데이터를 보다 보면 “어느 쪽이 더 들쭉날쭉한가?”를 비교해야 할 때가 많습니다. 이때 가장 먼저 떠오르는 지표가 표준편차입니다. 그런데 평균 크기가 크게 다른 집단끼리 단순히 표준편차만 비교하면 오해가 생길 수 있습니다. 바로 이 지점에서 변동계수가 유용합니다.
변동계수(CV, Coefficient of Variation)는 평균에 비해 데이터가 얼마나 퍼져 있는지를 보여주는 상대적인 지표입니다. 숫자의 절대 크기가 다른 집단도 같은 기준으로 비교할 수 있게 도와주기 때문에, 통계 입문자부터 실무 분석자까지 자주 접하게 됩니다.
변동계수는 간단히 말해 표준편차를 평균으로 나눈 값입니다. 표준편차가 데이터의 퍼짐 정도를 나타낸다면, 변동계수는 그 퍼짐을 평균 크기로 한 번 더 보정해서 보여줍니다.
예를 들어 생각해 보겠습니다.
표준편차만 보면 두 번째 반이 더 퍼져 있는 것처럼 보입니다. 하지만 평균 자체가 2배 차이 나기 때문에, 평균 대비 얼마나 흔들리는지를 봐야 공정한 비교가 됩니다. 이럴 때 변동계수를 사용합니다.
변동계수의 핵심은 다음 한 줄로 정리할 수 있습니다.
즉, 숫자의 규모가 큰 집단은 표준편차도 자연스럽게 커지는 경향이 있는데, 변동계수는 이런 규모 차이를 어느 정도 보정해 줍니다. 그래서 매출, 소득, 수익률, 생산량, 실험 측정값처럼 평균 수준이 다른 데이터를 비교할 때 특히 유용합니다.
쉽게 말하면, 변동계수는 “얼마나 퍼졌는가?”보다 **“평균에 비해 얼마나 퍼졌는가?”**를 보는 도구입니다.
표준편차와 변동계수는 둘 다 산포, 즉 데이터의 흩어짐을 보는 지표입니다. 하지만 둘은 같은 역할을 하지 않습니다. 겉보기에는 비슷해 보여도, 실제 해석은 꽤 다릅니다.
표준편차는 원래 단위 그대로 퍼짐을 보여줍니다.
예를 들어 점수 데이터라면 “몇 점 정도 흔들리는지”, 지출 데이터라면 “몇 원 정도 차이 나는지”를 알려줍니다. 그래서 직관적입니다.
반면 변동계수는 평균으로 나눈 값이기 때문에 상대적인 흔들림을 보여줍니다. 즉, “평균에 비해 몇 % 정도 퍼져 있는지”를 보는 데 더 적합합니다.
둘의 차이를 일상적인 말로 바꾸면 이렇게 이해할 수 있습니다.
예를 들어 월급이 200만 원인 집단과 1,000만 원인 집단이 있다고 해보겠습니다. 두 집단의 표준편차가 각각 20만 원, 50만 원이라면 표준편차만 봤을 때는 1,000만 원 집단이 더 불안정해 보일 수 있습니다. 하지만 평균 대비로 보면 오히려 200만 원 집단의 변동성이 더 클 수도 있습니다. 이런 비교에서 변동계수가 빛을 발합니다.
실무나 공부에서 헷갈리지 않으려면 기준을 간단히 기억하면 됩니다.
표준편차가 더 직관적인 경우
변동계수가 더 유용한 경우
즉, 같은 반 두 시험의 점수 퍼짐을 볼 때는 표준편차가 충분할 수 있지만, 평균 수준이 다른 두 반이나 서로 다른 상품군을 비교할 때는 변동계수가 더 적절할 수 있습니다.
변동계수 계산식은 매우 단순합니다.
변동계수 = 표준편차 ÷ 평균
보통은 여기에 100을 곱해 **백분율(%)**로 표현합니다.
변동계수(%) = (표준편차 ÷ 평균) × 100
왜 퍼센트로 표현할까요?
숫자를 더 직관적으로 읽기 쉽기 때문입니다. 예를 들어 변동계수가 0.12라면, 이를 12%로 표시해 **“평균의 12% 정도 수준으로 흔들린다”**고 이해할 수 있습니다.
기본 해석은 대체로 다음과 같습니다.
