Reference data management is the discipline of defining, governing, and synchronizing the standardized codes, classifications, and lookup values that give business data meaning across systems. Without it, "APAC" in your CRM means something different from "Asia-Pacific" in your ERP, customer tiers conflict between sales and support, and every dashboard tells a slightly different story.
This guide defines reference data management, distinguishes it from master and transactional data, provides concrete examples, outlines a practical management process, and explains how FineDataLink automates reference data synchronization across enterprise systems.
What Is Reference Data Management?
Reference data management (RDM) is the process of creating, maintaining, governing, and distributing standardized reference data—codes, categories, statuses, units of measure, currencies, regions, and other classification values—that provide context and consistency to transactional and analytical data across an organization.
Reference data is typically:
Relatively static. Changes infrequently compared to transactional data.
Shared across systems. Used by ERP, CRM, HR, finance, supply chain, and analytics platforms.
Definitional. Provides the vocabulary that makes business data interpretable.
Governed centrally. Owned by specific stewards with defined approval workflows for changes.
Effective RDM ensures that when any system references "customer tier = Gold," "region = EMEA," or "product category = Industrial Sensors," every downstream consumer interprets those values identically. When RDM fails, organizations experience reporting discrepancies, integration errors, compliance gaps, and AI outputs grounded in conflicting definitions.
Reference Data vs Master Data vs Transactional Data
Confusing these three data types is one of the most common causes of failed data governance initiatives. Each has distinct characteristics, ownership models, and management requirements.
Lost transactions; operational errors; audit failures
Key distinction: Reference data classifies master and transactional data. Master data identifies business entities. Transactional data records business events. All three must be managed, but with different tools, processes, and governance models.
Common Reference Data Examples
Concrete examples clarify what qualifies as reference data versus other data types.
Category
Reference Data Examples
Why It Matters
Geography
Country codes (ISO 3166), sales regions, territories, time zones
Enables accurate regional reporting, tax calculation, compliance
Organization
Department codes, cost centers, business units, legal entities
Supports financial consolidation, budgeting, access control
Product
Product categories, SKU hierarchies, unit of measure, packaging types
Error codes, API response codes, data type mappings
System integration reliability; troubleshooting efficiency
Reference data exists in every domain. The test is simple: if a value is used to classify, categorize, or provide context to other data—and is shared across multiple systems—it is reference data.
Why Reference Data Management Matters
Poorly managed reference data creates compounding problems across the enterprise:
Business Impact
Consequence of Poor RDM
How Good RDM Helps
Reporting accuracy
Dashboards show conflicting totals because regions, categories, or statuses are defined differently per source
Single authoritative definition propagated to all consumers
System integration
ETL pipelines fail or produce incorrect joins when code tables don't match
Synchronized reference values enable reliable cross-system data movement
Regulatory compliance
Tax codes, industry classifications, or reporting categories vary by jurisdiction without centralized control
Governed reference data with audit trails supports audit readiness
AI and analytics reliability
Models trained on inconsistently coded data produce unreliable predictions and explanations
Standardized dimensions improve model accuracy and explainability
Operational efficiency
Staff spend hours reconciling mismatched dropdowns, fixing misclassified records, and resolving disputes over definitions
Integrating acquired companies' data requires mapping dozens of conflicting code tables
Centralized reference data hub accelerates integration timelines
The cost of poor RDM is rarely visible as a line item. It manifests as delayed reports, disputed metrics, failed integrations, and eroded trust in data—all of which compound over time.
Common Challenges in Reference Data Management
Challenge
Root Cause
Practical Response
Siloed definitions
Each system maintains its own code tables independently
Establish central reference data repository; synchronize via FineDataLink
Manual maintenance
Spreadsheets and ad-hoc updates create version conflicts
Automate distribution through governed pipelines with change tracking
No clear ownership
Nobody owns cross-system reference data standards
Assign domain stewards with defined RACI for each reference data domain
Change propagation lag
Updates take weeks to reach all consuming systems
Implement real-time or scheduled sync with validation at delivery
Legacy system constraints
Older systems cannot consume modern APIs or formats
Use middleware/adapters; maintain backward-compatible export formats
Insufficient governance
Changes made without approval or documentation
Implement approval workflows, audit logs, and version history
Scale complexity
Reference data grows as business expands geographically or through acquisition
Design for extensibility; use hierarchical and parameterized models
Most RDM challenges are organizational, not technical. Technology enables synchronization and governance, but sustainable RDM requires defined ownership, approved processes, and executive sponsorship.
