Data integration serves as a critical business process in today's 'Big Data' world. Enterprises with a strong AI strategy are three times more likely to report above-average data integration success. Integrated data supports complex analytics and predictive modeling, driving innovation and competitiveness. Over time, the data integration process improves the value of a business's data. Data Integration Patterns enable organizations to enhance decision-making, improve data quality, and boost operational efficiency.
Understanding Data Integration Patterns
Definitions and Scope
Data Integration Patterns refer to standardized methods for moving, transforming, and consolidating data. These patterns help organizations manage data from various sources efficiently. Data integration involves processes like data migration, synchronization, and aggregation. Each pattern addresses specific business needs and technical requirements.
Benefits and Challenges
Data Integration Patterns offer several benefits:
Enhanced Decision-Making: Integrated data provides a unified view, enabling better strategic decisions.
Improved Data Quality: Standardized methods ensure consistent and accurate data.
Operational Efficiency: Streamlined processes reduce manual data handling and errors.
However, challenges exist:
Complexity: Implementing these patterns can be technically demanding.
Data Privacy: Ensuring compliance with data privacy regulations is crucial.
Scalability: Systems must handle increasing data volumes without performance degradation.
Common Types
Several Data Integration Patterns are widely used:
ETL (Extract, Transform, Load): Extracts data from source systems, transforms it, and loads it into a destination system.