다만 이 해석은 절대 기준이 아니라 비교 대상 안에서 상대적으로 봐야 합니다. 어떤 분야에서는 10%도 큰 편일 수 있고, 다른 분야에서는 30%가 평범할 수도 있습니다.
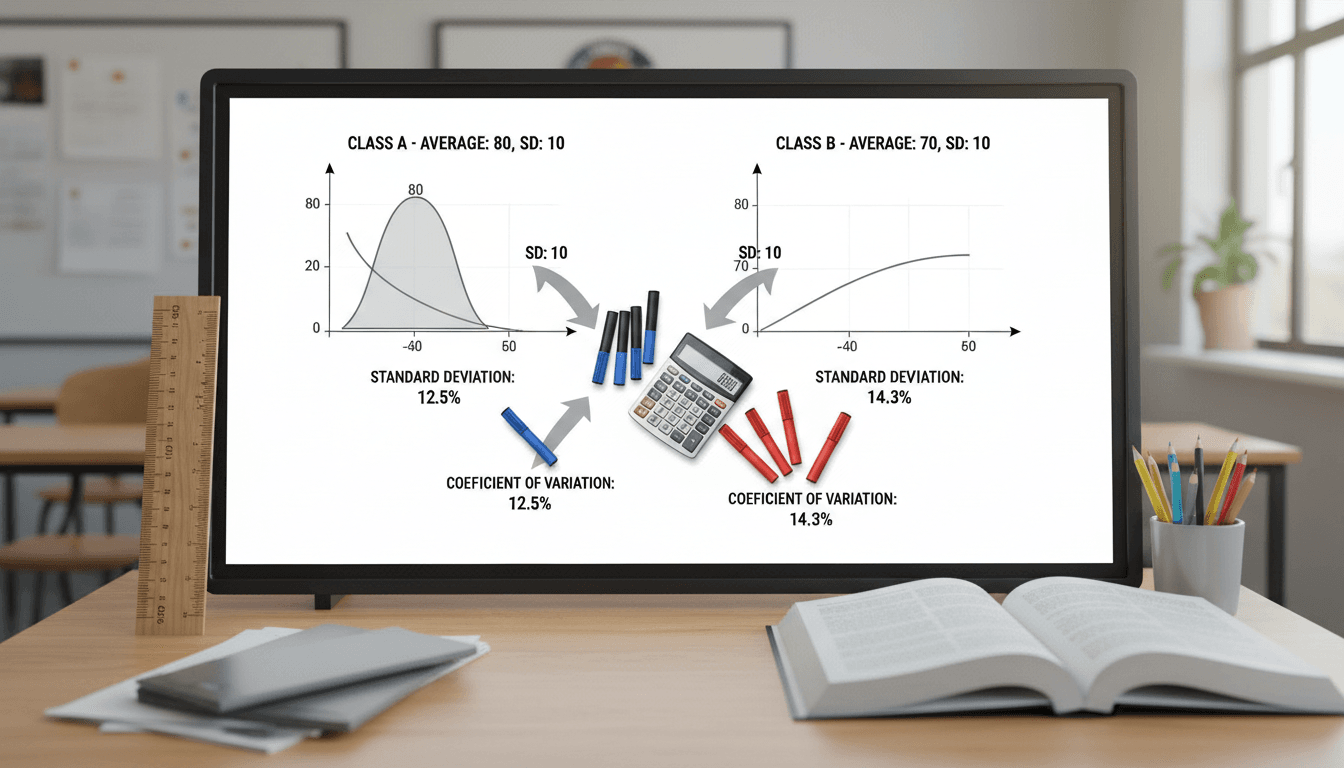
두 반의 시험 성적을 비교해 보겠습니다.
표준편차만 보면 B반이 9점, A반이 8점이므로 B반이 조금 더 퍼져 있습니다.
그런데 평균이 다르기 때문에 변동계수로 다시 보면 해석이 달라질 수 있습니다.
계산해 보겠습니다.
결과적으로 B반은 평균 점수 자체도 더 낮고, 평균 대비 점수의 흔들림도 더 큽니다. 즉, 상대적 변동성은 B반이 더 크다고 볼 수 있습니다.
표준편차만 보면 차이가 크지 않아 보였지만, 변동계수를 보면 B반의 성적 분포가 상대적으로 더 불균일하다는 점이 더 분명해집니다.
이번에는 소득 수준이 다른 두 사람의 월 지출을 비교해 보겠습니다.
