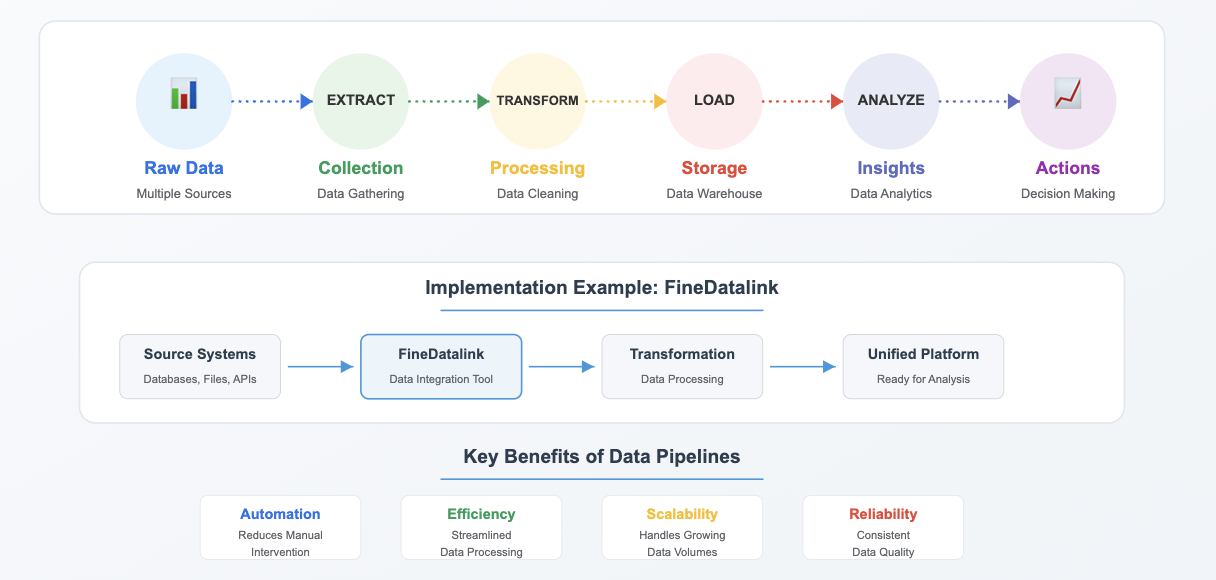
A data pipeline is a system that moves data from one place to another while transforming it into a usable format, with various data pipeline examples illustrating its functionality. It automates the flow of information, ensuring that raw data becomes actionable insights without manual intervention. For example, tools like FineDatalink simplify this process by connecting various data sources and enabling seamless integration.
Automation plays a key role in modern data pipelines, as seen in numerous data pipeline examples. It reduces manual effort, minimizes errors, and ensures consistent data quality. Built-in checks validate data at every stage, making pipelines reliable and efficient. With the rise of real-time processing and cloud-native solutions, data pipelines have become essential for industries like finance, healthcare, and media. They empower you to make faster, data-driven decisions.
