data ingestion: You gather data from different sources and bring it into one place.
Data transformation: You clean, adjust, and prepare the data so it fits your needs.
Data serving: You deliver the ready-to-use data to users through dashboards, reports, or other tools.
Data quality and monitoring play a big role in data engineering. You need to make sure the data you use is accurate and reliable. Data observability helps you track how your data pipelines perform, so you can fix problems quickly.
You will work with different types of data, such as structured data in databases, unstructured data like images, and semi-structured data that mixes both. Each type needs a special approach for processing and analysis. As part of the modern data stack, data engineering connects all these pieces, making your data useful and accessible.
Why Modern Teams Need Data Engineering
Modern teams rely on data engineering to build the foundation for data-driven decisions. You need strong systems to collect, store, and process data before you can analyze it. Data engineering creates data warehouses and real-time analytics platforms that give you high-quality data for your business intelligence tools. This setup lets you spot trends, make smart choices, and boost productivity.
You see the impact of data engineering in many industries:
A retail team uses the modern data stack to segment customers and create targeted marketing, which increases sales.
In manufacturing, teams use cloud data engineering to find and fix inefficiencies, saving money and time.
Telecom companies improve customer satisfaction by analyzing feedback and network data.
Financial teams use data engineering to meet rules like anti-money laundering and Know Your Customer.
Cloud data engineering and the modern data stack help you scale your solutions and connect with cloud-based tools. These technologies make it easier for your team to handle large amounts of data and adapt to new challenges.
