A Python pipeline is a method for organizing a series of operations to automate tasks or process data. Imagine it as a chain of pipes where each section performs a specific function. These pipelines streamline workflows by connecting data processing elements, making them efficient and repeatable. You can create and use pipelines to handle tasks like data transformationor machine learning. By using a pipeline, you reduce manual effort and improve productivity. This approach ensures faster results and greater consistency in your projects.
Pipelines play a key role in simplifying complex workflows and ensuring scalability.
Key Takeaways of Python Pipeline
Pipelines in Python help automate tasks and make workflows easier.
They usually have three steps: Input, Processing, and Output.
These steps keep data moving smoothly from start to finish.
Tools like FineDataLinkmake pipelines better with live data updates.
They also add features for handling and transforming data.
Libraries like Scikit-learn and Pandas help build pipelines faster.
Pipelines save time, grow with your needs, and can be reused.
This lets you spend more time learning from your data.
How Python Pipeline Works
Understanding the Structure of a Python Pipeline
A Python pipeline consists of a series of steps, each designed to perform a specific task. These steps are connected in a sequence, where the output of one step becomes the input for the next. This structure ensures a smooth flow of data or tasks from start to finish. You can think of it as an assembly line, where each station has a unique role in creating the final product.
To better understand this, consider the following key components of a typical pipeline:
Input Stage: This is where data enters the pipeline. It could come from files, databases, or APIs.
Processing Stage: Here, the data undergoes transformations like cleaning, filtering, or aggregating.
Output Stage: The final processed data is stored or used for further analysis.
Tools like Jupyter Notebook and collaborative platforms such as GitHub enhance the reproducibility of pipelines by combining code, narrative, and output in a single environment. This makes it easier for others to replicate your work.
Workflow of a Python Pipeline: Input, Processing, and Output
The workflow of a Python pipeline follows a clear and logical sequence. It begins with collecting raw data, processes it through a series of steps, and ends with delivering the desired output. Let’s break it down:
Input: The pipeline starts by gathering data from various sources. For example, you might extract data from a CSV file, a database, or an API.
Processing: The data then moves through a series of transformations. This could include cleaning missing values, normalizing data, or applying machine learning algorithms.
Output: Finally, the processed data is stored in a database, visualized in a dashboard, or used to generate reports.
A well-designed pipeline ensures that each step is modular and reusable. This approach simplifies maintenance and allows you to adapt the pipeline to new requirements.
Bytewax, a Python library, structures dataflows as Directed Acyclic Graphs (DAGs). Each node represents a processing step, ensuring a clear sequence of operations from input to output.
Example of a Simple Python Pipeline
Let’s look at a practical example of a Python pipeline. Imagine you are analyzing web server logs to gain insights into website traffic. Here’s how you could build a simple pipeline:
Input: Read the log files line by line.
Processing:
Parse each line to extract fields like IP address, timestamp, and URL.
Filter out irrelevant entries, such as bot traffic.
Aggregate the data to calculate metrics like the number of unique visitors.
Output: Store the processed data in a SQLite database for further analysis.
import sqlite3
# Input: Read log file
with open('server_logs.txt', 'r') as file:
logs = file.readlines()
# Processing: Parse and filter logs
parsed_logs = []
for log in logs:
fields = log.split()
if "bot" not in fields:
parsed_logs.append((fields[0], fields[3], fields[6]))
# Output: Store in SQLite database
conn = sqlite3.connect('web_traffic.db')
cursor = conn.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS traffic (ip TEXT, timestamp TEXT, url TEXT)''')
cursor.executemany('INSERT INTO traffic VALUES (?, ?, ?)', parsed_logs)
conn.commit()
conn.close()
This pipeline reads the log file, processes the data to remove unwanted entries, and stores the results in a database. It demonstrates how pipelines can automate repetitive tasks and ensure data consistency.
A tutorial on Python pipelines highlights how parsing log files, creating database schemas, and inserting records can build robustdata pipelines. These pipelines are essential for analyzing performance metrics and ensuring data integrity.
