"데이터 기반 의사결정을 내리기 위해 어떤 방법이 가장 효율적인가?"라는 질문은 많은 기업과 실무자가 매일 마주하는 고민입니다. 실제로 SQL은 데이터베이스에서 표준 언어로 자리 잡아 다양한 산업에서 데이터 추출에 활용되고 있습니다. 데이터가 폭발적으로 증가함에 따라, 실무자는 SQL을 통해 필요한 정보를 빠르고 정확하게 확보할 수 있습니다. 2023년 10월, 이론보다 실습에 집중한 학습 사례에서도 초보자가 직접 문제를 해결하며 JOIN 문까지 성공적으로 작성할 수 있었습니다. 이처럼 체계적인 접근만 있다면 누구나 데이터 추출 역량을 키울 수 있습니다.
SQL 데이터 추출의 핵심은 명확한 구조와 절차에 기반합니다. 데이터베이스를 효과적으로 운영하려면 다음과 같은 단계가 필요합니다.
이러한 절차를 거치면, 데이터 추출을 위한 안정적인 환경이 마련됩니다.
SQL에서 가장 기본이 되는 구문은 SELECT, FROM, WHERE입니다.
아래 예시는 실무자가 자주 활용하는 데이터 추출 구문입니다.
SELECT * FROM company WHERE symbol = 'AAPL' OR symbol = 'MSFT' OR symbol = 'TSLA';
SELECT * FROM company WHERE symbol IN ('AAPL', 'MSFT', 'TSLA');
SELECT * FROM users WHERE name LIKE '홍%';
SELECT * FROM company WHERE year BETWEEN 2010 AND 2011;
올바른 SQL 구문 작성은 데이터 품질과 업무 효율성을 좌우합니다.
SQL 구문을 잘못 작성할 경우 다음과 같은 오류가 발생할 수 있습니다.
| 오류 코드 | 원인 | 해결 방법 |
|---|---|---|
| 1072 | Key column 'abc' doesn't exist in table | 존재하는 칼럼에 인덱스를 부여합니다. |
| 1093 | Table 'TESTNAME' is specified twice | 서브 쿼리 부분에 별칭(alias)을 설정합니다. |
| 1136 | Column count doesn't match value count at row 1 | 테이블 열의 수와 값의 수를 일치시킵니다. |
| 1222 | The used SELECT statements have a different number of columns | union 사용 테이블들의 칼럼 수를 맞춥니다. |
| 1242 | Subquery returns more than 1 row | 서브 쿼리의 결과가 하나의 레코드를 반환하도록 문법을 수정합니다. |
실무자는 이러한 오류를 사전에 점검하여 데이터 추출의 정확성을 높일 수 있습니다.
데이터 리니지 모듈 구현, SQL 로그를 통한 테이블-컬럼 관계 데이터 적재, 데이터 흐름 시각화 등 다양한 실제 사례가 존재합니다. 이러한 방법을 활용하면 데이터 추출 과정에서 데이터의 흐름과 품질을 체계적으로 관리할 수 있습니다.
Fanruan은 데이터 통합과 분석을 위한 혁신적인 플랫폼을 제공합니다. 기업은 Fanruan의 FineDataLink를 활용하여 데이터 추출 환경을 신속하게 구축할 수 있습니다. FineDataLink는 다양한 데이터 소스를 통합하고, 실시간 데이터 동기화와 ETL/ELT 기능을 지원합니다.
Fanruan의 시각적 인터페이스와 로우 코드 환경은 데이터 추출 과정을 획기적으로 단순화합니다.
데이터 엔지니어와 비즈니스 인텔리전스 담당자는 다음과 같은 준비 과정을 거쳐 데이터 추출을 시작할 수 있습니다.
Fanruan의 FineDataLink는 데이터 사일로 문제를 해결하고, 데이터 추출의 자동화와 효율화를 실현합니다. 실시간 데이터 웨어하우스 구축, 데이터 관리 및 거버넌스 강화, 운영 비용 절감 등 다양한 비즈니스 가치를 제공합니다.
이처럼 체계적인 환경 준비와 도구 활용은 데이터 추출의 정확성과 신속성을 극대화합니다.

데이터 추출의 첫 단계는 데이터베이스와 테이블 구조를 정확히 파악하는 일입니다.
테이블 구조를 사전에 확인하지 않으면 데이터 무결성이나 설계 오류로 인해 비즈니스 요구를 충족하지 못할 수 있습니다.
