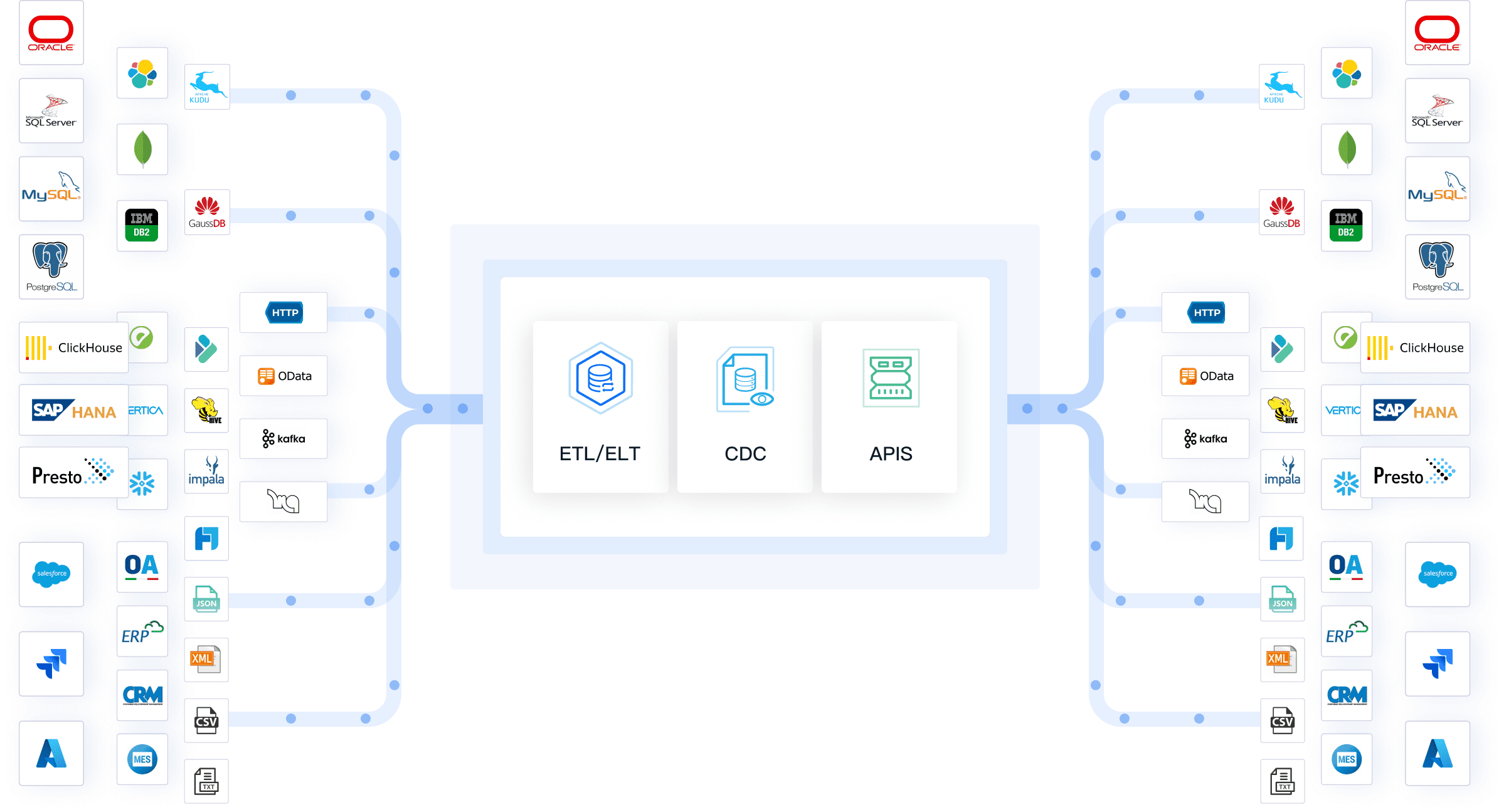
Data pipelines play a crucial role in modern data analytics. They allow businesses to integrate data from various sources and transform it for analysis. This integration removes data silos, making analytics more reliable and accurate. Modern data pipelines enable organizations to unlock data quickly and efficiently, facilitating insightful decision-making.