ELT (Extract, Load, Transform): Loads data into a destination system first, then transforms it.
Data Virtualization: Provides a unified data view without physical data movement.
Change Data Capture (CDC): Tracks changes in data sources and updates target systems accordingly.
Data Streaming: Processes data in real-time as it flows through the system.
Transform: Data transformation into a suitable format or structure.
Load: Data loading into a target system, such as a data warehouse.
Key Characteristics:
Batch Processing: ETL often operates in batch mode, processing large volumes of data at scheduled intervals.
Data Cleansing: The transformation phase includes data cleansing to ensure accuracy and consistency.
Schema Mapping: ETL involves mapping source data schemas to target schemas.
Benefits:
Centralized Data Repository: ETL consolidates data from multiple sources into a single repository.
Improved Data Quality: Data cleansing during transformation enhances data quality.
Enhanced Reporting: Centralized and transformed data supports comprehensive reporting and analytics.
Implementation Strategies
Tools and Technologies
Several tools and technologies facilitate ETL implementation:
Informatica PowerCenter: A widely used ETL tool known for its robust data integration capabilities.
Microsoft SQL Server Integration Services (SSIS): A powerful ETL tool integrated with Microsoft SQL Server.
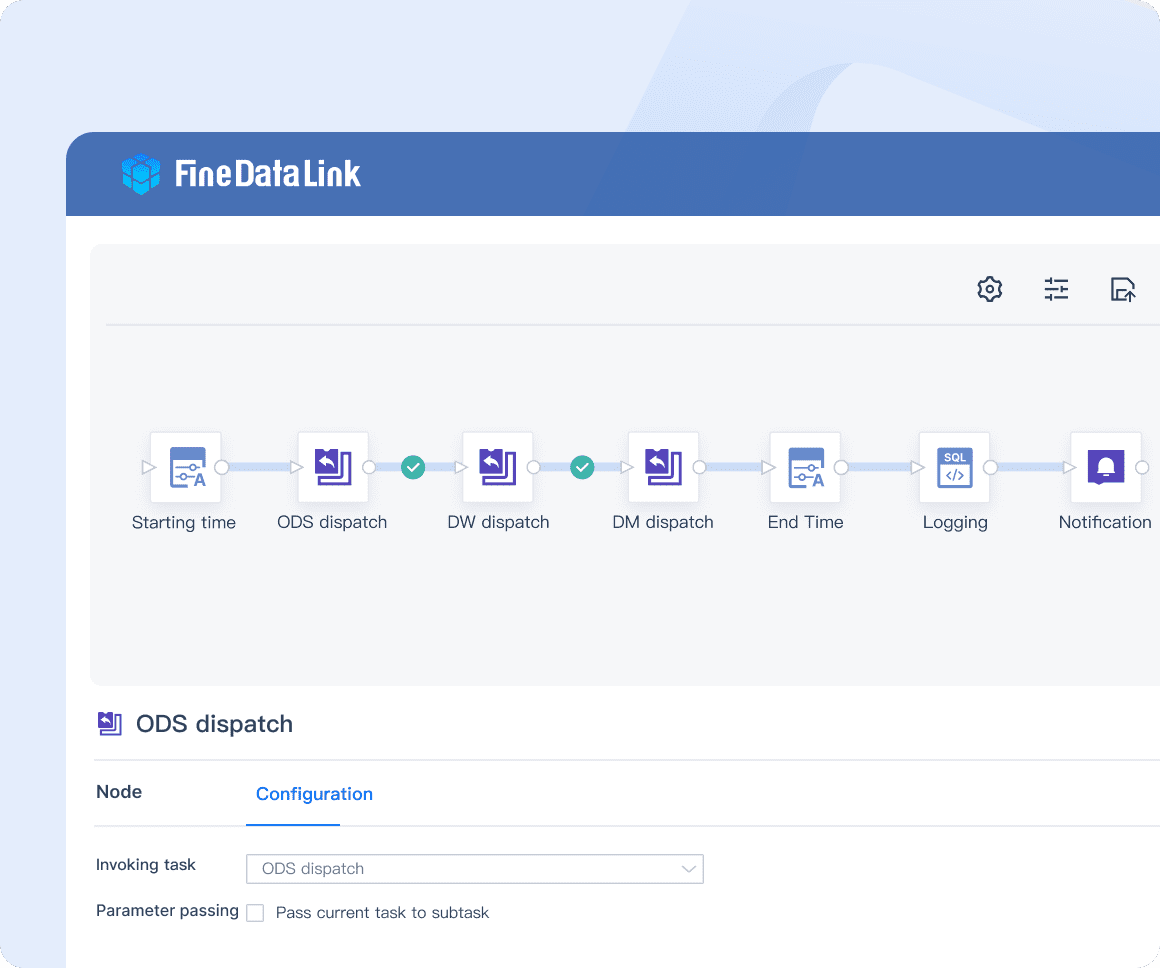
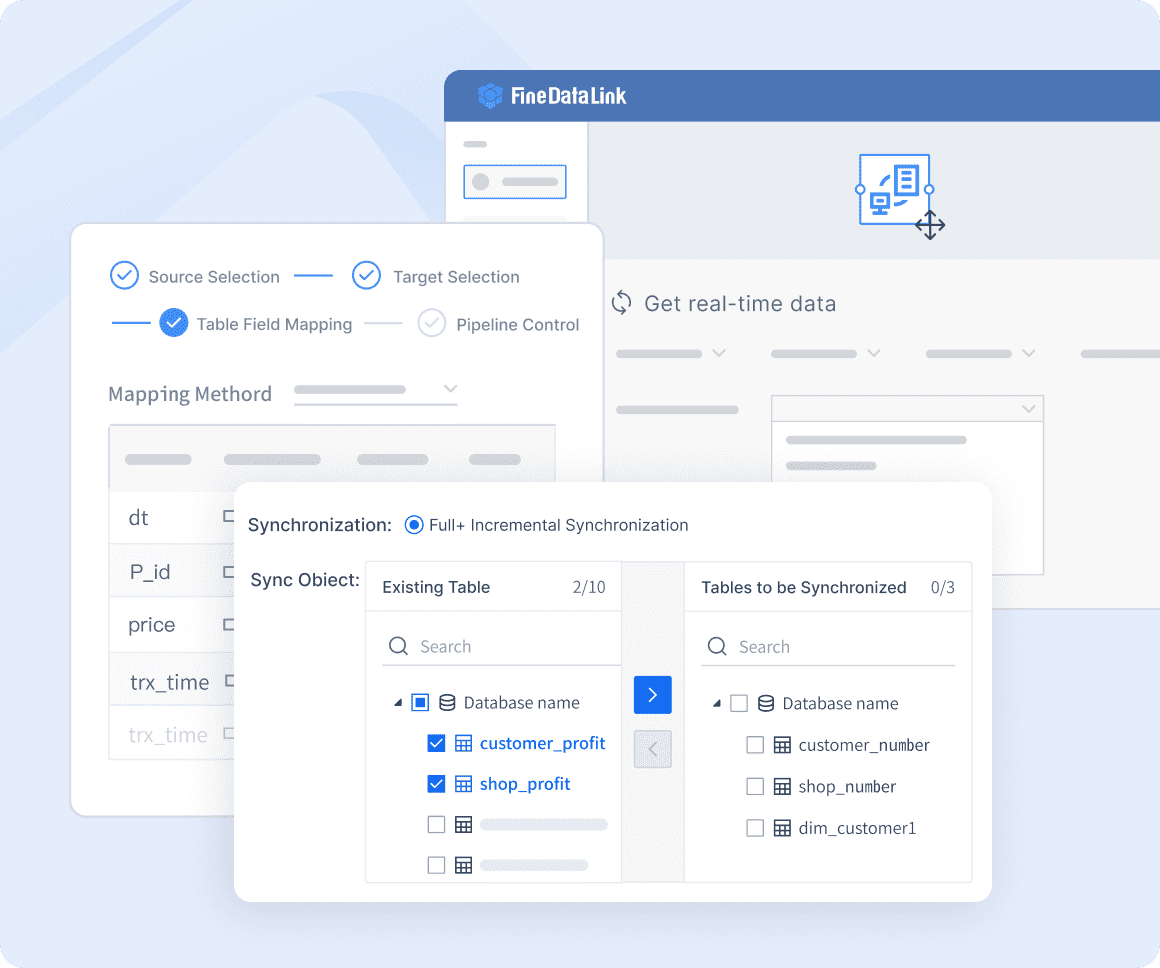
FineDataLink: An effective tool with timed data calculation and synchronization, which can be used for data preprocessing and serves as an ETL tool for building data warehouses.