Reference Data Management Process
A repeatable RDM process follows six stages:
Identify and inventory. Catalog all reference data domains across systems. Document current definitions, owners, update frequencies, and consumers. Prioritize domains by business impact and inconsistency risk.
Define standards. For each priority domain, establish authoritative definitions, valid values, naming conventions, and metadata. Engage domain stakeholders to achieve consensus. Document in a centralized glossary or data catalog.
Establish governance. Assign data stewards per domain. Define approval workflows for additions, modifications, and retirements. Set review cadences. Document escalation paths for disputes.
Build synchronization. Implement automated pipelines that distribute authoritative reference data to all consuming systems. Validate on delivery. Log all changes. FineDataLink supports this stage with visual ETL/ELT workflows, multi-source connectivity, and built-in validation.
Monitor and validate. Track synchronization success rates, latency, and exception volumes. Profile reference data for drift, orphaned values, and unused codes. Alert stewards to anomalies.
Review and evolve. Conduct quarterly reviews of reference data domains. Retire obsolete values. Add new values as business evolves. Update standards based on feedback and audit findings.
This process is cyclical, not linear. Reference data management is an ongoing capability, not a one-time project.
Best Practices for Reference Data Management
Start with high-impact domains. Don't try to govern everything at once. Prioritize reference data that causes the most reporting discrepancies, integration failures, or compliance risks.
Centralize authority, distribute consumption. Maintain one authoritative source per reference data domain. Allow all systems to consume from it, but never allow multiple systems to independently define the same reference values.
Automate synchronization. Manual distribution does not scale. Use governed pipelines to push reference data changes to consuming systems on a schedule matching business need.
Validate at every touchpoint. Check reference data integrity at extraction, transformation, loading, and consumption. Catch mismatches before they corrupt downstream analytics.
Version and audit everything. Every reference data change should have a timestamp, approver, rationale, and before/after state. Audit trails are non-negotiable for compliance and troubleshooting.
Design for change. Reference data evolves. Build flexible schemas that accommodate new values, hierarchies, and attributes without requiring system redesigns.
Integrate with data governance frameworks. RDM should not operate in isolation. Align with your organization's broader data governance, data quality, and master data management programs.
Educate consumers. Ensure analysts, developers, and business users understand reference data standards and know where to find authoritative values. Reduce shadow definitions.
Measure RDM effectiveness. Track metrics like synchronization success rate, reference data-related incident volume, time-to-propagate changes, and stakeholder satisfaction. Treat RDM as a measurable service.
Plan for AI readiness. AI models and agents depend on consistent dimensions. Invest in RDM now to avoid costly rework when deploying AI-powered analytics later.
What to Look for in Reference Data Management Tools
Not every data tool handles reference data well. Evaluate platforms against these capabilities:
Capability
Why It Matters
Multi-source connectivity
Reference data lives in ERP, CRM, databases, APIs, spreadsheets. Tools must connect to all relevant sources.
Bidirectional synchronization
Some systems need to receive reference data; others may originate updates. Sync must support both directions with conflict resolution.
Visual pipeline design
Business data teams should build and modify sync workflows without custom code.
Built-in validation and profiling
Detect invalid values, orphaned codes, and schema drift automatically within pipelines.
Change tracking and audit logs
Every modification must be traceable for compliance and troubleshooting.
Scheduled and event-driven execution
Support both batch refresh and real-time propagation depending on domain requirements.
Error handling and alerting
Failed synchronizations must be visible, recoverable, and escalated appropriately.
Integration with data catalogs and governance platforms
Reference data definitions should link to broader governance artifacts.
Scalability
Handle growing reference data volumes and increasing synchronization frequency without performance degradation.
FineDataLink addresses these requirements for enterprise data integration scenarios where reference data synchronization is part of broader data movement and preparation workflows.