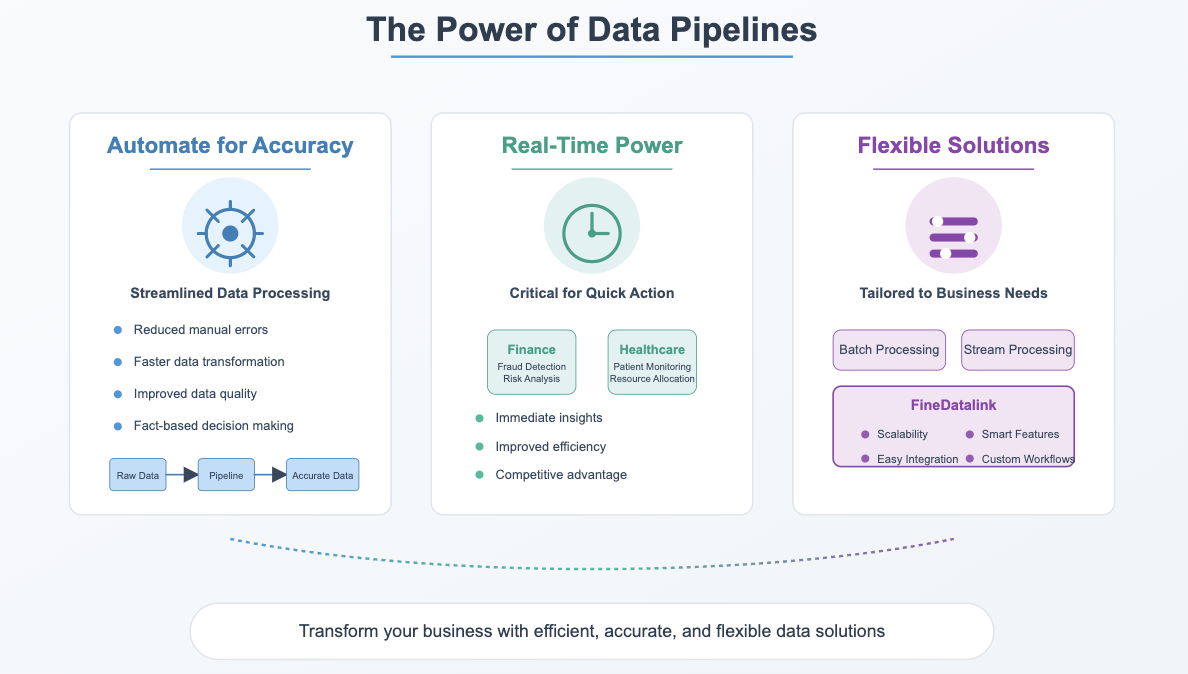
Key Takeaways on Data Pipeline Examples
Automate for Accuracy: Data pipelines streamline data movement and transformation, reducing errors and enabling faster, fact-based decisions.
Real-Time Power: Real-time data pipelines are crucial for industries like finance and healthcare, ensuring quick actions and improved efficiency.
Flexible Solutions: From batch to streaming, data pipelines can be tailored to business needs, with tools like FineDatalink offering scalability and smart features.
What Is a Data Pipeline?
Definition and Purpose
A data pipeline is a system that automates the movement of data from its source to a destination, such as a database or analytics platform. Along the way, it transforms and optimizes the data, making it ready for analysis and decision-making. Think of it as a conveyor belt that ensures data flows smoothly and efficiently, eliminating the need for manual handling. This process is essential for businesses aiming to extract actionable insights from their data.
The primary purposes of a data pipeline include automating data collection, ensuring data quality through validation checks, and enabling real-time analytics. For example, FineDatalink simplifies these tasks by integrating data from multiple sources into a unified format, making it easier for you to analyze and act on the information.
Key Components
Data Ingestion
Data ingestion is the first step in a data pipeline. It involves collecting data from various sources, such as databases, APIs, or IoT devices. This step can occur in real-time or in batches, depending on your needs. Tools like FineDatalink excel in this area by offering seamless connectivity to diverse data sources, ensuring no valuable information is left behind.
Data Transformation
Once ingested, the data often requires cleaning and transformation to make it usable. This step includes removing duplicates, filling in missing values, and converting data into a consistent format. FineDatalink's robust transformation capabilities allow you to customize these processes, ensuring the data meets your specific requirements.
Data Storage
The final step is storing the processed data in a destination system, such as a cloud database or data warehouse. This storage ensures the data is readily available for analysis, machine learning, or reporting. FineDatalink supports various storage options, offering flexibility and scalability to meet your growing data needs.
Importance of Data Pipelines in 2026
By 2025, the global data volume is expected to reach 175 zettabytes, driven by IoT devices, cloud computing, and digital transformation. Managing this massive influx of data will require efficient and scalable solutions like data pipelines. These systems will play a critical role in enabling real-time analytics, supporting AI and machine learning, and ensuring data quality and governance.