FineDataLink: Efficient data warehouse construction-with timing data calculation and synchronization, it can be used as an ETL tool for building data warehouses.
Best Practices
Implementing ETL requires adherence to best practices:
Data Profiling: Conduct data profiling to understand source data characteristics.
Incremental Loading: Use incremental loading to process only changed data, reducing load times.
Error Handling: Implement robust error handling mechanisms to manage data inconsistencies.
Case Studies
Example 1: Healthcare
In the healthcare industry, ETL integrates data from multiple EMR systems and clinical data repositories. This integration provides a comprehensive view of patients, enabling more effective decision-making.
Example 2: Retail
In the retail sector, ETL consolidates data from POS systems and inventory management systems. This integration offers a complete view of sales and inventory data, facilitating accurate demand forecasting and inventory planning.
Data Integration Patterns: ELT (Extract, Load, Transform)
Definition and Overview
ELT (Extract, Load, Transform) represents a modern Data Integration Pattern. The process involves extracting data from source systems, loading it into a destination system, and then transforming the data within the destination system.
Key Characteristics
Direct Loading: Data loads directly into the target system before transformation.
In-Place Transformation: Transformations occur within the destination system, leveraging its computational power.
Scalability: ELT scales effectively with large data volumes due to the separation of extraction and transformation phases.
Benefits
Efficiency: Direct loading reduces the time required for data movement.
Resource Optimization: Utilizing the destination system's resources for transformation optimizes performance.
Flexibility: ELT adapts easily to changes in data structures and business requirements.
Implementation Strategies
Tools and Technologies
Several tools and technologies facilitate ELT implementation:
Amazon Redshift: A cloud-based data warehouse that supports ELT processes.
Google BigQuery: A serverless, highly scalable data warehouse designed for ELT.
FineDataLink: A robust tool that ensures efficient data transformation and loading, optimizing the entire data pipeline.
FineDataLink: Real-time data integration-it can synchronize data across multiple tables in real-time with minimal latency.
Best Practices
Implementing ELT requires adherence to best practices:
Data Validation: Validate data at the extraction phase to ensure accuracy.
Parallel Processing: Utilize parallel processing to enhance performance during data loading.
Monitoring and Logging: Implement monitoring and logging mechanisms to track data transformations and identify issues.
Case Studies
Example 1: Financial Services
In the financial services industry, ELT integrates data from trading systems and risk management systems. This integration supports comprehensive risk management and customer segmentation.
Example 2: E-commerce
In the e-commerce sector, ELT consolidates data from web analytics and customer relationship management (CRM) systems. This integration provides insights into customer behavior and preferences.
Data Integration Patterns: Data Virtualization
Definition and Overview
Data Virtualization represents a modern approach within Data Integration Patterns. This method allows users to access and manipulate data without requiring physical movement or replication. Data Virtualization creates a unified view by drawing data from multiple sources across the enterprise.
Key Characteristics
Unified Data Access: Provides a single access point for disparate data sources.
Real-Time Integration: Enables real-time data access and integration.
No Data Movement: Eliminates the need to move or copy data into a central repository.
Benefits
Increased Agility: Enhances responsiveness to changing business needs.