How FineDataLink Supports Reference Data Management
FineDataLink helps enterprises connect ERP, CRM, databases, APIs, and spreadsheets, then synchronize shared code tables, business dimensions, and reference values across systems. This makes it easier to keep sales regions, product categories, customer tiers, currency codes, and status values consistent before they flow into data warehouses, dashboards, reports, and AI workflows.
Key capabilities for reference data management include:
Multi-source connectivity. Native connectors for relational databases, cloud warehouses, SaaS platforms, REST/SOAP APIs, and flat files. Single platform replaces fragmented scripts and point-to-point integrations.
Visual ETL/ELT pipeline builder. Drag-and-drop interface for designing reference data extraction, transformation, validation, and loading workflows. Reduces dependency on custom code.
Built-in data quality validation. Profile reference data for completeness, validity, and consistency within pipelines. Flag anomalies before they propagate to consuming systems.
Scheduled and incremental synchronization. Match refresh frequency to domain volatility. Support full refresh for stable domains and CDC-based incremental sync for frequently updated reference data.
Change tracking and lineage. Audit every reference data modification with timestamps, source/target mapping, and transformation logic. Support compliance and root-cause analysis.
Error handling and recovery. Automatic retry, checkpointing, and alerting prevent silent synchronization failures. Exceptions are visible and actionable.
Scalable execution. Distributed processing handles growing reference data volumes and increasing synchronization demands without proportional operational overhead.
FineDataLink Data Connection
When reference data is synchronized reliably, downstream analytics in FineBI reflect consistent dimensions, and AI agents operate on unified definitions rather than conflicting code tables.
Dora works better when business terms, dimensions, and reference values are already standardized. When regions, product categories, customer segments, and status codes are consistent, Dora can answer business questions more reliably, generate summaries, detect anomalies, and route follow-up analysis without mixing different definitions from different systems.
Reference data management is foundational infrastructure for AI-assisted analytics. Without it, natural-language queries return answers grounded in whichever system's definition happened to be queried first—producing confident-sounding but inconsistent outputs. With governed reference data synchronized by FineDataLink, Dora operates on a unified semantic layer where "EMEA," "Gold tier," and "resolved" mean the same thing everywhere.
The sequence matters: standardized reference data first, trusted datasets second, AI-assisted analysis third.
Reference data consists of standardized codes, categories, and lookup values (currency codes, regions, statuses) used to classify other data. Master data consists of core business entities (customers, products, employees) that identify who or what is involved in transactions. Reference data is relatively static and shared broadly; master data changes more frequently and is owned by specific business domains. Both require governance, but with different processes and tools.
Analytics and AI depend on consistent dimensions. If "APAC" means different things in CRM and ERP, regional revenue reports conflict. If customer tiers are defined differently across systems, segmentation models produce unreliable results. Reference data management ensures that every analytical and AI workload operates on unified definitions, making outputs trustworthy and comparable over time.
Common reference data includes geography codes (countries, regions, territories), organization structures (departments, cost centers), product classifications (categories, SKUs, units of measure), customer attributes (tiers, segments, industry codes), financial standards (currencies, chart of accounts, tax codes), and workflow statuses (order status, ticket status, approval states). Any value used to classify or provide context to other data across multiple systems qualifies as reference data.
Begin by inventorying reference data domains across systems and identifying where inconsistencies cause the most pain (reporting disputes, integration failures, compliance gaps). Prioritize 2–3 high-impact domains. Define authoritative standards with domain stakeholders. Assign stewards. Implement automated synchronization using a platform like FineDataLink. Measure effectiveness and expand scope incrementally. Avoid attempting enterprise-wide RDM as a single project.
For many enterprises, yes—particularly when reference data synchronization is part of broader data integration workflows. Dedicated RDM platforms offer specialized features like hierarchical modeling and advanced stewardship workflows that may be necessary for highly regulated industries or extremely complex reference data landscapes. FineDataLink provides sufficient RDM capability for organizations whose primary need is reliable, automated synchronization of reference values across heterogeneous systems as part of their data integration strategy.
Reference data management is a core component of data governance. Governance establishes policies, standards, and accountability; RDM operationalizes those policies for classification and dimension data. Without RDM, governance policies about data consistency remain aspirational. Without governance, RDM efforts lack authority and sustainability. The two must be implemented together for lasting impact.