Emerging trends, such as the rise of real-time data pipelines and the integration of AI, will further enhance their capabilities. FineDatalink, with its advanced features and user-friendly interface, is well-positioned to help you navigate these challenges and opportunities. Its ability to automate and optimize data processes makes it an invaluable tool for businesses looking to stay ahead in the data-driven era.
The Benefits: Learning from Data Pipeline Examples
Streamlined Data Management
Data pipelines simplify how you manage data by automating workflows and reducing manual intervention. This automation ensures efficiency and minimizes errors. For instance:
An e-commerce company uses a data pipeline to collect customer behavior data in real time. It analyzes purchasing patterns and delivers personalized product recommendations.
A bank employs a streaming data pipeline to monitor transactions across its network. It applies machine learning models to detect and prevent potential fraudulent activity instantly.
A social media platform aggregates user data through a real-time data pipeline. It analyzes engagement metrics and optimizes content delivery for a better user experience.
FineDatalink excels in streamlining the data pipeline process. Its seamless integration capabilities allow you to connect diverse data sources effortlessly. By automating repetitive tasks, FineDatalink frees up your time to focus on deriving insights and making strategic decisions.
Improved Data Quality and Accessibility
Data pipelines enhance data quality by automating collection and validation processes. They ensure reliable datasets and integrate disparate sources, breaking down silos. For example, McDonald's uses a data pipeline to aggregate data from franchise locations into a single platform. This integration enables them to analyze sales performance and customer preferences effectively.
FineDatalink plays a pivotal role in improving data accessibility. Its robust features allow you to unify data from multiple sources into a consistent format. This accessibility ensures that your team can make timely, informed decisions. With real-time processing, you can respond to changes faster, enhancing operational efficiency.
Scalability for Big Data
Handling big data requires scalable solutions. Data pipelines built on cloud platforms like AWS, Azure, or Google Cloud provide elasticity, allowing you to scale resources based on demand. Distributed systems such as Apache Kafka and Snowflake enable real-time processing and storage of massive datasets. Automation tools like Apache Airflow enhance pipeline management, ensuring reliability.
FineDatalink's cloud-native architecture ensures scalability for growing data needs. It adapts to increasing data volumes and integrates with machine learning for predictive resource management. By 2026, as data volumes continue to grow, scalable data pipelines will become indispensable for businesses aiming to stay competitive.
Real-Time Insights and Decision-Making
In today’s fast-paced world, making decisions quickly can give you a significant advantage. A well-designed data pipeline ensures that you have access to real-time information, enabling you to respond to changes as they happen. For instance, businesses can monitor customer behavior, market trends, or operational metrics without delay. This capability allows you to make informed decisions that keep you ahead of the competition.
AI-powered data engineering has transformed how data pipelines operate. By integrating AI-driven automation, you can build smarter and more scalable systems. These pipelines process data continuously, ensuring that insights are generated almost instantly. This means you can react dynamically to business changes, whether it’s adjusting inventory levels or launching targeted marketing campaigns. FineDatalink excels in this area by offering advanced automation features that streamline workflows and enhance data governance.
A successful data pipeline must load, transform, and analyze data in near real time. This process involves ingesting data from various sources, cleaning it, and delivering it to analytics platforms without delay. For example, a streaming platform might use a data pipeline to analyze viewer preferences in real time, ensuring that recommendations are always relevant. FineDatalink simplifies this process by providing seamless integration with diverse data sources, making it easier for you to act on insights quickly.
By 2026, the demand for real-time decision-making will only grow. Industries like healthcare and finance will rely heavily on real-time data pipelines to monitor patient health or detect fraudulent transactions. FineDatalink’s ability to handle large volumes of data efficiently positions it as a vital tool for businesses navigating this data-driven future. With its user-friendly interface and robust features, FineDatalink empowers you to make faster, smarter decisions.