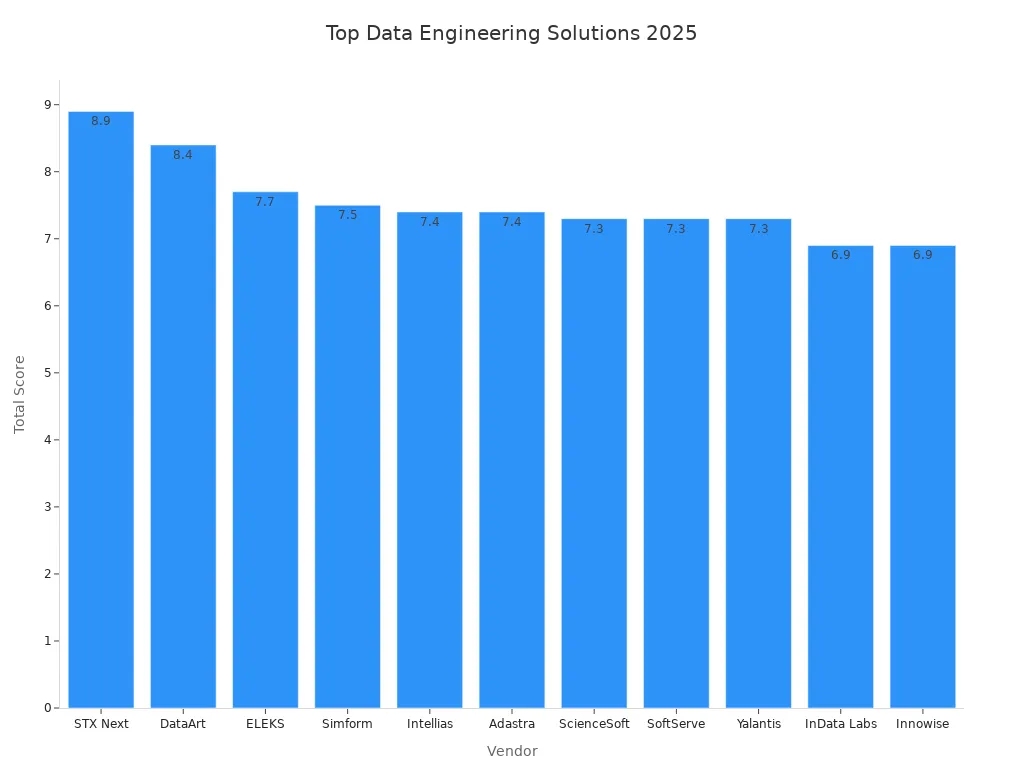
Top 10 Data Engineering Solutions for 2025
You want to choose the best data engineering tools for your team. The market offers many options, but only a few stand out for their innovation, scalability, and user experience. Here is a quick look at how industry analysts rank the top vendors for 2025:
1.FineDataLink by FanRuan
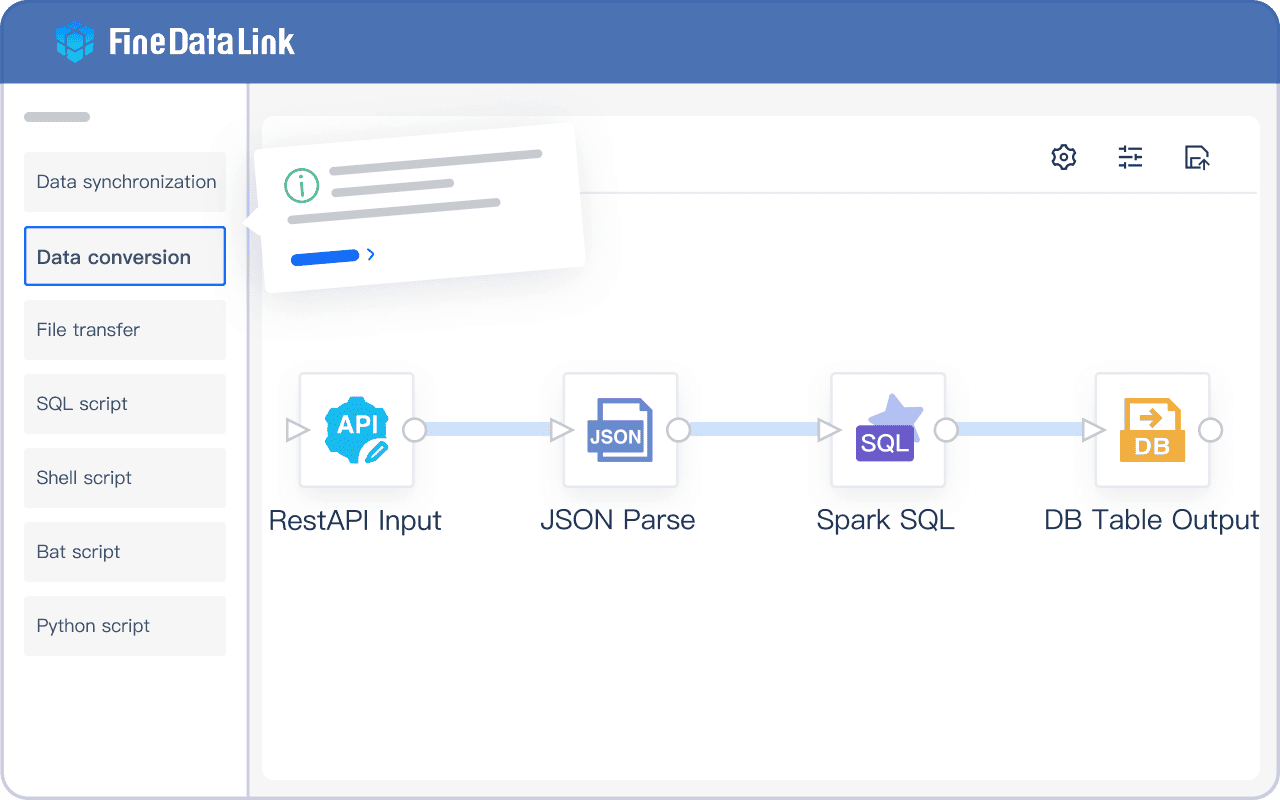
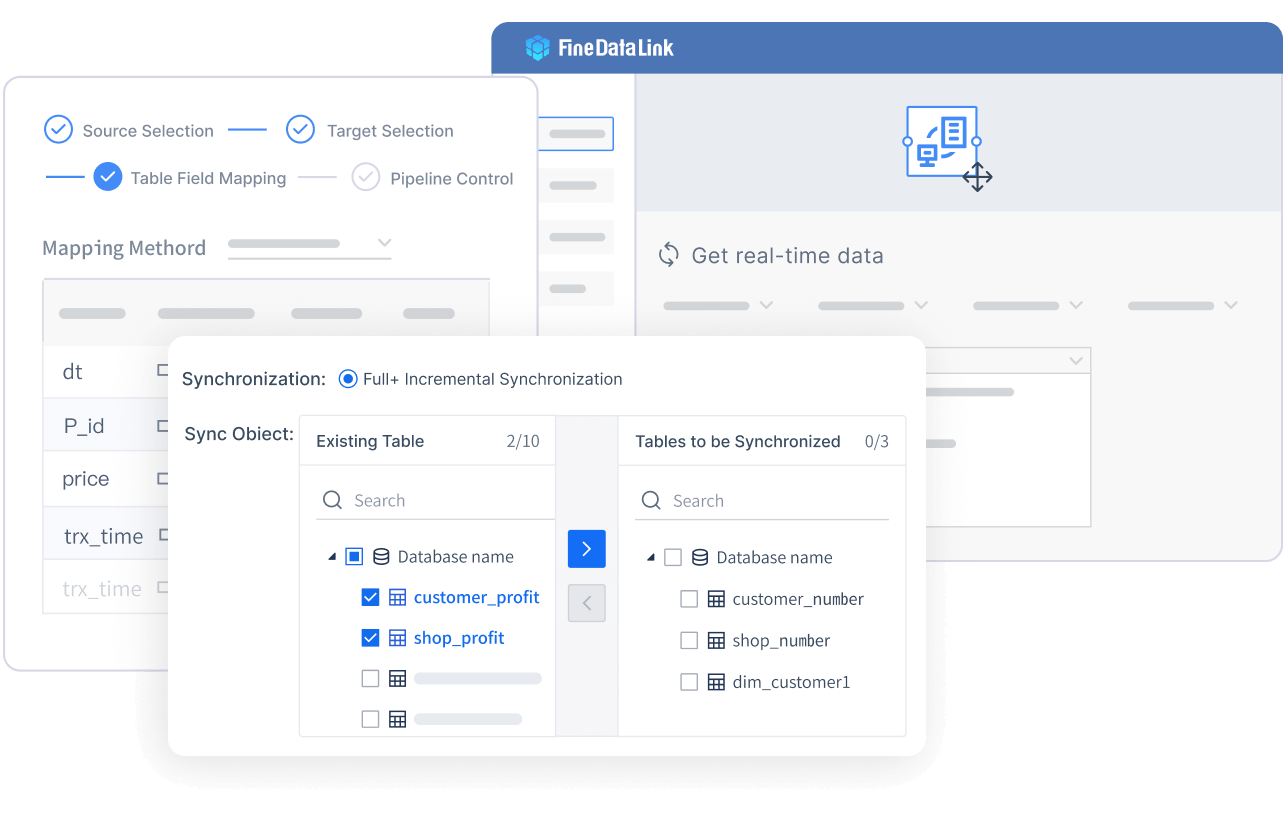
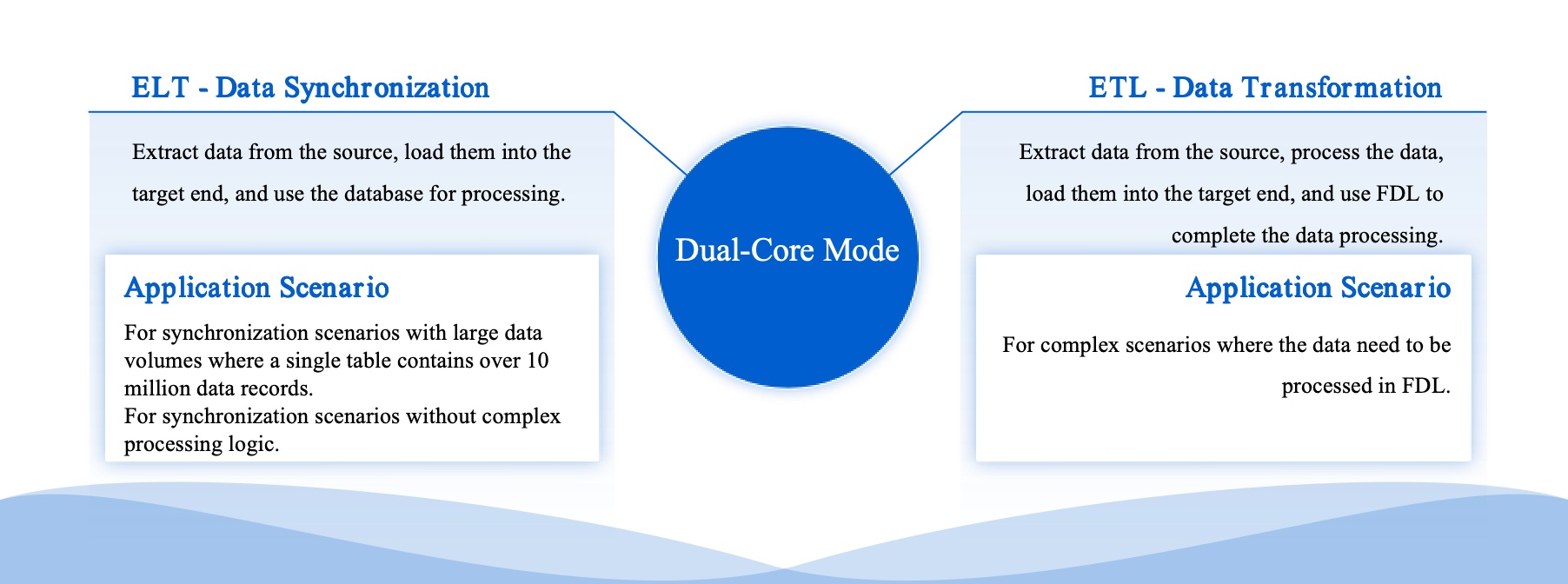
FineDataLink gives you a modern data integration platform that solves real-world challenges. You can synchronize data in real time, build ETL and ELT pipelines with a low-code interface, and connect to over 100 data sources. The platform supports high availability, high concurrency, and easy management. You can scale your solution by adding nodes as your data grows.