Types of Python Pipeline
Data Processing Pipelines for ETL and Data Transformation
Data processing pipelines are essential for handling Extract, Transform, Load (ETL) tasks and data transformation. These pipelines allow you to automate the movement and transformation of data from various sources into a usable format. For instance, you can use them to clean raw data, convert formats, or aggregate information for analysis.
Modern ETL pipelines excel in performance due to advanced techniques:
Stream processing handles data as it arrives, enabling real-time data transformation.
Parallel processing with data sharding divides large datasets into smaller chunks, allowing simultaneous processing across multiple nodes.
Tools like Integrate.io automatically scale based on data volume, ensuring quick and reliable transformations.
These features make data pipelines in Python a powerful solution for managing large-scale data efficiently.
Machine Learning Pipelines for Model Training and Evaluation
Machine learning pipelines streamline the process of training and evaluating models. They connect tasks like data preprocessing, feature selection, model training, and validation into a seamless workflow. This approach ensures consistency and reduces manual intervention.
Benchmarks show that machine learning pipelines perform well under scalability tests. Systems maintain responsiveness even when workload capacity increases significantly. However, no single pipeline outperforms others across all datasets. The best pipeline depends on the dataset and evaluation metric. For example, the SCIPIO-86 dataset provides insights into pipeline performance across thousands of dataset-pipeline pairs, emphasizing the importance of tailored solutions.
Workflow Automation Pipelines for Task Scheduling
Workflow automation pipelines simplify task scheduling by automating repetitive processes. These pipelines are widely used in industries to save time and reduce errors. Companies like Coca-Cola Bottling Company and T-Mobile have successfully implemented automation tools to streamline operations. Coca-Cola, for instance, used automation to organize data sheets and monitor email systems, while T-Mobile processed requests without data errors.
Over 80% of business leaders report that automation speeds up work processes. By adopting workflow automation pipelines, you can enhance efficiency and focus on strategic tasks.
Tools and Libraries for Building Python Pipeline
When building pipelines, Python offers a variety of tools and libraries that simplify the process. These tools help you automate workflows, process data efficiently, and create seamless machine learning models. Below are three popular libraries that stand out for their unique capabilities.
Scikit-learn for Machine Learning Pipelines
Scikit-learn is a powerful library for creating machine learning pipelines. It supports both supervised and unsupervised learning, making it versatile for various tasks. With Scikit-learn, you can combine data preprocessing steps, feature selection, and model training into a single pipeline. This approach ensures consistency and reduces the chances of errors.
Here’s why Scikit-learn is a favorite among data scientists:
It provides tools for model fitting, data preprocessing, and evaluation.
Pipelines in Scikit-learn allow you to package transformation functions with classifiers or regressors. This simplifies your workflow.
You can treat the entire pipeline as a single entity, using methods like fit and predict.
For example, you can create a pipeline that scales your data, selects features, and trains a model in one go. This not only saves time but also ensures that every step is applied consistently during training and testing.
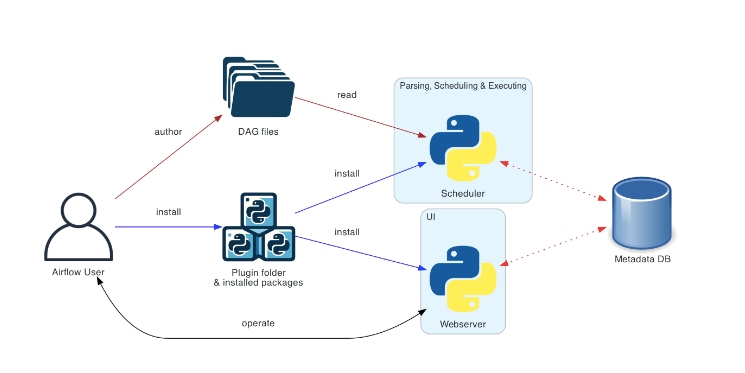
Apache Airflow for Workflow Automation
Apache Airflow is a robust tool for automating workflows. It helps you schedule and monitor tasks, making it ideal for managing complex pipelines. Airflow uses Directed Acyclic Graphs (DAGs) to define workflows, ensuring that tasks execute in the correct order.