Explained how it works through data pipeline examples
Data Ingestion Process
The data ingestion process is the first step in any data pipeline. It involves collecting raw data from various sources and preparing it for further processing. This step ensures that all necessary information enters the pipeline efficiently. A typical data ingestion process includes the following steps:
Data Collection: You gather data from multiple sources, such as databases, SaaS applications, or IoT devices.
Data Transfer: The collected data moves to a central system, like a data lake or warehouse, using batch or real-time ingestion methods.
Data Validation: You ensure the data is accurate, complete, and meets required standards.
Data Storage: The validated data is saved in a repository for analysis or reporting.
FineDatalink simplifies this process by offering seamless connectivity to diverse data sources. Its real-time ingestion capabilities ensure that no valuable information is missed, making it an excellent choice for businesses handling large volumes of data.
Data Transformation Steps
Once the data is ingested, it often requires transformation to make it usable. This step involves cleaning, structuring, and converting the data into a consistent format. Common methods for data transformation include:
ETL (Extract, Transform, Load): This traditional method extracts data, transforms it into a suitable format, and then loads it into a destination system. It works well for structured data processing.
ELT (Extract, Load, Transform): This modern approach loads raw data into the destination first and performs transformations afterward. It is highly effective for big data analytics.
FineDatalink excels in both ETL and ELT processes. Its robust transformation tools allow you to customize workflows, ensuring the data meets your specific requirements. By 2026, as data complexity grows, tools like FineDatalink will become indispensable for managing transformations efficiently.
Data Storage and Delivery
The final step in the data pipeline process involves storing and delivering the processed data. This ensures the data is ready for analysis, reporting, or machine learning applications. A typical workflow includes:
Ingestion: Data enters the pipeline from various sources.
Processing: The data undergoes transformation, cleansing, and aggregation.
Storage: The processed data is stored in a database, data warehouse, or cloud storage.
Analysis: Analytical tools extract insights from the stored data.
Visualization: The results are presented visually for easier interpretation.
FineDatalink supports multiple storage options, offering flexibility and scalability. Its integration with cloud platforms ensures that your data remains accessible and secure. By leveraging FineDatalink, you can streamline the entire data pipeline process, from ingestion to delivery, enabling faster decision-making and improved operational efficiency.
Automation and Monitoring Features
Automation and monitoring are essential for a robust data pipeline process. These features ensure your pipelines operate efficiently, detect issues early, and adapt to growing data demands. By automating repetitive tasks and providing real-time visibility, you can focus on deriving insights rather than managing technical complexities.
Modern data pipelines rely on several key automation and monitoring capabilities:
Automated alerts notify your team when thresholds are breached or issues arise, allowing you to act quickly.
Real-time monitoring provides up-to-the-minute visibility into data flows and pipeline performance.
Anomaly detection identifies unusual patterns or deviations in data, flagging potential problems before they escalate.
Scalability ensures your monitoring tools grow with your data, maintaining performance even as workloads increase.
Detailed reporting and analytics offer insights into pipeline health, helping you make informed decisions.
Integration capabilities enhance usability by connecting seamlessly with other tools in your tech stack.
FineDatalink excels in these areas by offering advanced automation and monitoring features. Its real-time analytics capabilities enable you to process and update data continuously, ensuring timely insights. The platform’s fault-tolerant architecture minimizes downtime by providing immediate failover and robust alerts. With FineDatalink, you can also leverage exactly-once processing (E1P) to maintain data integrity, a critical feature for industries like finance and healthcare.
Looking ahead to 2026, automation and monitoring will become even more sophisticated. AI-driven anomaly detection will predict issues before they occur, while self-service management tools will empower you to customize pipelines without extensive technical expertise. FineDatalink’s scalable cloud-based architecture positions it as a future-ready solution, capable of handling the increasing complexity of data pipeline examples across industries.
By integrating these features into your data pipeline process, you can ensure seamless operations, reduce risks, and unlock the full potential of your data.
Exploring Data Pipeline Examples
Batch Processing Pipelines
Batch processing pipelines handle data in large, discrete chunks at scheduled intervals. These pipelines work best when immediate results are not required. For example, you might use them to generate daily sales reports or process historical data for trend analysis. Their simplicity and cost-effectiveness make them a popular choice for many businesses.