예를 들어, 사원이 두 개 이상의 부서에 속해야 하는 요구가 있을 때, 기존 테이블 구조로는 이를 처리하기 어렵다는 점에서 설계의 중요성이 부각됩니다.
| 명령어 | 설명 |
|---|---|
| SHOW DATABASES; | 데이터베이스의 스키마 리스트 확인 |
| SHOW TABLES; | 현재 스키마에 존재하는 테이블 리스트 확인 |
| DESCRIBE TABLE [스키마].[테이블명]; | 해당 테이블 구조 확인 (컬럼, 데이터타입 등) |
| SHOW CREATE TABLE [스키마].[테이블명]; | 해당 테이블 DDL문 확인 |
테이블 구조 확인은 데이터베이스 설계의 타당성을 검증하고, 데이터 무결성을 유지하는 데 필수적입니다.
SELECT문 작성 시에는 다음과 같은 사항에 유의해야 합니다.
SQLD 시험이나 실무에서 자주 사용하는 구문은 SELECT, FROM, WHERE, GROUP BY, ORDER BY 등입니다.
또한, DECODE, NVL, COALESCE와 같은 함수도 데이터 추출 과정에서 자주 활용됩니다.

Fanruan의 FineDataLink는 데이터 추출 자동화와 효율화에 최적화된 솔루션입니다.
FineDataLink는 시각적 인터페이스와 로우 코드 환경을 제공하여 데이터 파이프라인 설계와 실시간 동기화를 손쉽게 구현할 수 있습니다.
FineDataLink를 활용하면 다음과 같은 비즈니스 가치를 실현할 수 있습니다.
이러한 자동화 환경은 반복적인 수작업을 줄이고, 데이터 추출 업무의 효율성을 극대화합니다.
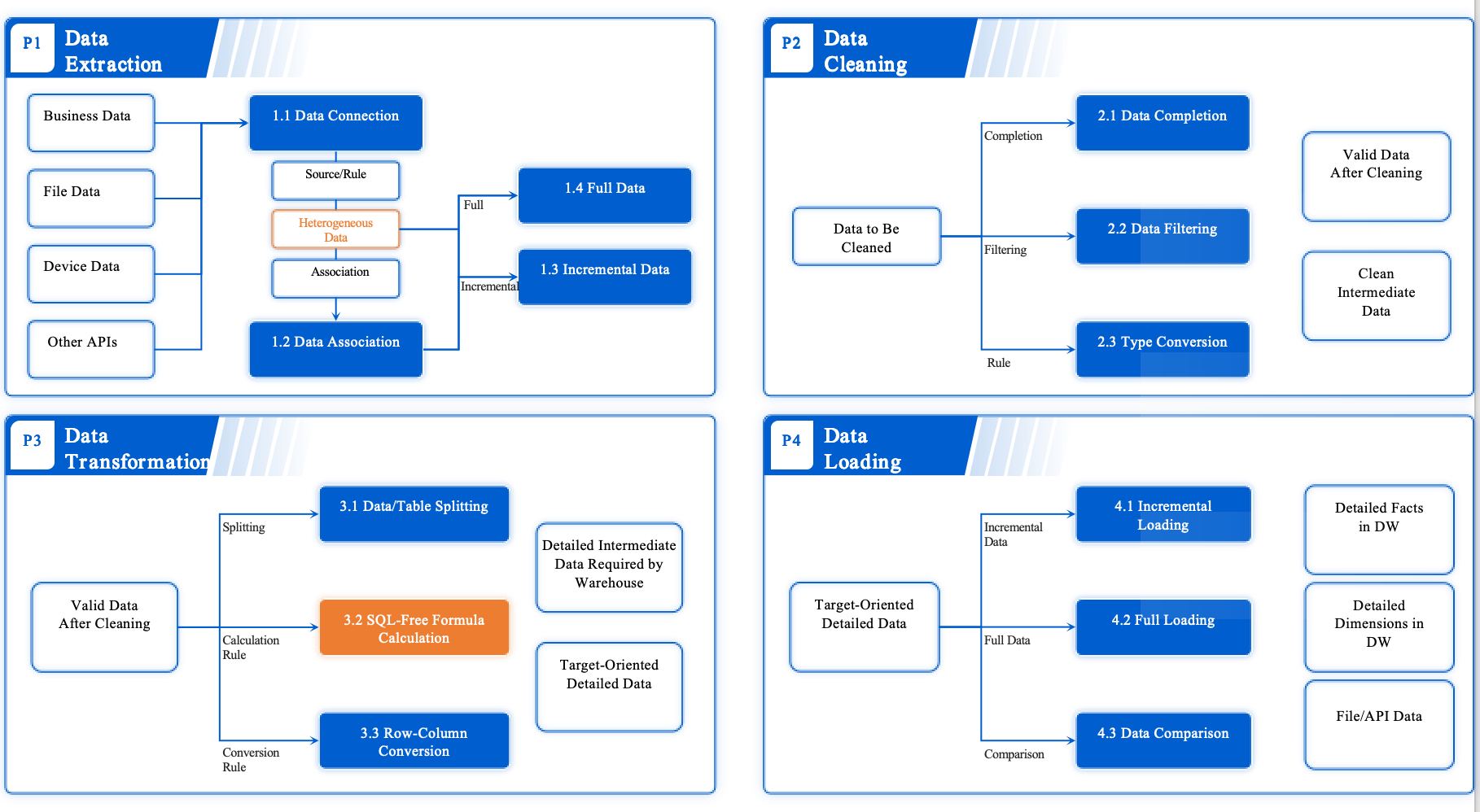
실무자는 데이터 추출 시 DISTINCT와 AS 구문을 자주 사용합니다.
DISTINCT는 중복 데이터를 제거하고, AS는 컬럼이나 테이블에 별칭을 부여하여 쿼리의 가독성을 높입니다.
| 쿼리 예시 | 설명 |
|---|---|
SELECT DISTINCT email FROM customers; | 'customers' 테이블에서 중복된 이메일 주소를 제거하고 고유한 이메일 주소 목록을 얻기 위한 쿼리 |