Industries across the board rely on Apache Airflow for its efficiency:
Financial services use it for regulatory reporting and fraud detection.
Retail and eCommerce companies improve inventory management and power recommendation engines with Airflow.
Healthcare organizations automate medical data processing and diagnostics.
Manufacturing firms optimize production monitoring and quality control.
Airflow’s flexibility and scalability make it a go-to choice for workflow automation. Whether you’re managing a simple task or a multi-step process, Airflow ensures that everything runs smoothly.
Pandas for Data Processing Pipelines
Pandas is a must-have library for building data pipelines in Python. It simplifies data manipulationand analysis with its intuitive syntax. Whether you’re filtering, grouping, or transforming data, Pandas makes the process straightforward.
Key features of Pandas include:
Support for multiple file formats like CSV, Excel, JSON, and Parquet.
The ability to handle millions of rows efficiently when combined with optimization techniques.
Seamless integration with other Python libraries like NumPy, Matplotlib, and SQLAlchemy.
For instance, you can use Pandas to clean raw data, merge datasets, and prepare data for analysis. Its flexibility and performance make it an essential tool for handling large-scale data processing tasks.
Tip: Combine Pandas with other libraries to create powerful and efficient data pipelines.
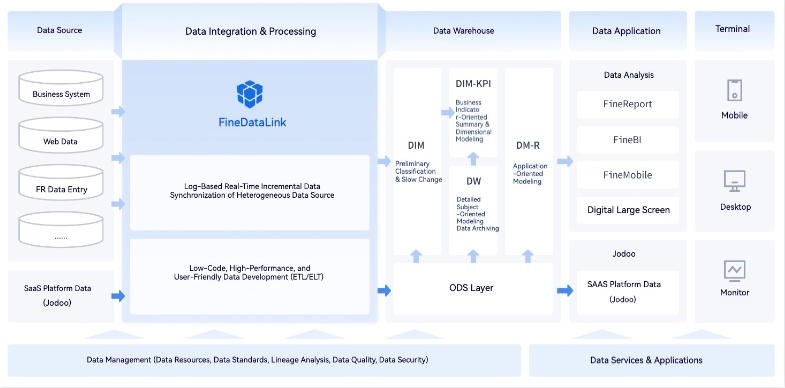
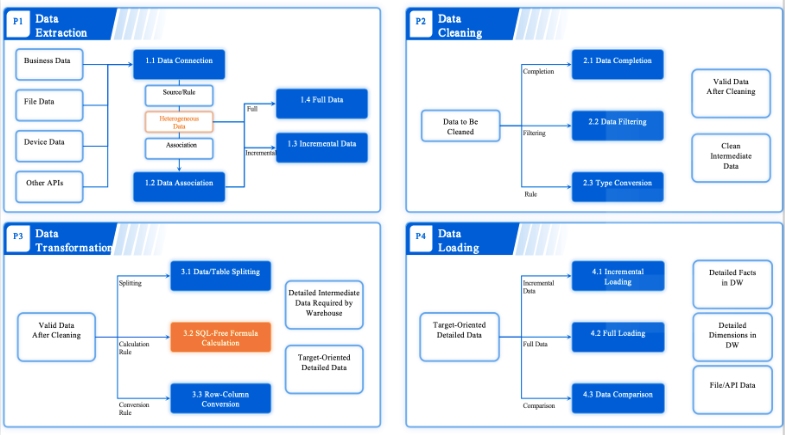
FineDataLink for Real-Time Data Integration and ETL
FineDataLink stands out as a robust platform for building real-time pipelines that handle data integration and ETL tasks with ease. It simplifies the process of connecting, transforming, and synchronizing data across multiple sources. Whether you are managing large datasets or working with complex systems, FineDataLink ensures seamless data flow and high efficiency.
Real-Time Data Synchronization
FineDataLink enables you to synchronize data in real time with minimal latency. This feature is especially useful when you need to keep multiple systems updated simultaneously. For example, you can use it to replicate data from a production database to a reporting database without delays. By doing so, you reduce the load on your primary database while ensuring that your reports always reflect the latest information.
Tip: Real-time synchronization is ideal for applications like live dashboards, where up-to-date data is critical for decision-making.