Key characteristics of batch processing pipelines include:
Processing data in batches rather than continuously.
Components like data sources, workflow orchestration, and error handling ensure smooth operations.
FineDatalink enhances batch processing by automating workflows and integrating seamlessly with diverse data sources. Its robust validation tools ensure data accuracy, making it easier for you to trust the insights generated. By 2026, batch pipelines will remain essential for tasks like archiving and long-term data analysis, especially as data volumes grow.
Streaming Data Pipelines
Streaming data pipelines continuously process and analyze real-time data streams. These pipelines are perfect for scenarios where immediate insights are critical. For instance, you can use them to monitor customer behavior on your website or detect fraudulent transactions in financial systems.
Key features of streaming pipelines include:
Continuous ingestion and processing of real-time data.
Automated data cleaning to maintain pipeline integrity.
Use of edge computing to reduce latency and enable instant decision-making.
FineDatalink excels in real-time data processing by offering advanced automation and monitoring features. Its ability to handle high-speed data streams ensures you can act on insights without delay. As industries increasingly rely on real-time analytics, streaming pipelines will become indispensable for staying competitive in 2026.
Hybrid Pipelines
Hybrid pipelines combine the strengths of batch and streaming processes, offering flexibility and cost-efficiency. These pipelines allow you to choose the best method for each task. For example, you can use batch processing for archiving historical data and streaming for real-time analytics.
Key benefits of hybrid pipelines include:
Versatility to handle varying data processing needs.
Cost savings by balancing real-time insights with resource management.
Flexibility to adapt to different business scenarios.
FineDatalink supports hybrid pipelines by integrating batch and streaming capabilities into a single platform. This versatility ensures you can optimize your data workflows without switching between tools. As data complexity increases, hybrid pipelines will play a crucial role in meeting diverse business requirements.
By leveraging these data pipeline examples, you can streamline operations, improve decision-making, and prepare for the data-driven future. FineDatalink’s innovative features position it as a reliable partner in building efficient pipelines tailored to your needs.
Practical Use Cases for Each Type
Understanding how different types of data pipelines work can help you choose the right one for your needs. Each type serves specific purposes and excels in unique scenarios. Here are some practical use cases for each:
Batch Processing Pipelines: These pipelines are ideal for tasks that don’t require immediate results. For example, you can use them to process historical data periodically, such as generating monthly sales reports or analyzing customer trends. Businesses often rely on batch processing to move data into cloud data warehouses for business intelligence. FineDatalink simplifies this process by automating workflows and ensuring data accuracy, making it easier for you to extract insights from large datasets.
Streaming Data Pipelines: Streaming pipelines continuously process events from various sources, making them perfect for real-time analytics. For instance, you can use them to monitor social media activity or analyze IoT sensor data. These pipelines are also crucial for fraud detection, where instant insights can prevent financial losses. FineDatalink’s real-time processing capabilities allow you to act on data as it flows, ensuring you stay ahead of fast-changing conditions.
Real-Time Processing Pipelines: Real-time pipelines enable immediate responses to dynamic situations. They are essential for applications like social media monitoring, where trends can shift rapidly, or fraud detection systems that need to flag suspicious activities instantly. FineDatalink’s advanced automation features ensure seamless real-time data handling, empowering you to make swift, informed decisions.
Data Integration Pipelines: These pipelines merge data from multiple sources into a unified view, which is vital for handling incompatible formats. For example, you can use them to consolidate data from different departments into a single dashboard for better decision-making. FineDatalink excels in this area by offering robust integration tools that simplify the process, ensuring your data is consistent and accessible.
By 2026, the demand for these pipelines will grow as businesses handle increasingly complex data. Tools like FineDatalink will play a pivotal role in managing this complexity, offering scalable and efficient solutions tailored to your needs. Whether you’re processing historical data or analyzing real-time events, FineDatalink ensures your data pipeline examples are future-ready.