Cost Efficiency: Reduces costs associated with data storage and movement.
Improved Productivity: Streamlines data access, reducing time spent on data retrieval.
Implementation Strategies
Tools and Technologies
Several tools and technologies facilitate Data Virtualization implementation:
Denodo Platform: A feature-rich platform that enhances productivity and flexibility in data access.
CData: Provides embedded Data Virtualization solutions to eliminate data bottlenecks.
TIBCO Data Virtualization: Facilitates the creation of a unified view by drawing data from multiple sources without physical aggregation.
Best Practices
Implementing Data Virtualization requires adherence to best practices:
Data Governance: Ensure robust data governance policies to maintain data quality and compliance.
Performance Optimization: Optimize performance by leveraging caching and indexing techniques.
Security Measures: Implement strong security measures to protect sensitive data during access and integration.
Case Studies
Example 1: Financial Services
In the financial services industry, Data Virtualization integrates data from trading systems, risk management systems, and customer databases. This integration supports comprehensive risk management and customer segmentation.
Example 2: Healthcare
In the healthcare sector, Data Virtualization consolidates data from electronic medical records (EMR) systems and clinical data repositories. This integration provides a comprehensive view of patient data, enabling more effective decision-making.
Data Integration Patterns: Change Data Capture (CDC)
Definition and Overview
Change Data Capture (CDC) represents a vital Data Integration Pattern. CDC tracks changes in data sources and updates target systems accordingly. This pattern ensures that data remains synchronized across various systems. CDC captures insertions, updates, and deletions in real-time or near real-time.
Key Characteristics
Real-Time Updates: CDC provides real-time or near real-time updates to target systems.
Minimal Latency: Ensures minimal latency between data changes and their reflection in the target system.
Event-Driven: Operates on an event-driven architecture, capturing data changes as they occur.
Benefits
Timely Data Availability: Ensures that data remains up-to-date across all systems.
Reduced Data Movement: Minimizes the amount of data transferred by only capturing changes.
Improved Decision-Making: Provides timely and accurate data for better decision-making.
Implementation Strategies
Tools and Technologies
Several tools and technologies facilitate Change Data Capture (CDC) implementation:
Oracle GoldenGate: A comprehensive solution for real-time data integration and replication.
Debezium: An open-source CDC tool that supports various databases.
Microsoft SQL Server: Includes built-in CDC functionality for tracking changes in SQL Server databases.
Best Practices
Implementing Change Data Capture (CDC) requires adherence to best practices:
Data Validation: Validate captured changes to ensure data integrity.
Efficient Storage: Use efficient storage mechanisms to handle change logs.
Monitoring and Logging: Implement robust monitoring and logging to track CDC processes and identify issues.
Case Studies
Example 1: Healthcare
In the healthcare industry, Change Data Capture (CDC) integrates data from multiple electronic medical records (EMR) systems. This integration provides a comprehensive view of patient data, enabling more effective decision-making.
Example 2: Financial Services
In the financial services sector, Change Data Capture (CDC) integrates data from trading systems and risk management systems. This integration supports comprehensive risk management and customer segmentation.
Data Integration Patterns: Data Streaming
Definition and Overview
Data Streaming represents a dynamic Data Integration Pattern. This pattern processes data in real-time as it flows through the system. Data Streaming enables enterprises to handle continuous data input from various sources, providing immediate insights and actions.
Key Characteristics
Real-Time Processing: Processes data as it arrives, ensuring minimal latency.
Continuous Data Flow: Handles an ongoing stream of data without interruptions.
Scalability: Supports large-scale data processing with high throughput.
Benefits
Data Streaming offers numerous benefits:
Immediate Insights: Provides real-time analytics and decision-making capabilities.
Enhanced Responsiveness: Enables quick reactions to changing data conditions.
Operational Efficiency: Reduces the need for batch processing, leading to more efficient operations.
Implementation Strategies
Tools and Technologies
Several tools and technologies facilitate Data Streaming implementation:
IBM Stream Analytics: A real-time data streaming tool that provides an Integrated Development Environment (IDE) and supports Java, Scala, and Python languages.
Azure Stream Analytics: A fully managed and scalable event-processing engine that ingests, processes, and analyzes streaming data from different sources with remarkable speed and efficiency.
Amazon Kinesis Streams (KDS): A reliable service for collecting, processing, and analyzing real-time streaming data.
Best Practices
Implementing Data Streaming requires adherence to best practices:
Data Partitioning: Use data partitioning to distribute data across multiple nodes for parallel processing.