Tip: FineDataLink lets you create and launch APIs in five minutes without writing code. This feature helps you share data between systems quickly.
Key Features:
Advantage
Description
High availability
Disaster recovery and hot backup keep your data flowing even during failures
High concurrency
Parallel processing boosts performance for large workloads
Easy management
Visual interface and management tools reduce operational risks
Strong scalability
Add nodes easily to handle more data and users
You can use FineDataLink for database migration, real-time data warehousing, and data governance. The platform’s visual interface makes it easy for you to design and monitor data pipelines. You can also automate data synchronization and transformation tasks.
Use Cases:
Real-time data integration for analytics and reporting
Building offline or real-time data warehouses
Sharing data between SaaS applications and legacy systems
Limitations:
You need to follow case conventions during data development. Use uppercase or enclose queries in quotes.
Field names must be 64 characters or less. Use lowercase letters, numbers, and underscores.
FineDataLink stands out among data engineering tools for its user-friendly design and broad connectivity. You can request a free trial to see how it fits your needs.
2.Databricks
Databricks is one of the best data engineering tools for large-scale data processing. You can use it to process massive datasets with Apache Spark. The platform supports collaboration between data engineers and data scientists. You can handle structured, semi-structured, and unstructured data.
Combines data lakes and warehouses for fast queries
Observability
End-to-end workflow monitoring
You can use Databricks for streaming data ingestion, machine learning, and real-time analytics. Retailers use it for clickstream analysis. Automotive companies use it for autonomous vehicle models.
Limitations:
You need coding skills to use Databricks effectively.
Costs can be unpredictable because you pay for Databricks Units (DBUs) as you use them.
Setup can take months before you see results.
Pricing:
Usage Level
Monthly DBU Consumption
Estimated Monthly Cost
Best For
Small Team
100-500 DBUs
$500-2,500
Basic analytics, small datasets
Growing Business
1,000-5,000 DBUs
$2,500-12,500
ML workflows, medium data
Enterprise
10,000+ DBUs
$25,000+
Large-scale ML, big data
3.Snowflake
Snowflake is a cloud-native data platform that gives you elastic scalability and strong integration features. You can run it on AWS, Azure, or Google Cloud. The platform separates storage and compute, so you can scale resources independently.
Scale storage and compute separately to save costs
Multi-cluster architecture
Multiple teams can query the same data without slowdowns
You can integrate Snowflake with ETL tools, BI platforms, and machine learning frameworks. The platform supports automation and real-time data processing.
Limitations:
Poorly optimized queries can slow down performance.
Too many concurrent queries can overload resources.
Data governance can be complex, with risks from both too much and too little access.
4.Apache Airflow
Apache Airflow is an open-source workflow orchestration tool. You can use it to schedule, monitor, and manage complex data pipelines. Airflow works well with many platforms, including AWS, Google Cloud, and Kubernetes.
Directed Acyclic Graphs for precise workflow management
Python Integration
Custom operators and hooks for advanced workflows
You can use Airflow to automate ETL jobs, manage machine learning workflows, and orchestrate cloud data engineering tasks.
5.Google Cloud Dataflow
Google Cloud Dataflow is a fully managed service for stream and batch data processing. You can use it for real-time analytics, ETL, and data enrichment.