Data Pipelines vs. ETL Pipelines with Data Pipeline Examples
Key Differences
Understanding the differences between data pipelines and ETL pipelines helps you choose the right tool for your needs. While both manage data workflows, they serve distinct purposes. Data pipelines focus on the continuous flow of data, while ETL pipelines are designed for batch processing and loading data into a centralized warehouse.
Aspect
ETL
Data pipeline
Purpose
Designed for batch processing and integration into data warehouses.
Aimed at continuous data flow for various purposes beyond data warehouses.
Process flow
Follows a scheduled sequence: Extract, Transform, Load.
Handles real-time or batch data with flexible steps, often skipping transformation.
Latency
Higher latency due to batch processing.
Lower latency with real-time processing options.
FineDatalink bridges the gap between these approaches. It supports both batch and real-time workflows, making it versatile for businesses with diverse needs. By 2026, the demand for real-time data pipelines will grow as industries prioritize immediate insights over traditional batch processing.
Choosing Between Data Pipelines and ETL Pipelines
Selecting between a data pipeline and an ETL pipeline depends on your specific requirements. If you need to process structured data at regular intervals, an ETL pipeline might be the better choice. However, if your data is unstructured or requires real-time processing, a data pipeline offers more flexibility.
Factor
ETL Consideration
Data Pipeline Consideration
Data processing timeframe
Suitable for batch processing at set intervals.
Ideal for real-time or near-real-time processing.
Data complexity
Works well with structured, consistent data.
Better for high-velocity, diverse, or unstructured data.
Scalability
May require more effort to scale and maintain.
Generally more scalable and easier to maintain.
Cost considerations
Cost-effective for predictable, regular processing needs.
Potentially more costly but offers high functionality.
FineDatalink excels in both scenarios. Its cloud-native architecture ensures scalability, whether you’re handling batch ETL processes or real-time data pipelines. For example, you can use FineDatalink to integrate data from IoT devices in real time or consolidate historical data for reporting. This flexibility makes it a future-ready solution for businesses navigating the complexities of modern data workflows.
By 2026, organizations will increasingly adopt hybrid approaches, combining the strengths of ETL and data pipelines. FineDatalink’s ability to support both ensures you stay ahead of evolving data trends.
Real-World Data Pipeline Examples in 2026
E-commerce: Personalization and Recommendations
In e-commerce, data pipelines have revolutionized how businesses deliver personalized experiences. Companies like Amazon and Wayfair use data pipelines to analyze customer behavior and provide tailored product recommendations. These pipelines process vast amounts of data, such as browsing history, purchase patterns, and user preferences, to create a seamless shopping experience.
For example:
Data is ingested from sources like user activity logs and customer profiles.
The pipeline processes this data using machine learning algorithms to identify patterns.
Personalized recommendations are then generated and displayed to users in real time.
FineDatalink enhances this process by offering robust integration with diverse data sources and real-time analytics capabilities. Its ability to handle large-scale data ingestion and transformation ensures that your e-commerce platform can deliver accurate, timely recommendations. By 2026, as customer expectations grow, data pipelines will play an even greater role in micro-segmentation and hyper-personalization.
Healthcare: Real-Time Patient Monitoring
Data pipelines are transforming healthcare by enabling real-time patient monitoring. They integrate data from electronic health records, wearable devices, and other systems into a centralized platform. This integration allows medical professionals to monitor patient metrics continuously and respond promptly to health risks.
For instance, a data pipeline collects data from wearable health devices, cleans and organizes it, and calculates critical health metrics. The processed data is then displayed on a dashboard, giving healthcare providers instant access to vital information. FineDatalink’s real-time processing capabilities make it an ideal choice for such applications. Its fault-tolerant architecture ensures uninterrupted data flow, which is crucial for patient safety. By 2026, advancements in AI-powered pipelines will further enhance predictive healthcare, allowing you to identify potential issues before they escalate.