Advanced ETL Capabilities
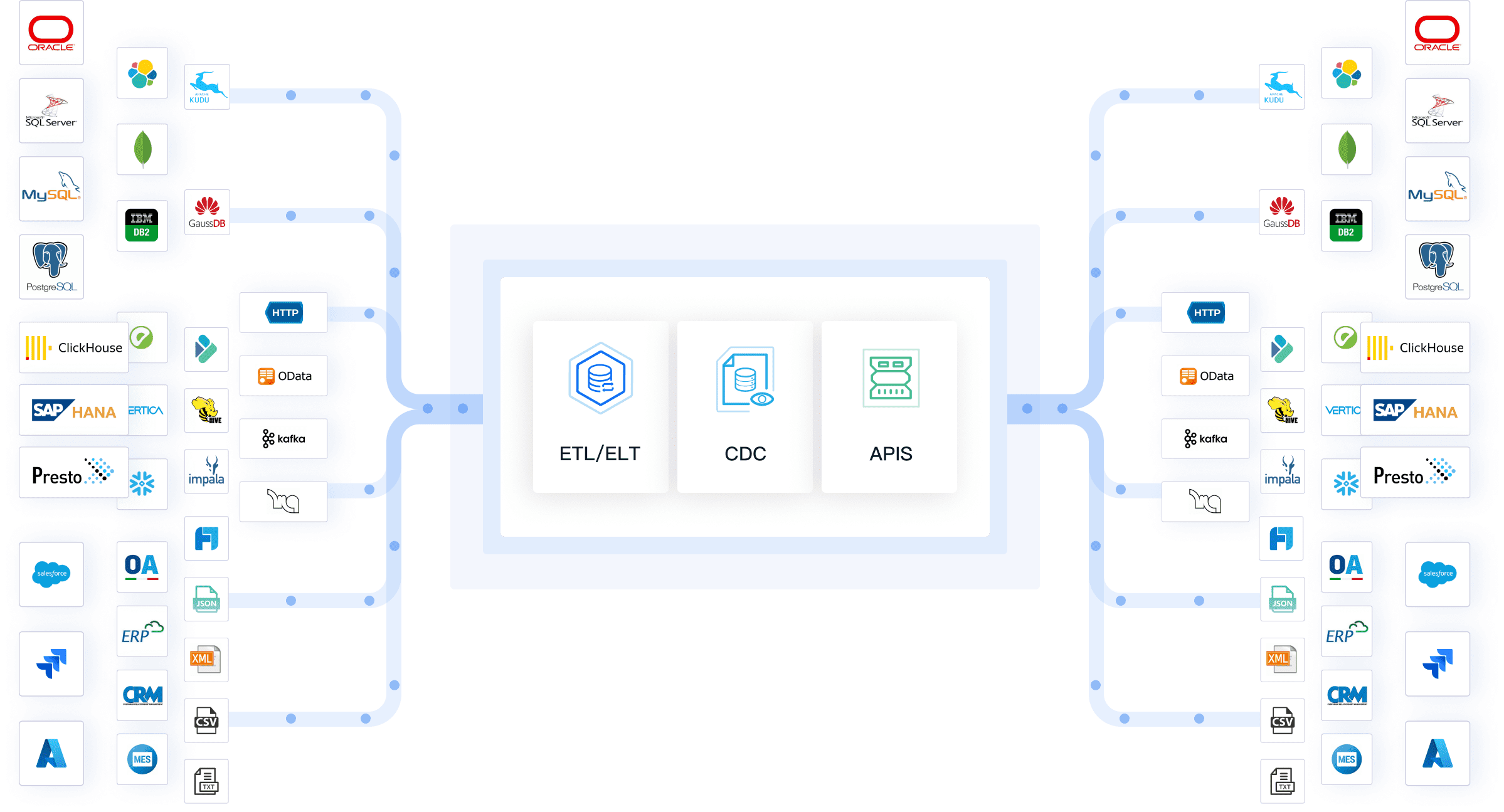
FineDataLink excels in automating ETL (Extract, Transform, Load) processes. It allows you to extract data from diverse sources, transform it into a usable format, and load it into your target system. The platform supports over 100 data sources, including databases, APIs, and cloud services. This flexibility makes it a powerful tool for creating pipelines tailored to your specific needs.