Dataflow uses a pay-as-you-go pricing model. You pay only for the resources you use, with no upfront fees. You need to manage resources actively to optimize costs.
6.AWS Glue
AWS Glue is a serverless data integration service. You can automate ETL code generation and manage data catalogs. Glue works well with structured, semi-structured, and unstructured data.
You can use AWS Glue for cloud-native ETL workflows and data lake integration. The platform is ideal for teams using AWS.
7.Fivetran
Fivetran automates data pipeline creation and management. You can sync data from many sources with minimal setup. The platform adapts to schema changes and supports real-time data sync on enterprise plans.
You can use dbt to build modular, reusable data models and automate data quality checks.
9.Microsoft Azure Data Factory
Azure Data Factory (ADF) is a cloud-based data integration service. You can orchestrate data workflows with a low-code interface. ADF supports over 90 built-in connectors for seamless integration.
Data availability and fault tolerance through duplication
Broker Clustering
Multiple brokers handle increased load and provide high availability
Kafka helps you build scalable, fault-tolerant data engineering tools for real-time analytics and integration.
Note: The best data engineering tools for your team depend on your specific needs, data volume, and existing infrastructure. You should compare features, pricing, and integration options before making a decision.
Key Features of Leading Data Engineering Tools
Scalability and Performance
You need tools that can handle growth and heavy workloads. Leading platforms use cloud-native architecture to deliver fast data processing and reliable performance. Many companies, like Amazon and Twitter, have improved their data integration and transformation by upgrading their systems. Here is a table showing how top organizations benefit from scalable solutions:
You want data integration tools that connect with many sources and platforms. Modern solutions support real-time data integration, making it easy to unify fragmented data. These tools handle large datasets and work with your existing systems. This flexibility helps you build a strong data architecture that supports analytics and reporting.
Automation and Orchestration
Automation saves you time and reduces errors. Top tools offer features like workflow scheduling, retry logic, and event-driven automation. You can use platforms such as Airflow, Prefect, and dbt to automate transformation and data integration tasks. Here are some advanced features you might find:
Airflow: Automates complex workflows with scheduling and retry logic.
Prefect: Supports event-driven workflows and built-in observability.
Dagster: Focuses on data quality with asset-based DAGs.
dbt: Manages transformation pipelines with SQL-based modeling and testing.
ActiveBatch: Provides real-time monitoring and advanced error handling.
Security and Compliance
You must protect your data and follow regulations. Leading data integration platforms meet strict security standards. Many have certifications like ISO/IEC 27001, SOC 1, SOC 2, and NIS2. These certifications show that the platform keeps your data safe and supports compliance with privacy laws.
Certification
Description
ISO/IEC 27001
Ensures data confidentiality, integrity, and availability
You need to understand how pricing works before you choose a tool. Some platforms use pay-as-you-go models, while others offer subscriptions. Pricing often depends on the amount of data integration, transformation, and data processing you perform. Always check for hidden costs related to scaling or advanced features.
Tip: Start with a free trial or demo to see if the tool fits your data architecture and transformation needs.
Real-World Data Engineering Use Cases
Data Pipeline Automation
You can automate data pipeline development to improve efficiency and accuracy. Many organizations use automation to handle large volumes of data and reduce manual work. For example, healthcare institutions automate data pipeline creation to improve patient care and operations. Manufacturers use automation to boost production efficiency and maintain quality standards. Financial services rely on automated pipelines for better risk management and fraud detection.
Industry
Example Description
Key Outcomes
Healthcare
Improved patient care and operations through data pipeline automation.
Increased organic search traffic, more appointments, better patient acquisition.
Manufacturing
Enhanced PCB production efficiency using predictive quality and data automation.
Fewer X-ray tests, maintained quality standards.
Financial Services
Improved risk management and fraud detection with real-time data analysis.
Better risk assessment, regulatory compliance, and investment identification.