Finance: Fraud Detection and Risk Analysis
In finance, data pipelines are essential for fraud detection and risk analysis. They continuously collect transactional data from debit and credit card systems, customer profiles, and behavioral data. The pipeline processes this information to identify unusual patterns, such as sudden large transactions or purchases in high-risk areas.
Key steps include:
Ingesting transaction data in real time.
Applying machine learning models to flag suspicious activities.
Scoring each transaction’s fraud risk and sending high-risk cases to a dashboard for review.
FineDatalink excels in this domain by offering advanced automation and monitoring features. Its ability to process data in real time ensures that fraudulent activities are detected and addressed immediately. As financial systems become more complex by 2026, data pipelines will remain critical for maintaining security and trust.
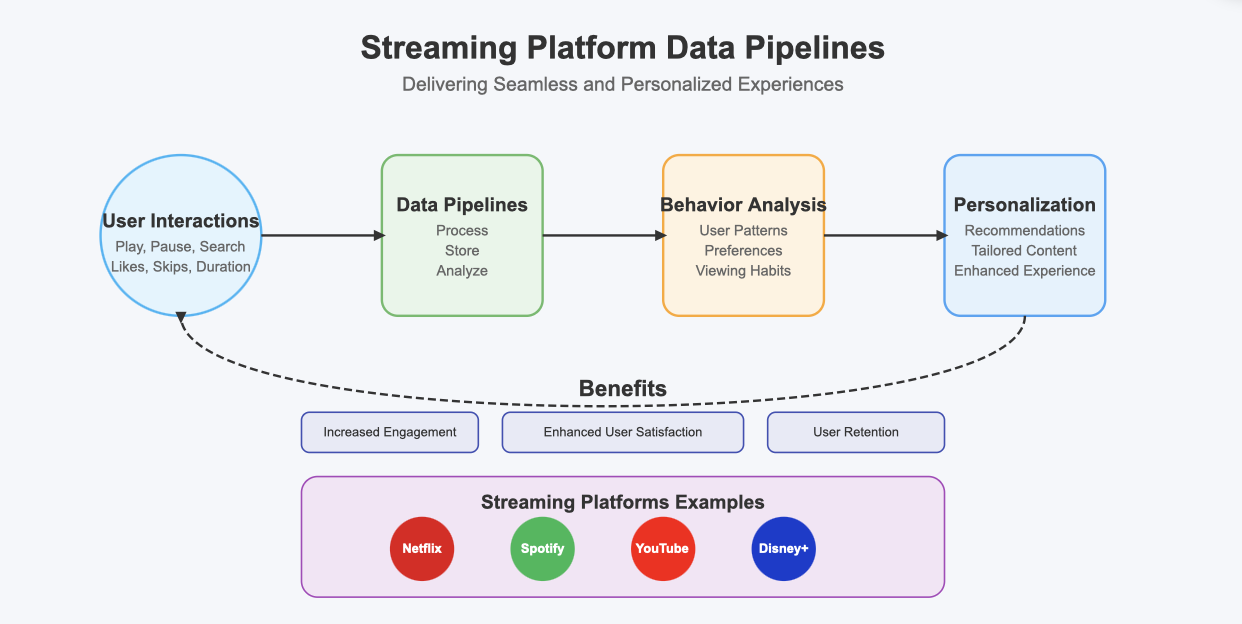
Media: Streaming Platforms and Content Delivery
Streaming platforms rely on data pipelines to deliver seamless and personalized experiences. These pipelines process vast amounts of data generated by user interactions, such as play, pause, and search actions. For example, services like Netflix and Spotify use this data to analyze user behavior and create tailored recommendations. This ensures that you always find content that matches your preferences.
A well-designed data pipeline enables real-time processing of user data. It collects information from active sessions, processes it, and updates user profiles instantly. This allows streaming platforms to adjust their content offerings based on viewer engagement patterns. FineDatalink excels in this area by providing robust real-time analytics capabilities. Its ability to handle high-speed data streams ensures that platforms can deliver accurate recommendations without delays.