Here’s what you can achieve with FineDataLink’s ETL features:
Data Preprocessing: Clean and normalize raw data to improve its quality.
Data Transformation: Convert data into formats compatible with your analysis tools.
Data Loading: Store the processed data in a data warehouse or other storage systems.
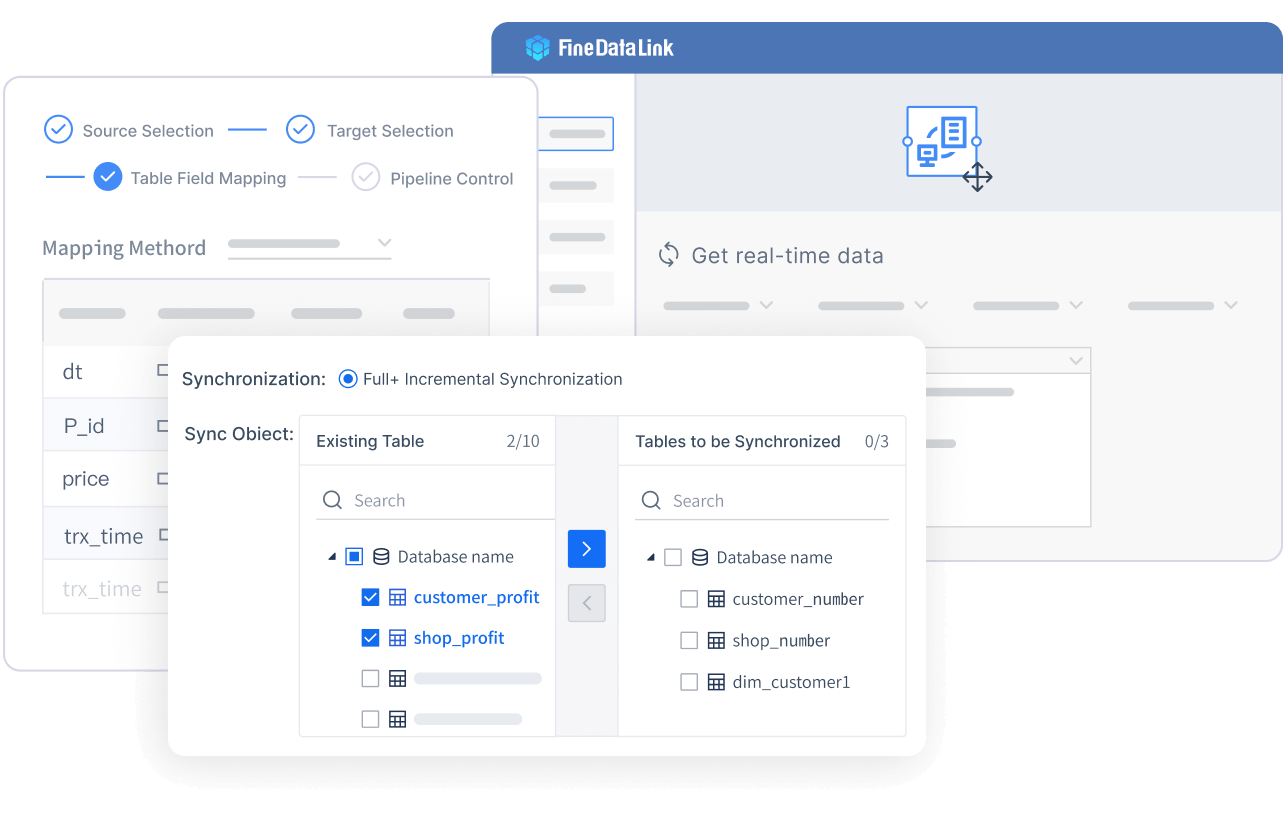
Low-Code Interface for Simplicity
FineDataLink’s low-code interface makes it accessible even if you have limited programming experience. Its drag-and-drop functionality allows you to design pipelines visually, reducing the need for manual coding. This feature not only saves time but also minimizes errors, making your workflows more reliable.