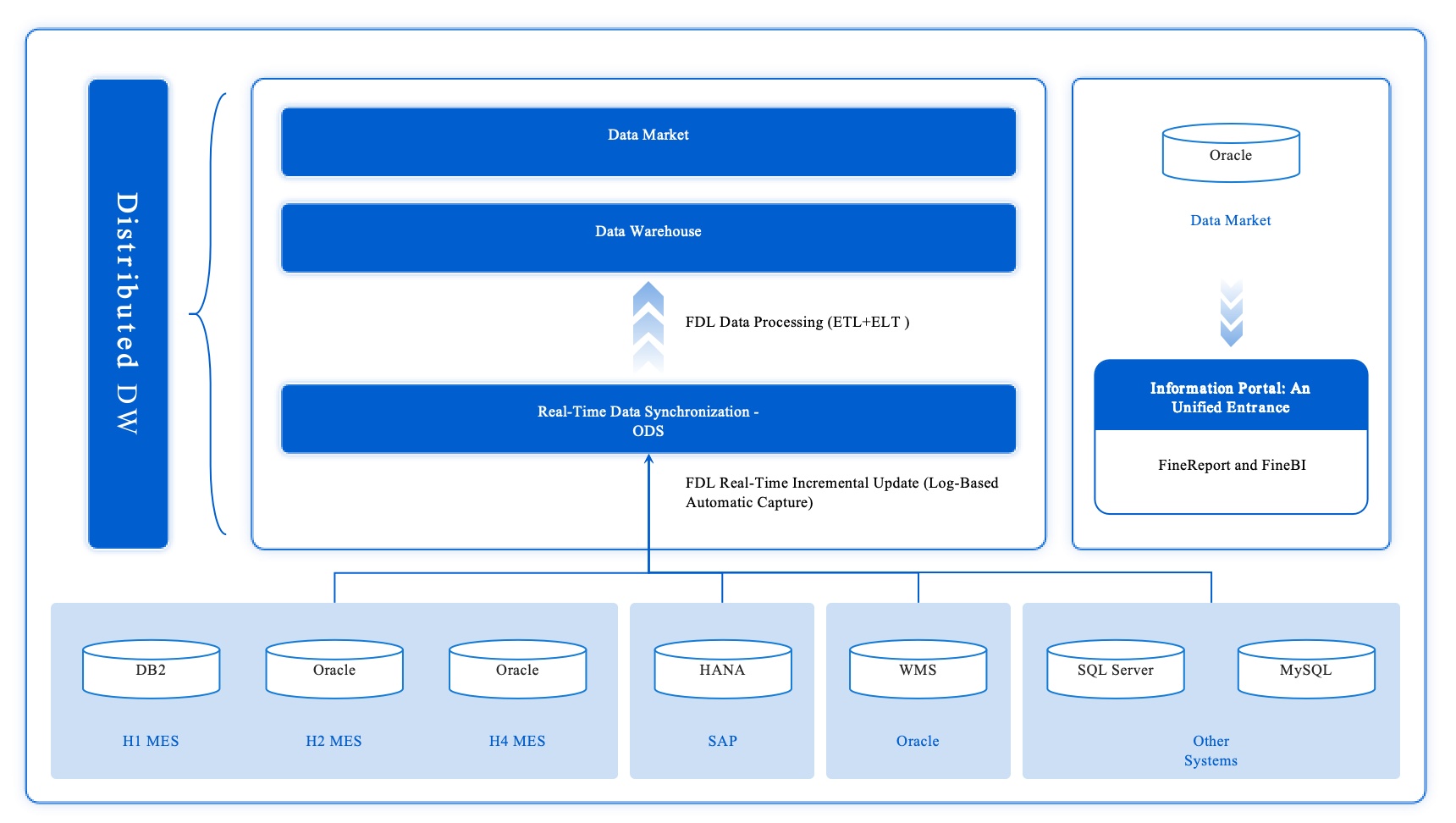
FineDataLink helps you automate data pipeline development with a visual interface and low-code tools. You can connect over 100 data sources and synchronize data in real time.