Apache Spark, maintained by the Apache Software Foundation, is a powerful tool for building data pipelines. It serves as a unified engine for large-scale data processing. Spark's flexibility allows it to operate on single-node machines and large clusters. Its native support for in-memory distributed processing and fault tolerance makes it ideal for complex, multi-stage data pipelines.
Setting Up the Environment for Spark Data Pipeline
Prerequisites of Spark Data Pipeline
Software and Hardware Requirements
To build a Spark data pipeline, ensure the system meets specific software and hardware requirements. A modern multi-core processor with at least 8 GB of RAM is recommended. For larger datasets, consider using a cluster of machines. The operating system should be a Unix-based system like Linux or macOS. Windows users can use Windows Subsystem for Linux (WSL).
Software requirements include:
Java Development Kit (JDK): Version 8 or later
Scala: Version 2.12 or later
Apache Spark: Latest stable release
Python: Version 3.6 or later (optional but recommended for PySpark)
Installing Apache Spark
Download the latest version of Apache Spark from the official website. Extract the downloaded file to a preferred directory. Set the SPARK_HOME environment variable to point to the Spark installation directory. Add $SPARK_HOME/bin to the system's PATH variable to access Spark commands from any location in the terminal.
Verify the installation by running the spark-shell command in the terminal. Successful execution will open an interactive Spark shell.
Setting Up Java and Scala
Install the Java Development Kit (JDK) by downloading it from the official Oracle website or using a package manager like apt or brew. Set the JAVA_HOME environment variable to point to the JDK installation directory.
Install Scala by downloading it from the official Scala website or using a package manager. Set the SCALA_HOME environment variable to point to the Scala installation directory.
Verify the installations by running java -version and scala -version commands in the terminal.
Configuring the Environment of Spark Data Pipeline
Setting Up Spark Configuration Files
Configuration files play a crucial role in optimizing Spark performance. Locate the conf directory within the Spark installation directory. Copy the template configuration files (spark-env.sh.template, spark-defaults.conf.template, and log4j.properties.template) and remove the .template extension.
Edit the spark-env.sh file to set environment variables like SPARK_WORKER_MEMORY and SPARK_WORKER_CORES. Adjust settings in the spark-defaults.conf file to configure default properties for Spark applications. Modify the log4j.properties file to set logging levels.
Verification ensures that the environment is correctly set up. Start a standalone Spark cluster by running the start-master.sh and start-slave.sh scripts located in the sbin directory. Access the Spark Web UI by navigating to http://localhost:8080 in a web browser. The UI provides detailed information about the cluster status and running applications.
Run a sample Spark application to test the setup. Use the spark-submit command to submit a job. Monitor the job's progress and logs through the Spark Web UI.
Successful execution of the sample application confirms that the Spark environment is properly configured.
Understanding the Spark Data Pipeline Architecture
Components of a Spark Data Pipeline
Data Sources
Data sources form the foundation of any data pipeline. These sources can include databases, APIs, file systems, and streaming platforms. Apache Spark supports various data sources, enabling seamless integration with various data formats and storage systems. Common data sources include:
Relational Databases: MySQL, PostgreSQL, Oracle
NoSQL Databases: MongoDB, Cassandra, HBase
File Systems: HDFS, S3, local file systems
Streaming Platforms: Apache Kafka, Amazon Kinesis
Each data source requires specific configurations to ensure efficient data ingestion. Spark's flexibility allows users to read data from multiple sources simultaneously, facilitating comprehensive data analysis.
Data Processing
Data processing involves transforming raw data into meaningful insights. Apache Spark excels in this area due to its powerful processing capabilities. Spark provides two primary abstractions for data processing: DataFrames and Resilient Distributed Datasets (RDDs).
DataFrames: High-level abstraction for structured data. DataFrames provide a convenient API for performing SQL-like operations.
RDDs: Low-level abstraction for distributed data. RDDs offer fine-grained control over data transformations and actions.
Spark's processing engine supports various operations, including filtering, aggregating, joining, and sorting. Users can leverage Spark SQL for complex queries or use the RDD API for custom transformations.