Fault Tolerance: Implement fault tolerance mechanisms to ensure data integrity and availability.
Monitoring and Alerting: Set up monitoring and alerting systems to track data streams and identify issues promptly.
Case Studies
Example 1: Financial Services
In the financial services industry, Data Streaming integrates data from trading systems and market feeds. This integration supports real-time risk assessment and fraud detection.
Example 2: E-commerce
In the e-commerce sector, Data Streaming consolidates data from web analytics and customer interactions. This integration provides insights into customer behavior and preferences.
Data Integration Patterns: API-Based Integration
Definition and Overview
API-Based Integration involves using Application Programming Interfaces (APIs) to connect and integrate different systems. APIs allow applications to communicate and share data seamlessly. This pattern provides a flexible and scalable approach to data integration.
Key Characteristics
Standardized Communication: APIs use standard protocols like HTTP/HTTPS for communication.
Interoperability: Facilitates interaction between disparate systems and platforms.
Real-Time Data Exchange: Enables real-time data sharing and updates.
Benefits
Flexibility: Easily adapts to changes in business requirements and data structures.
Scalability: Supports the integration of multiple systems without performance degradation.
Enhanced Security: Provides secure data exchange through authentication and authorization mechanisms.
Implementation Strategies
Tools and Technologies
Several tools and technologies facilitate API-Based Integration implementation:
Improvado: An end-to-end marketing data pipeline solution that streamlines data operations from extraction to analysis.
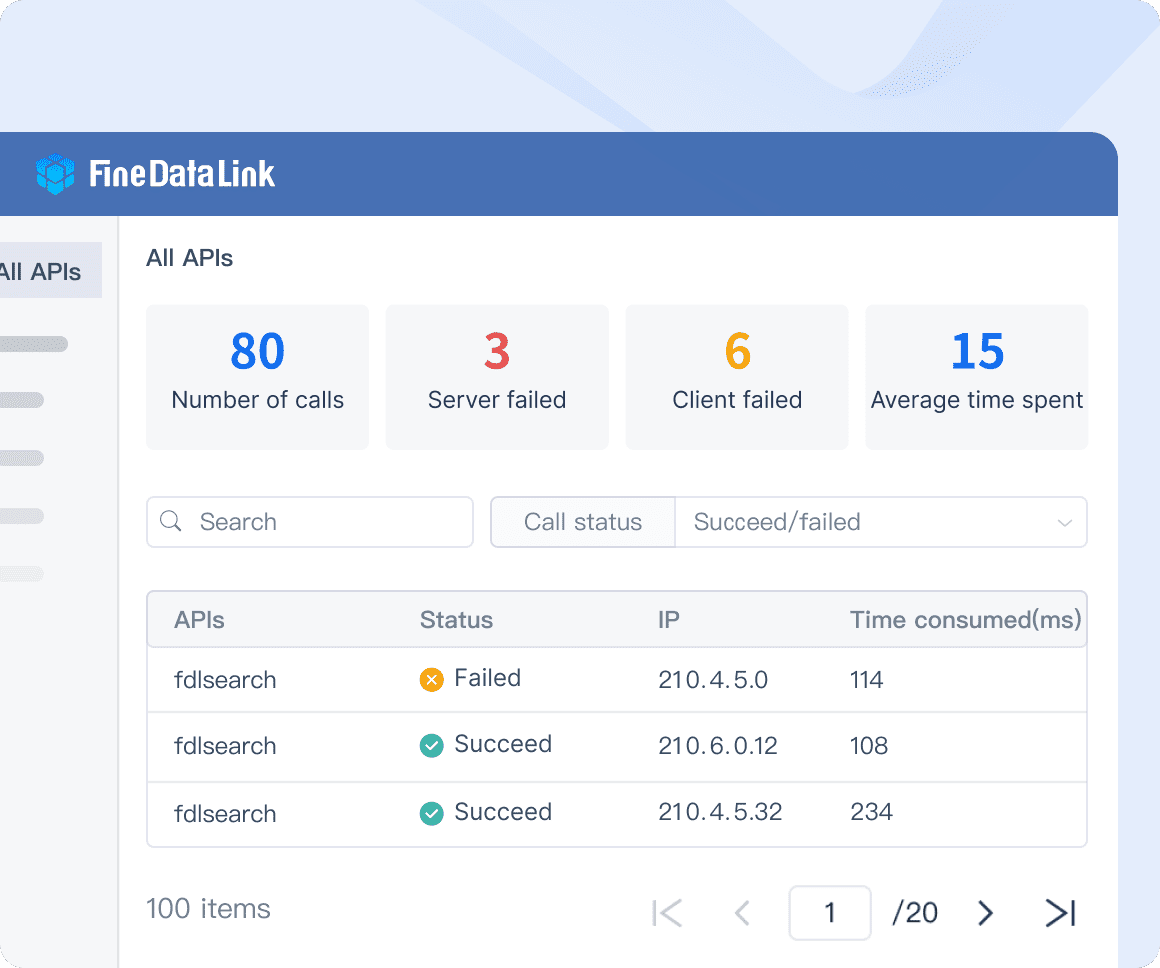
FineDataLink: With FineDataLink, developing and launching an API interface is remarkably swift, taking just five minutes without the need for coding. This feature significantly enhances data integration and exchange across different systems, especially SaaS applications, promoting seamless interoperability and efficiency.