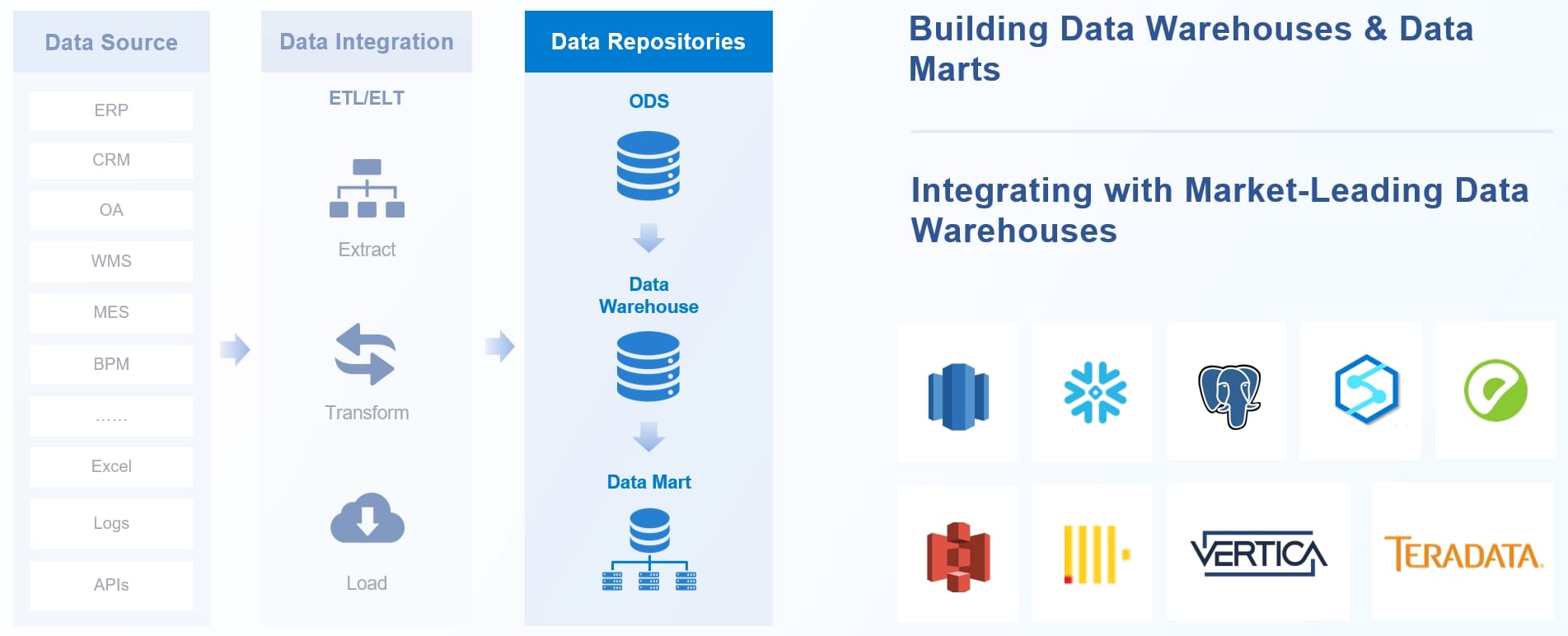
You need strong ETL and ELT workflows for successful migration and data pipeline development. Many enterprises use best practices and popular tools to build reliable pipelines. You can follow these steps to create an end-to-end ELT pipeline:
Export raw sales data to cloud storage.
Create a cluster for processing.
Build external tables for staging.
Use transformation tools like dbt or Apache Spark.
Visualize cleansed data with BI platforms.
You can use tools such as Apache NiFi, Talend, and Python for ETL. For storage, PostgreSQL and MySQL are common choices. FineDataLink supports ETL and ELT workflows, making migration and data pipeline creation easier for your team.
Real-Time Analytics
You can use real-time analytics to make faster decisions and improve customer experiences. Real-time analytics helps you automate software, boost efficiency, and stand out from competitors. You may face challenges such as choosing the right tools, managing scale, and enabling real-time observability.
Benefits of Real-Time Analytics
Challenges of Real-Time Analytics
Faster decision-making
Using the right tools
Automated, intelligent software
Adopting a real-time mindset
Improved customer experiences
Managing cross-team collaboration
Better cost and process efficiency
Handling scale
Competitive differentiation
Enabling real-time observability
FineDataLink supports real-time analytics by synchronizing data across systems with minimal latency. You can build real-time warehouses and improve your data-driven strategies.
You need robust warehouses for data-driven decision-making. Data warehouse development lets you store, organize, and analyze large datasets. You can use warehouses to support reporting, analytics, and migration projects. FineDataLink helps you build both offline and real-time warehouses, supporting data lake development and governance.
FanRuan Customer Success Stories
You can see the impact of data engineering through FanRuan customer stories. UnionPay Data Services unified fragmented data and improved system efficiency by 5%. The company increased customer value identification accuracy to 90% and boosted engagement with precise marketing. NTT DATA Taiwan integrated backend systems using ETL and created a unified data platform. This helped businesses visualize data, improve operations, and adopt data-driven strategies.
FineDataLink played a key role in these successes. You can use FineDataLink to automate migration, streamline data pipeline development, and support data warehouse development. The platform enables data-driven growth and supports data lake development for modern teams.