Data Storage
Data storage is crucial for preserving processed data. Apache Spark supports multiple storage options, ensuring compatibility with different data architectures. Common storage solutions include:
Data Warehouses: Amazon Redshift, Google BigQuery, Snowflake
Efficient data storage enables quick retrieval and further analysis. Spark's integration with various storage systems ensures that processed data remains accessible and secure.
Spark's Role in the Pipeline
Batch Processing
Batch processing involves processing large volumes of data in discrete chunks. Apache Spark's batch processing capabilities make it ideal for handling big data workloads. Spark processes data in parallel across multiple nodes, significantly reducing processing time.
Key features of Spark's batch processing include:
Fault Tolerance: Automatic recovery from failures using lineage information.
In-Memory Computing: Faster data processing by keeping intermediate data in memory.
Scalability: Ability to scale horizontally by adding more nodes to the cluster.
Batch processing suits scenarios where data arrives at regular intervals or requires periodic updates. Examples include ETL (Extract, Transform, Load) jobs, data warehousing, and report generation.
Stream Processing
Stream processing deals with real-time data. Apache Spark's stream processing capabilities enable users to process data as it arrives. Spark Streaming and Structured Streaming are two key components for stream processing.
Spark Streaming: Processes data in micro-batches, providing near real-time processing.
Structured Streaming: Offers continuous processing with low-latency guarantees.
Stream processing is essential for applications requiring immediate insights. Examples include fraud detection, real-time analytics, and monitoring systems.
Apache Spark's versatility in both batch and stream processing makes it a valuable tool for building robust data pipelines. Its ability to handle diverse data sources, perform complex transformations, and integrate with various storage solutions ensures comprehensive data processing capabilities.
Building the Spark Data Pipeline
Data Ingestion of Spark Data Pipeline
Reading Data from Various Sources
Data ingestion serves as the initial step in constructing a spark data pipeline. Apache Spark supports numerous data sources, including relational databases, NoSQL databases, file systems, and streaming platforms. Each source requires specific configurations to ensure efficient data ingestion.
Relational Databases: MySQL, PostgreSQL, Oracle
NoSQL Databases: MongoDB, Cassandra, HBase
File Systems: HDFS, S3, local file systems
Streaming Platforms: Apache Kafka, Amazon Kinesis
Apache Spark's flexibility allows users to read data from multiple sources simultaneously. This capability facilitates comprehensive data analysis.
Using Spark's DataFrame API
The DataFrame API provides a high-level abstraction for structured data. Users can perform SQL-like operations on data using this API. DataFrames offer a convenient way to manipulate data without requiring extensive coding.
The DataFrame API simplifies data ingestion by providing built-in functions for reading various data formats. This approach ensures efficient data handling within the spark data pipeline.
Data Transformation of Spark Data Pipeline
Applying Transformations with Spark SQL
Spark SQL enables users to perform complex transformations using SQL queries. This interface is invaluable for those interested in data science, big data analytics, or machine learning. Users can leverage SQL syntax to filter, aggregate, and join data.
Example code to apply transformations using Spark SQL:
df.createOrReplaceTempView("data_table")
transformed_df = spark.sql("""
SELECT column1, SUM(column2) as total
FROM data_table
GROUP BY column1
""")
Spark SQL provides a powerful tool for transforming data within a Spark data pipeline. Its SQL interface simplifies the process of deriving meaningful insights from raw data.
Using Spark's RDD API
The Resilient Distributed Dataset (RDD) API offers fine-grained control over data transformations. RDDs provide a low-level abstraction for distributed data. Users can perform custom transformations and actions on RDDs.
Example code to apply transformations using the RDD API:
The RDD API allows users to implement custom logic for data transformations. This flexibility makes it an essential component of a spark data pipeline.
Data Storage of Spark Data Pipeline
Writing Data to HDFS
Data storage plays a crucial role in preserving processed data. Apache Spark supports multiple storage options, including distributed file systems like HDFS. Writing data to HDFS ensures compatibility with large-scale data architectures.
Efficient data storage enables quick retrieval and further analysis. HDFS provides a robust solution for storing large volumes of data within a spark data pipeline.