Why Choose FineDataLink?
FineDataLink offers several advantages that set it apart from other tools:
Scalability: Handle large volumes of data without compromising performance.
Real-Time Monitoring: Track the status of your pipelines and resolve issues quickly.
API Integration: Share data between systems effortlessly by creating APIs in minutes.
By using FineDataLink, you can build efficient pipelines that streamline your data integration processes. Its combination of real-time synchronization, advanced ETL capabilities, and user-friendly design makes it an essential tool for modern data workflows.
FineDataLinkempowers you to overcome challenges like data silos and manual ETL processes. It helps you focus on deriving insights rather than managing data complexities. Click the banner and start your journey with it.
Benefits of Using Python Pipeline
Enhanced Efficiency and Scalability
Python pipelines significantly enhance efficiency and scalability in data workflows. By automating repetitive tasks, you can save time and focus on more strategic activities. Optimizing Python code further boosts performance. For instance, techniques like vectorized operations and efficient data loading reduce processing time. Libraries such as NumPy and Pandas enable you to handle complex data transformations with ease. Lazy evaluation tools like Vaex or Polars allow you to process large datasets efficiently without overloading your system.
Here’s a quick comparison of Python pipelines' advantages over traditional scripts:
Advantage
Description
Flexibility
Python's libraries allow for high customization in data pipeline design.
Integration Capabilities
Seamless integration with various systems and platforms, enhancing data ecosystem compatibility.
Advanced Data Processing
Utilizes powerful libraries like Pandas and NumPy for complex data transformations and analyses.
These features make Python pipelines a robust solution for handling large-scale data workflows while maintaining high performance.
Tip: Use libraries like Pandas and NumPy to optimize your pipelines for better scalability.
Improved Reproducibility and Automation
Python pipelines improve reproducibility by ensuring consistent results across different environments. Automating dependency installation and capturing pipelines as container images eliminate hidden dependencies. This approach ensures that your workflows produce the same output, regardless of the system used. Tools like Snakemake, which integrate seamlessly with Python, offer flexible workflow configurations. These configurations are essential for maintaining reproducibility in automation workflows.
Unlike systems like Galaxy and Taverna, which are better suited for routine tasks, Snakemake excels in exploratory analyses. Its lightweight nature and modular design make it a preferred choice for defining workflows. Ongoing development efforts further enhance its consistency and modularity, ensuring reliable results every time.
Automating your pipelines not only saves time but also ensures that your workflows are repeatable and error-free.
Real-Time Data Integration with FineDataLink
FineDataLink takes real-time data integrationto the next level. It allows you to synchronize data across multiple systems with minimal latency, typically measured in milliseconds. This capability is ideal for applications like live dashboards, where up-to-date information is critical. By reducing the load on your primary database, FineDataLink ensures smooth operations without compromising performance.
The platform also simplifies ETL processes. You can extract data from diverse sources, transform it into usable formats, and load it into your target system effortlessly. Its low-code interface makes pipeline creation accessible, even for users with limited programming experience. Drag-and-drop functionality minimizes errors and speeds up development.
FineDataLink’s scalability and real-time monitoring features make it a powerful tool for modern data workflows. Whether you’re managing large datasets or integrating APIs, it ensures seamless data flow and high efficiency.
FineDataLink empowers you to overcome challenges like data silos and manual ETL processes, enabling you to focus on deriving insights.
Real-World Applications of Python Pipeline
Data Engineering: ETL Processes and Data Warehousing
Data pipelines play a vital role in data engineering, especially for ETL (Extract, Transform, Load) processes and data warehousing. These pipelines automate the movement of data from multiple sources into a centralized system, ensuring it is clean, accurate, and ready for analysis. For example, e-commerce platforms rely on ETL pipelines to enhance operational efficiency and improve customer experiences. By integrating data from various sources, these platforms can analyze trends, optimize inventory, and personalize recommendations.
Different industries benefit from data pipelines in unique ways:
Industry
Impact of Data Pipelines
Finance
Real-time transaction monitoring, fraud detection, and personalized banking experiences.