SELECT city, COUNT(*) AS num_customers FROM customers GROUP BY city; | 'city' 열에서 고유한 도시를 기준으로 고객 수를 계산하는 쿼리 |
DISTINCT와 AS 구문을 사용할 때는 다음과 같은 실수를 주의해야 합니다.
또한, 정렬 없이 LIMIT만 사용하면 결과가 매번 달라질 수 있으며, ORDER BY에서 컬럼명을 잘못 입력하면 오류가 발생합니다. OFFSET을 과도하게 사용하면 성능 저하가 발생하므로 페이징 처리 시 최적화가 필요합니다. 올바른 SQL 구문과 자동화 도구의 활용은 데이터 추출의 품질과 업무 효율성을 결정합니다.
데이터 추출 후에는 반드시 결과 검증과 집계 오류 점검이 필요합니다.
기업은 데이터 품질을 확보하기 위해 자동화된 검증 도구와 표준화된 프로세스를 도입해야 합니다.
집계 오류를 점검할 때는 다음과 같은 SQL 함수와 기법을 활용해야 합니다.
| SQL 함수/기법 | 설명 |
|---|---|
| GROUP BY | 데이터들을 소그룹화하여 각 그룹별 통계 정보를 얻을 때 사용합니다. |
| HAVING | 소그룹의 데이터 중 일부만 필요한 경우에 사용합니다. |
| ROLLUP | 집계 결과에 대한 추가적인 요약 정보를 제공합니다. |
| CUBE | 다차원 집계 결과를 생성합니다. |
| COUNT | NULL을 포함한 행의 수를 계산합니다. |
| SUM | NULL을 제외한 합계를 계산합니다. |
| AVG | 평균을 계산합니다. |
| MAX | 최대값을 찾습니다. |
| MIN | 최소값을 찾습니다. |
| STDDEV | 표준 편차를 계산합니다. |
| VARIANCE | 분산을 계산합니다. |
데이터 검증과 집계 오류 점검은 데이터 기반 의사결정의 신뢰도를 높이는 핵심 절차입니다.
JOIN과 WHERE 절에서 발생하는 실수는 데이터 추출의 정확성에 직접적인 영향을 미칩니다.
실무자는 다음과 같은 오류 유형을 반드시 점검해야 합니다.