Product Trial
FineReport
Pixel-perfect reports · Interactive dashboards · Easy data entry · Digital twins

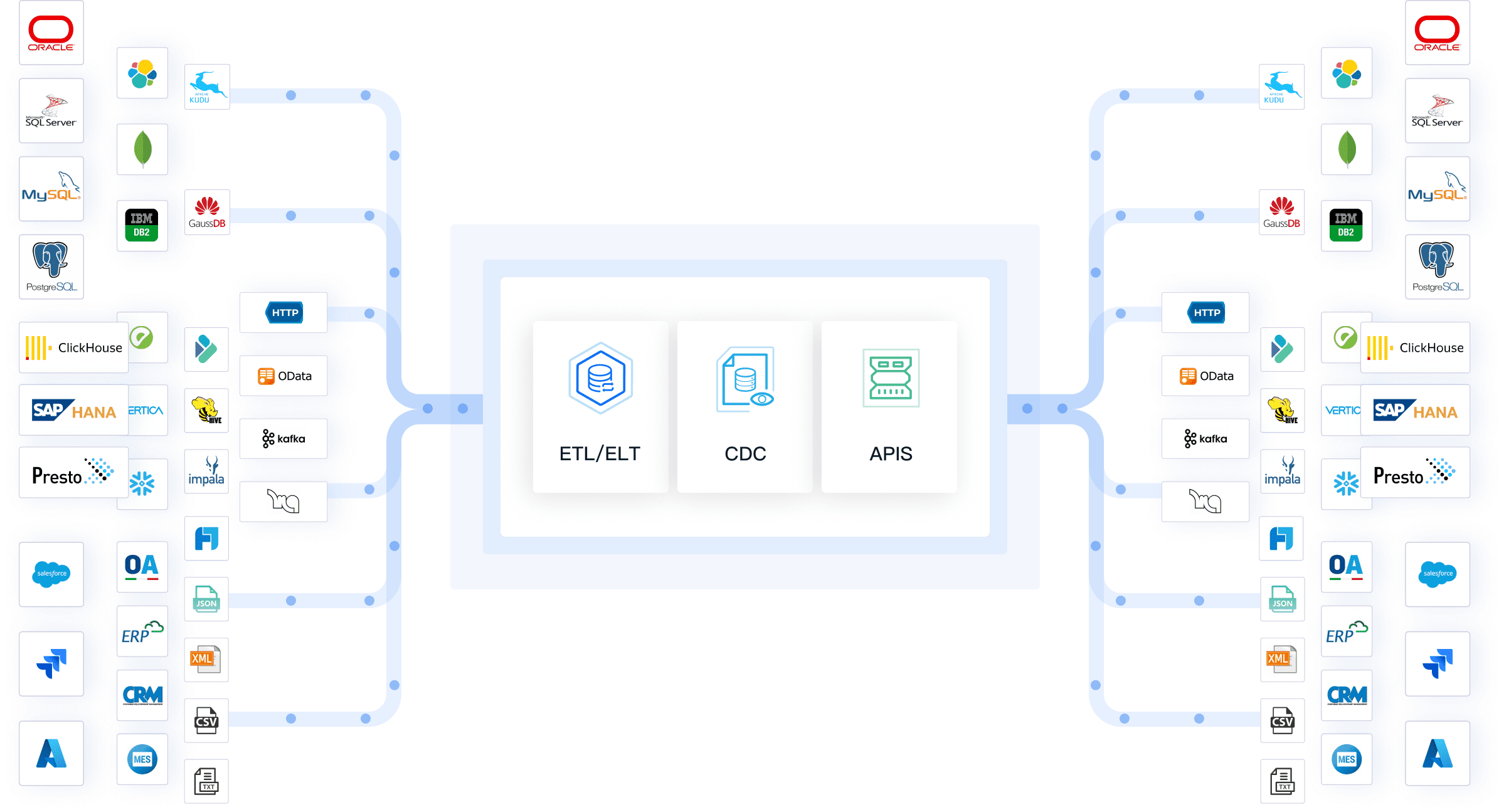 FineDataLink Data Connection
FineDataLink Data Connection