FineDataLink: Application and API integration- it can develop and launch an API interface within 5 minutes without codes.
Oracle API Management: Part of Oracle's extensive suite of business solutions, providing a robust platform for managing, securing, and integrating APIs.
IBM API Connect: An API integration platform that manages the entire API lifecycle, ensuring reliability, scalability, and security.
Best Practices
Implementing API-Based Integration requires adherence to best practices:
API Documentation: Provide comprehensive documentation to ensure developers understand how to use the APIs effectively.
Version Control: Implement version control to manage changes and updates to APIs.
Monitoring and Analytics: Use monitoring and analytics tools to track API performance and identify issues promptly.
Case Studies
Example 1: Financial Services
In the financial services industry, API-Based Integration connects trading systems with risk management platforms. This integration supports real-time risk assessment and decision-making.
Example 2: Retail
In the retail sector, API-Based Integration links e-commerce platforms with inventory management systems. This integration provides real-time inventory updates and improves customer experience.
Data Integration Patterns: Data Mesh
Definition and Overview
Data Mesh represents a paradigm shift in data architecture. This pattern decentralizes data ownership and management across various domains within an organization. Each domain becomes responsible for its data, treating it as a product. Data Mesh aims to address the limitations of traditional centralized data architectures.
Key Characteristics
Domain-Oriented Decentralization: Each business domain manages its data independently.
Data as a Product: Domains treat their data as products, ensuring high quality and usability.
Self-Serve Data Infrastructure: Provides tools and platforms for domains to manage their data autonomously.
Federated Governance: Implements governance policies across domains to ensure compliance and standardization.
Benefits
Scalability: Decentralized management scales more effectively with growing data volumes.
Agility: Domains can quickly adapt to changing business needs without waiting for centralized teams.
Improved Data Quality: Treating data as a product ensures higher standards of quality and usability.
Enhanced Collaboration: Encourages collaboration between domains, leading to better data integration and insights.
Implementation Strategies
Tools and Technologies
Several tools and technologies facilitate Data Mesh implementation:
Databricks: Provides a unified analytics platform that supports decentralized data management.
Snowflake: Offers a cloud-based data platform that enables seamless data sharing and collaboration across domains.
Apache Kafka: Facilitates real-time data streaming and integration between different domains.
Best Practices
Implementing Data Mesh requires adherence to best practices:
Domain Expertise: Ensure each domain has the necessary expertise to manage its data effectively.
Data Cataloging: Maintain a comprehensive data catalog to facilitate data discovery and usage across domains.
Governance Framework: Establish a federated governance framework to enforce data policies and standards.
Continuous Monitoring: Implement monitoring tools to track data quality and performance across domains.
Case Studies
Example 1: Mall Group
Mall Group successfully implemented Data Mesh as part of its data strategy. The company decentralized data ownership across various business units. Each unit managed its data independently, ensuring high quality and usability.
Example 2: Gilead and Saxo Bank
Gilead and Saxo Bank adopted Data Mesh to empower their data strategies. Both organizations decentralized data management, allowing business units to handle their data autonomously. This approach led to better data integration and insights.
Data integration plays a vital role in modern enterprises, ensuring businesses can leverage their data for maximum value and insight. Future trends in data integration promise even greater capabilities and efficiencies as technologies and methodologies evolve.
Taking the factors above into consideration, FineDataLink is a great choice for data integration. Click the banner below to experience FineDataLink for free!