표준편차만 보면 이씨의 지출이 더 많이 흔들리는 것처럼 보입니다.
하지만 평균 수준이 훨씬 높기 때문에 변동계수를 계산해 봐야 합니다.
이 결과는 흥미롭습니다.
절대 금액 차이는 이씨가 더 크지만, 평균 지출 대비로 보면 김씨의 지출 패턴이 더 불안정합니다. 즉, 김씨 쪽이 상대적으로 월별 지출 변동이 더 큰 것입니다.
이처럼 변동계수는 “누가 더 많이 썼는가”가 아니라 **“누가 평균에 비해 더 들쭉날쭉한가”**를 판단하는 데 적합합니다.
변동계수는 단순한 통계 개념에 그치지 않고 실무에서도 자주 활용됩니다. 특히 평균 규모가 다른 여러 대상의 안정성, 일관성, 위험도를 비교할 때 유용합니다.
대표적인 활용 예시는 다음과 같습니다.
예를 들어 투자에서는 수익률 평균이 서로 다른 상품을 비교할 때 표준편차만으로는 부족할 수 있습니다. 평균 수익률이 높은 상품은 표준편차도 함께 커질 수 있기 때문입니다. 이때 변동계수를 보면 “수익 대비 변동성”을 좀 더 상대적으로 비교할 수 있습니다.
품질관리에서도 마찬가지입니다. 어떤 생산 라인의 평균 생산량은 크지만 변동도 클 수 있고, 다른 라인은 평균은 낮지만 훨씬 일정할 수 있습니다. 이런 경우 변동계수는 단순한 퍼짐이 아니라 상대적 일관성을 평가하는 데 도움을 줍니다.
일반적으로는 다음처럼 해석합니다.
하지만 여기서 중요한 점이 있습니다.
변동계수의 “높다/낮다”는 절대 기준이 아닙니다. 산업, 데이터 특성, 측정 방식에 따라 충분히 달라질 수 있습니다. 따라서 수치 하나만 떼어 놓고 좋다 나쁘다를 판단하기보다, 같은 분야 안에서 비교하는 방식이 더 적절합니다.
엑셀에서도 변동계수는 쉽게 계산할 수 있습니다. 기본 흐름은 다음과 같습니다.
예를 들어 데이터가 A2:A11 범위에 있다면 다음처럼 계산할 수 있습니다.
=AVERAGE(A2:A11)=STDEV.S(A2:A11) 또는 상황에 따라 =STDEV.P(A2:A11)=STDEV.S(A2:A11)/AVERAGE(A2:A11)퍼센트로 보고 싶다면 셀 서식을 백분율로 바꾸면 됩니다.
혹은 식 자체를 *100 해서 계산할 수도 있지만, 보통은 원래 값은 비율 그대로 두고 셀 서식만 퍼센트로 바꾸는 방식이 더 깔끔합니다.
주의할 점도 있습니다.
엑셀 외에도 변동계수는 다양한 통계 도구에서 쉽게 구할 수 있습니다.
실제로는 대부분 표준편차 / 평균 공식으로 직접 계산합니다. 특별한 전용 함수가 없어도 계산이 간단하기 때문에, 데이터 분석 도구만 있다면 어디서든 빠르게 확인할 수 있습니다.
변동계수는 매우 유용한 지표이지만, 모든 상황에서 만능은 아닙니다. 오히려 조건을 모르고 쓰면 해석이 왜곡될 수 있습니다.
가장 먼저 주의해야 할 점은 평균이 0이거나 0에 매우 가까운 경우입니다.
변동계수는 평균으로 나누는 구조이기 때문에, 평균이 너무 작으면 값이 지나치게 커지거나 아예 해석이 불가능해질 수 있습니다. 이런 데이터에서는 변동계수가 안정적인 비교 도구가 되기 어렵습니다.
두 번째는 음수 값이 포함된 데이터입니다.
변동계수는 보통 평균이 양수이고, 크기 비교가 자연스러운 데이터에서 잘 작동합니다. 그런데 평균이 음수이거나 값에 양수와 음수가 혼재하면, “평균 대비 퍼짐”이라는 해석 자체가 애매해질 수 있습니다. 예를 들어 수익과 손실이 함께 있는 데이터는 변동계수만으로 해석하기에 조심스러운 경우가 많습니다.
세 번째는 지표 하나로 모든 판단을 내리면 안 된다는 점입니다.