Retail
Enhanced inventory tracking, AI-driven recommendations, and optimized pricing models.
Healthcare
Improved patient record management, predictive analytics, and real-time monitoring.
Manufacturing
Predictive maintenance, optimized production planning, and quality control automation.
Telecommunications
Improved network performance, fraud detection, and personalized customer interactions.
These examples highlight how pipelines ensure seamless data integration and drive innovation across sectors.
Machine Learning: End-to-End ML Workflows
Machine learning pipelines simplify the process of building and deploying models. They connect tasks like data preprocessing, feature selection, model training, and evaluation into a single workflow. For instance, you can use Scikit-learn to automate the entire process, from exploring data to generating predictions. This approach improves efficiency and ensures consistency.
A practical example involves comparing a linear regression model with a random forest regressor. The latter often performs better due to its ability to handle complex patterns. Tools like Kubeflow also allow you to construct end-to-end pipelines, enabling hands-on learning and scalability. Additionally, validating data during ingestion prevents issues during model training. Platforms like AWS Kinesis and Apache Spark excel in handling large datasets, making them ideal for machine learning workflows.
Enterprise Solutions: Real-Time Data Integration with FineDataLink
FineDataLink revolutionizes enterprise data workflows by enabling real-time data integration. Its pipelines synchronize data across systems with minimal latency, ensuring up-to-date information for decision-making. For example, you can replicate data from a production database to a reporting system without delays. This reduces the load on primary databases while maintaining operational efficiency.
The platform’s advanced ETL capabilities allow you to extract, transform, and load data from over 100 sources. Its low-code interface simplifies pipeline creation, making it accessible to users with limited programming experience. Features like drag-and-drop functionality and real-time monitoring enhance productivity and reliability. FineDataLink empowers organizations to overcome challenges like data silos and manual ETL processes, enabling them to focus on deriving actionable insights.
FineDataLink’s scalability and user-friendly design make it an essential tool for modern enterprises seeking efficient data pipelines.
Pipelines in Python simplify workflows by automating tasks and ensuring consistency. They help you process data efficiently, making them essential for modern data-driven projects. Tools like FineDataLink enhance these workflows by offering real-time synchronization, advanced ETL capabilities, and user-friendly interfaces. These features make it easier for you to build scalable and efficient pipelines.
Advantage
Description
Efficiency
No-code solutions speed up the process of creating data pipelines, allowing you to focus on insights.
Accessibility
User-friendly interfaces let non-technical users design pipelines with drag-and-drop simplicity.
Management & Monitoring
Built-in tools help you monitor and manage pipelines effectively, ensuring smooth operations.
Explore Python pipelines to unlock their full potential. Integrating tools like FineDataLink into your workflows can transform how you handle data, making your processes faster and more reliable.
Click the banner below to try FineDataLink for free and empower your enterprise to transform data into productivity!
A Python pipeline automates tasks and processes data efficiently. It connects multiple steps into a sequence, ensuring smooth data flow from input to output. You can use pipelines to save time, reduce errors, and improve consistency in workflows.
How does FineDataLink simplify pipeline creation?
FineDataLink offers a low-code interface with drag-and-drop functionality. You can design pipelines visually without writing complex code. It supports real-time data synchronization and advanced ETL processes, making it easy to integrate and transform data across multiple sources.
Can Python pipelines handle real-time data?
Yes, Python pipelines can process real-time data using tools like FineDataLink. It synchronizes data across systems with minimal latency. This feature is ideal for applications like live dashboards or real-time analytics, where up-to-date information is critical.
What are the benefits of using Python pipelines for machine learning?
Python pipelines streamline machine learning workflows by automating tasks like data preprocessing, model training, and evaluation. Tools like Scikit-learn allow you to package these steps into a single pipeline, ensuring consistency and reducing manual effort.
Is FineDataLink suitable for beginners?
FineDataLink is beginner-friendly due to its low-code platform. Its visual interface simplifies pipeline creation, allowing users with limited programming experience to build efficient workflows. You can also access detailed documentation and instructional videos for guidance.
Product Trial
FineReport
Pixel-perfect reports · Interactive dashboards · Easy data entry · Digital twins