Comparing Data Engineering Solutions
Feature Comparison Matrix
When you compare data engineering solutions, you need to look at features that matter most for your team. A good strategy is to focus on user value, business value, effort, and compliance. These criteria help you decide which tool fits your needs and supports your long-term goals.
Criteria
Description
User Value
How important the feature is for your daily work and productivity.
Business Value
The impact the feature has on your company’s goals and growth.
Effort
The time and resources you need to set up and use the feature.
Compliance
How well the tool helps you follow industry rules and regulations.
You can use this matrix as part of your selection strategy. It helps you see which tools offer the best balance for your business and technical needs.
Pros and Cons Table
You should also weigh the pros and cons of each solution. This table gives you a quick overview, so you can build a strategy that matches your team’s skills and project requirements.
Higher costs for big data, limited custom transformations
dbt
Streamlined SQL transformations, easy integration, strong community
Needs SQL knowledge, not a full ETL tool
Apache Kafka
High throughput, low latency, fault-tolerant storage
Complex setup, needs expertise for scaling
Google BigQuery
Serverless, real-time insights
Costs rise with heavy use, limited outside Google
Amazon Redshift
Fast queries, cost-effective for large data
Needs tuning, performance varies by workload
Tableau Prep
Drag-and-drop interface, easy Tableau integration
Fewer advanced options, best in Tableau ecosystem
Talend
Wide integration, strong data quality features
Complex advanced setup, higher enterprise pricing
Tip: Use this table to guide your strategy when choosing a data engineering solution. Think about your team’s experience, your data size, and your business goals.
Choosing the Right Data Engineering Services for the Future
Assessing Team Needs
You should start by understanding what your team wants to achieve with data engineering services. Make a list of your main goals. Do you want to automate data pipelines, improve data quality, or support real-time analytics? Ask your team about their daily challenges. Some teams need easy-to-use tools. Others want advanced features for complex projects. Write down the skills your team has. This helps you pick data engineering services that match your team’s abilities.
Tip: Hold a team meeting to discuss your data goals. This helps everyone share their ideas and needs.
Scalability and Growth
You want data engineering services that can grow with your business. Look for platforms that handle more data as your company expands. Check if the service supports adding new users or connecting more data sources. Some data engineering services offer cloud-based solutions. These let you scale up or down as needed. This flexibility saves you money and time.
Feature
Why It Matters
Cloud support
Easy to add resources
Real-time sync
Handles fast data changes
User management
Supports team growth
Integration with Existing Tools
You should choose data engineering services that work well with your current tools. Make a list of the software your team uses every day. Check if the new service connects to these tools. Good integration means you do not need to change your workflow. Many data engineering services offer connectors for databases, cloud apps, and BI platforms. This makes your work easier and faster.
Budget Considerations
You need to think about cost when choosing data engineering services. Some services charge by the amount of data you use. Others have a monthly fee. Make a budget before you start looking. Compare the prices of different data engineering services. Look for free trials or demos. This helps you test the service before you buy.
Note: Picking the right data engineering services saves you money and helps your team work better.
You need to choose the right data engineering solution to support your team’s growth and success. Focus on tools that match your goals, budget, and technical needs. Review the comparison tables and feature lists before you decide. Try free demos or trials to see which platform fits best. Talk with your team and stakeholders to gather feedback.
Tip: Stay curious about new trends in data engineering. Follow industry news and updates to keep your skills sharp.
Product Trial
FineReport
Pixel-perfect reports · Interactive dashboards · Easy data entry · Digital twins
Access a wealth of case studies, industry insights, and solution guides to accelerate digital transformation.
FAQ
What is the main benefit of using a data engineering platform?
You can save time and reduce errors. Data engineering platforms automate data collection, transformation, and delivery. You get reliable data for analysis and reporting.
How do I choose the right data engineering tool for my team?
Start by listing your team’s needs. Compare features, integration options, and pricing. Try free demos or trials. Ask your team for feedback before making a decision.
Can I integrate cloud and on-premises data sources?
Yes, most modern data engineering tools support both cloud and on-premises sources. You can connect databases, SaaS apps, and legacy systems for unified data management.
Do I need coding skills to use these platforms?
Some platforms offer low-code or no-code interfaces. You can build pipelines with drag-and-drop tools. Others, like Databricks or dbt, require SQL or Python knowledge.
How does real-time data integration help my business?
Real-time data integration lets you see updates instantly. You can make faster decisions, improve customer experiences, and react quickly to changes in your business environment.