Data pipelines also play a critical role in optimizing content delivery. They help platforms decide which content to cache closer to users, reducing buffering times and improving playback quality. For instance, a cloud data lake can store processed data, making it accessible for analysis and decision-making. FineDatalink’s seamless integration with cloud storage solutions ensures that your data remains secure and readily available.
By 2026, advancements in AI will further enhance data pipelines for streaming platforms. Predictive algorithms will analyze trends and forecast viewer preferences, enabling platforms to curate content proactively. FineDatalink’s scalable architecture positions it as a future-ready solution for these evolving needs. Its ability to automate complex workflows ensures that you can focus on delivering exceptional user experiences.
Data pipeline examples like these highlight their importance in the media industry. They not only improve personalization but also enhance operational efficiency, ensuring that streaming platforms stay competitive in a rapidly changing landscape.
Data pipelines automate the flow of information, ensuring clean, consistent, and actionable data. They reduce manual tasks, enhance data quality, and provide scalability to meet growing demands. By integrating diverse data sources and enabling real-time insights, tools like FineDatalink empower you to make faster, informed decisions.
Key Benefits of Data Pipelines:
Automate repetitive workflows, saving time and resources.
Ensure high-quality data through validation and error handling.
Scale efficiently to handle increasing data volumes.
Enable real-time insights for immediate decision-making.
Different types of data pipelines serve unique purposes. For example:
Type of Data Pipeline
Description
Real-World Applications
Batch Processing Pipelines
Process large quantities of data in batches, suitable for non-real-time tasks.
Historical data processing, periodic computational tasks.
Real-Time Processing Pipelines
Process incoming data immediately for instant insights.
Fraud detection, social media monitoring, IoT analytics.
Data Streaming Pipelines
Continuously process events from various sources.
Event-driven applications, real-time analytics.
Data Integration Pipelines
Merge data from multiple sources into a unified view.
ETL processes for data warehousing and analytics.
By 2026, the importance of data pipelines will grow as businesses process unprecedented data volumes. Real-time processing will become essential for operational efficiency and competitive advantage. FineDatalink’s advanced automation and scalability make it a future-ready solution for navigating this data-driven era. Investing in robust data pipelines ensures you stay ahead in a fast-paced digital landscape.
Click the banner below to also experience FineDataLink for free and empower your enterprise to convert data into productivity!
Access a wealth of case studies, industry insights, and solution guides to accelerate digital transformation.
FAQ
What is the difference between batch and streaming data pipelines?
Batch pipelines process data in chunks at scheduled intervals, while streaming pipelines handle continuous data flows in real time. For example, batch pipelines work well for monthly reports, whereas streaming pipelines excel in real-time fraud detection. FineDatalink supports both, offering flexibility for diverse business needs.
How do data pipelines improve decision-making?
Data pipelines automate data collection, transformation, and delivery, ensuring you have accurate, real-time insights. For instance, e-commerce platforms use data pipeline examples to analyze customer behavior and personalize recommendations. FineDatalink’s real-time analytics capabilities empower you to make faster, data-driven decisions.
Can data pipelines handle unstructured data?
Yes, modern data pipelines can process unstructured data like images, videos, and text. Tools like FineDatalink integrate seamlessly with diverse data sources, ensuring compatibility. By 2025, advancements in AI will further enhance the ability to process unstructured data efficiently, making pipelines even more versatile.
Why are data pipelines essential for big data?
Big data requires scalable solutions to manage its volume, velocity, and variety. Data pipelines streamline workflows, ensuring efficient processing and storage. FineDatalink’s cloud-native architecture scales effortlessly, making it ideal for handling large datasets. By 2025, scalable pipelines will be critical for businesses to stay competitive.
How do automation and monitoring enhance data pipelines?
Automation reduces manual tasks, while monitoring ensures pipeline reliability. Features like real-time alerts and anomaly detection improve efficiency. FineDatalink excels in these areas, offering advanced automation and monitoring tools. These capabilities help you maintain seamless operations and adapt to growing data demands.