변동계수는 상대적 산포를 보여주지만, 데이터 분포의 모양이나 이상치 존재 여부까지 설명해 주지는 않습니다. 같은 변동계수를 가진 두 집단이라도 실제 분포는 전혀 다를 수 있습니다.
따라서 다음 요소를 함께 보는 것이 좋습니다.
즉, 변동계수는 매우 좋은 비교 도구이지만, 항상 맥락과 함께 읽어야 합니다.
마지막으로 핵심만 짧게 정리해 보겠습니다.
한마디로 정리하면, 표준편차가 **“얼마나 퍼졌는가”**를 보여준다면, 변동계수는 **“평균에 비해 얼마나 퍼졌는가”**를 보여줍니다. 두 지표를 함께 보면 데이터의 모습을 훨씬 더 정확하게 이해할 수 있습니다.
표준편차는 데이터가 실제 단위에서 얼마나 퍼졌는지 보여주고, 변동계수는 평균 대비 얼마나 퍼졌는지를 보여줍니다. 평균 크기가 다른 집단을 비교할 때는 변동계수가 더 적합한 경우가 많습니다.
평균 수준이 크게 다른 두 집단의 변동성을 비교할 때 유용합니다. 매출, 수익률, 지출, 품질 측정값처럼 상대적 안정성을 보고 싶을 때 자주 사용됩니다.
기본 공식은 표준편차를 평균으로 나누는 것입니다. 보통 여기에 100을 곱해 퍼센트로 표시하면 해석이 더 쉬워집니다.
꼭 그렇지는 않습니다. 변동계수가 높다는 것은 평균 대비 흔들림이 크다는 뜻이지만, 좋은지 나쁜지는 산업과 데이터 특성에 따라 달라집니다.
평균이 0이거나 0에 매우 가까우면 값이 왜곡될 수 있어 해석이 어렵습니다. 또한 음수 데이터나 이상치가 많은 경우에는 평균과 표준편차, 분포 형태를 함께 보는 것이 좋습니다.

작성자
Seongbin
FanRuan에서 재직하는 고급 데이터 분석가
관련 기사

AI 툴 모음 비교: FineChatBI와 주요 경쟁사 분석으로 최적 선택 가이드
디지털 시대, 데이터는 새로운 석유입니다. 하지만 원유를 정제하지 않으면 가치가 없듯이, 데이터도 분석과 통찰로 전환되어야 비즈니스의 힘이 됩니다. 이를 위해 수많은 $1 도구가 쏟아져 나오고 있으며, 올바른 $1 속에서 자신의 필요에 딱 맞는 솔루션을 찾는 것은 쉽지 않은 과제입니다. 이 글은 대화형 $1의 선구자인 FineChatBI를 중심으로 주요 경쟁사들과의 객관적인 비교를 제공함으로
Seongbin
2026년 6월 04일

직장인 필수 AI 툴 고르기: 검색형 AI, 문서형 AI, BI형 AI의 차이와 추천 상황
AI가 업무에 깊숙이 들어오면서 많은 직장인이 비슷한 고민을 합니다. “어떤 $1 을 써야 정말 일이 빨라질까?” 문제는 AI 서비스가 많아질수록 선택이 더 어려워진다는 점입니다. 검색을 잘하는 도구, 글을 잘 써주는 도구, 데이터를 읽고 설명해주는 도구는 겉보기엔 비슷해 보여도 실제 업무에서의 역할은 전혀 다릅니다. 특히 직장인의 실무는 단순히 답을 얻는 데서 끝나지 않습니다. 자료를 찾고
Seongbin
2026년 5월 28일

생산성 향상이 안 되는 진짜 이유 7가지: 시간관리보다 먼저 점검할 핵심
$1 향상이라고 하면 많은 사람이 먼저 일정 관리, 할 일 목록, 캘린더 최적화 같은 방법을 떠올립니다. 물론 이런 도구들은 분명 도움이 됩니다. 하지만 현실에서는 시간관리 기술을 배워도 성과가 크게 달라지지 않는 경우가 많습니다. 바쁘게 일했는데 남는 결과는 적고, 하루를 꽉 채웠는데도 중요한 일은 제자리인 경험이 반복되기 때문입니다. 문제는 시간이 아니라 무엇에 시간을 쓰고 있는지 , 그
Seongbin
2026년 5월 17일