Storing Data in Databases
Storing processed data in databases ensures accessibility and security. Apache Spark supports various databases, including MySQL, PostgreSQL, and Cassandra. Users can write data to these databases for long-term storage and querying.
Database storage provides a structured way to manage processed data. This approach ensures that data remains accessible for future analysis within the spark data pipeline.
Running and Monitoring the Spark Data Pipeline
Executing the Pipeline
Running Spark Jobs
Running Spark jobs involves submitting applications to a Spark cluster for execution. Use the spark-submit command to deploy these applications. This command submits the job to the cluster, where it processes data according to the specified logic.
The --class option specifies the main class of the application. The --master option defines the cluster mode. The final argument points to the application JAR file. Successful execution will process the data and produce the desired output.
Scheduling with Apache Airflow
Apache Airflow serves as a powerful tool for scheduling and orchestrating Spark jobs. Airflow allows users to define workflows as Directed Acyclic Graphs (DAGs). Each node in the DAG represents a task, such as running a Spark job.
Example code to schedule a Spark job with Airflow:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 1, 1),
}
dag = DAG('spark_job', default_args=default_args, schedule_interval='@daily')
run_spark_job = BashOperator(
task_id='run_spark_job',
bash_command='$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[4] $SPARK_HOME/examples/jars/spark-examples_2.12-3.0.1.jar 100',
dag=dag,
)
Airflow's scheduling capabilities ensure that Spark jobs run at specified intervals. This automation enhances the efficiency and reliability of the data pipeline.
Monitoring and Debugging
Using Spark UI
The Spark UI provides a comprehensive interface for monitoring Spark applications. Access the Spark UI by navigating to http://localhost:4040 in a web browser. The UI displays detailed information about running and completed jobs.
Key features of the Spark UI include:
Job Progress: Visual representation of job stages and tasks.
Storage Tab: Information about RDD and DataFrame storage.
Environment Tab: Configuration details and environment variables.
Monitoring job progress through the Spark UI helps identify performance bottlenecks. This insight allows for optimization of the data pipeline.
Logging and Error Handling
Logging and error handling play crucial roles in maintaining a robust data pipeline. Spark provides built-in logging capabilities using Log4j. Configure logging settings in the log4j.properties file located in the conf directory.
Error handling involves capturing and managing exceptions during job execution. Use try-catch blocks in the application code to handle errors gracefully.
Effective logging and error handling ensure the stability and reliability of the Spark data pipeline. These practices facilitate quick identification and resolution of issues, maintaining smooth operation.
Building a Spark Data Pipeline with FineDataLink
Why Use FineDataLink in Your Spark Pipeline?
FineDataLink, developed by FanRuan Software, serves as a powerful complement to Spark by ensuring that all data entering your pipeline is clean, accurate, and analysis-ready. This platform excels in streamlining data integration, offering seamless connectivity across a wide range of data sources, including databases, file systems, and streaming platforms. FineDataLink simplifies the process of validating and transforming your data, ensuring it meets the necessary standards before reaching Spark, ultimately enhancing the efficiency and reliability of your data analytics workflow.
FineDataLink supports multiple data sources
Incorporating FineDataLink into your data pipeline provides several key benefits:
Enhanced Data Quality: FineDataLink’s advanced validation features ensure that only high-quality data is processed, reducing the risk of errors and improving the overall reliability of your analytics.
Simplified Data Management: With FineDataLink, you can customize workflows to suit your specific needs, making it easier to manage complex data transformations.
Scalability: As your data grows, FineDataLink scales effortlessly, handling increasing data volumes with ease.
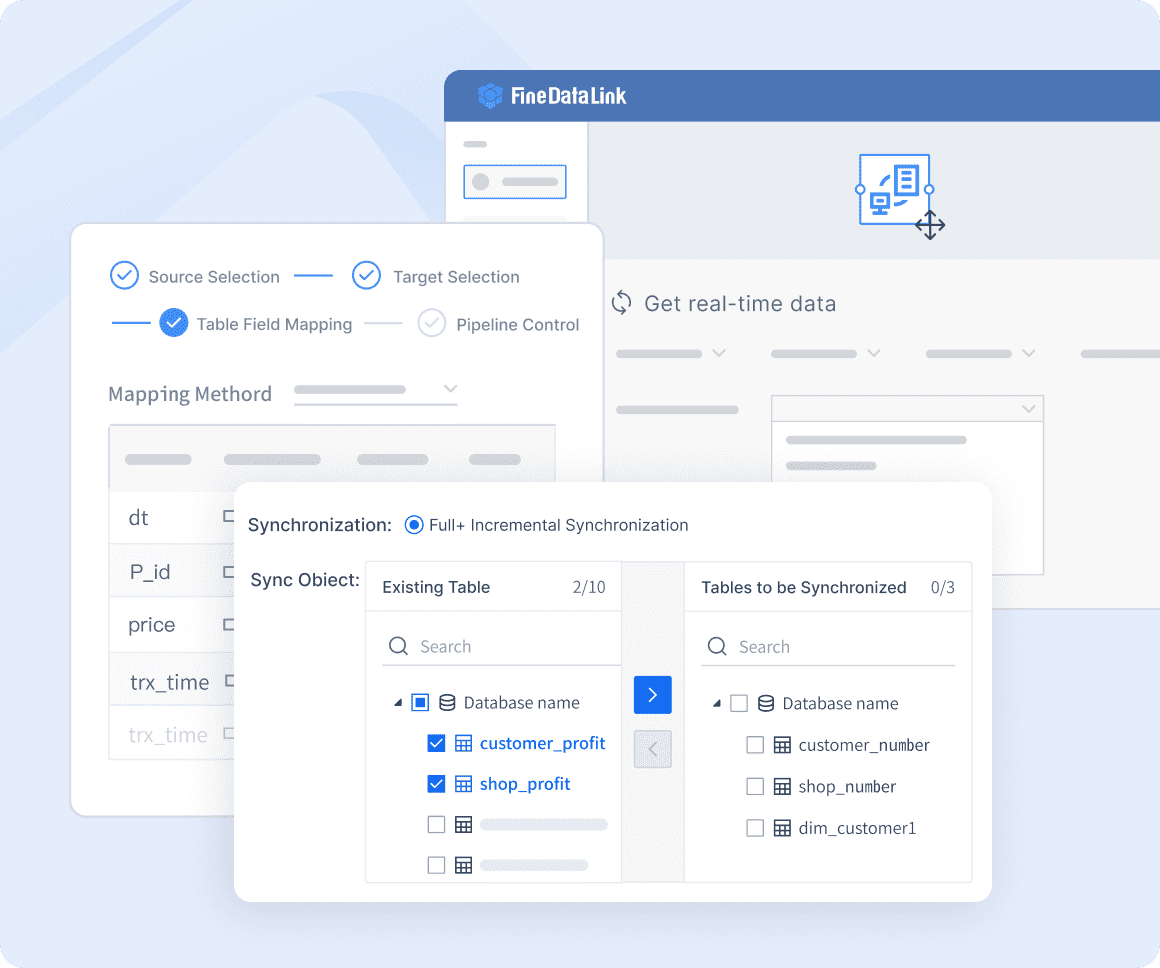
Configuring FineDataLink for Your Spark Pipeline
After setting up Spark, FineDataLink can be easily integrated into your environment. By configuring FineDataLink alongside Spark, you can ensure that your data pipeline benefits from top-tier data validation and integration features.
FineDataLink’s intuitive interface simplifies this setup, providing detailed documentation and support to get you up and running quickly. With FineDataLink, you can monitor data quality in real time, making adjustments on the fly to ensure your pipeline remains efficient and reliable.
For more detailed instructions on integrating FineDataLink with Spark, FineDataLink’s support team is available to guide you through the process, ensuring that you make the most of this powerful combination.
Conclusion of Spark Data Pipeline
Building a Spark data pipeline involves several critical steps, from setting up the environment to processing and storing data. By integrating FineDataLink into your pipeline, you can significantly enhance data quality and operational efficiency, ensuring that your data-driven insights are both accurate and actionable. Experiment with FineDataLink's features to optimize your pipeline further and unlock the full potential of your data!