WHERE 절에서는 조건 지정 오류가 자주 발생합니다.
| 오류 사례 | 설명 |
|---|---|
| POSITION = NULL 사용 | 문법 에러는 발생하지 않지만, 조건이 거짓이 되어 선택된 레코드가 없습니다. |
| IS NULL 사용 | NULL 값의 비교를 올바르게 수행하여 결과를 얻을 수 있습니다. |
JOIN과 WHERE 절의 정확한 사용은 데이터 무결성과 분석 품질을 보장합니다.
Fanruan 환경에서 SQL을 작성할 때는 다음과 같은 전략이 필요합니다.
데이터 추출과 검증 과정에서 이상값, 데이터 처리 오류, 샘플링 오류, 자연적 이상값 등 다양한 오류 유형이 발생할 수 있습니다. 예를 들어, 연령 데이터에 9999세와 같은 비현실적인 값이 포함되면 평균값이 왜곡되어 분석 결과에 심각한 영향을 미칩니다.
| 오류 유형 | 설명 |
|---|---|
| 이상값 | 데이터 집합에서 비정상적으로 높은 또는 낮은 값이 포함된 경우 발생합니다. |
| 데이터 처리 오류 | 여러 소스에서 데이터를 추출할 때 조작 또는 추출 오류로 인해 이상값이 발생할 수 있습니다. |
| 샘플링 오류 | 특정 집단을 잘못 샘플링하여 대표성이 떨어지는 결과가 나올 수 있습니다. |
| 자연적 이상값 | 오류가 아닌 자연적인 이유로 발생하는 값입니다. |
Fanruan의 시각적 인터페이스와 로우 코드 환경을 활용하면 데이터 추출 과정에서 발생하는 오류를 신속하게 탐지하고 수정할 수 있습니다.
주석 작성, 명확한 별칭 사용, 표준화된 쿼리 컨벤션 준수, 데이터 흐름 모니터링을 통해 오류 발생 가능성을 최소화해야 합니다.
체계적인 검증과 Fanruan의 자동화 도구를 결합하면 데이터 추출의 신뢰성과 업무 효율성이 극대화됩니다.
SQL 데이터 추출 절차는 아래 표와 같이 핵심 단계로 요약할 수 있습니다.
| 단계 | 설명 |
|---|---|
| 전체 테이블 스캔 | 모든 데이터를 읽어 조건에 맞는 결과를 추출하는 방식입니다. |
| 인덱스 스캔 | 인덱스를 기반으로 데이터를 추출하는 기법입니다. |
| 옵티마이저 역할 | SQL문에 대한 최적의 실행 방법을 결정하는 역할을 합니다. |
| 실행계획 | SQL 요구 사항을 처리하기 위한 절차와 방법을 의미합니다. |
실무자는 SQL 실습을 통해 실무 능력 향상과 자격증 취득, 데이터 분석 프로젝트 경험 등 다양한 성취를 얻을 수 있습니다.
다음 단계로는 실무와 유사한 데이터 분석 프로젝트 수행, 지표 설정 및 시각화, 리포트 작성 역량 강화가 추천됩니다.
추가 학습을 위해 W3Schools SQL 튜토리얼, Codecademy SQL 강좌, "SQL 입문부터 코딩테스트까지 완전 정복하기"와 같은 강의 및 도서 활용을 권장합니다.

작성자
Seongbin
FanRuan에서 재직하는 고급 데이터 분석가
관련 기사

Platform Integration이란? 개념부터 API·iPaaS·데이터 연계 방식까지 한 번에 이해하기
디지털 업무 환경에서는 하나의 시스템만으로 운영이 끝나지 않습니다. CRM, $1, 결제 시스템, 물류 시스템, 마케팅 자동화 도구, 협업 앱, $1까지 서로 다른 도구가 동시에 돌아가죠. 이때 핵심이 되는 개념이 바로 platform integration 입니다. platform integration은 단순히 두 시스템을 연결하는 기술 작업을 넘어, 애플리케이션·데이터·업무 흐름을 하나의
Seongbin
2026년 7월 23일

2026 data integration software 비교: Fivetran·Informatica·IBM·FineDataLink, 어떤 기준으로 선택할까?
기업의 데이터 환경은 2026년에 들어서며 더 복잡해졌습니다. SaaS, $1, 레거시 시스템, 실시간 이벤트 스트림, 온프레미스 DB가 동시에 돌아가는 상황에서 단순히 “연결만 되는 도구”로는 부족합니다. 이제 $1 software 를 고를 때는 연결성, 자동화, $1, 운영 난이도, 총비용까지 함께 봐야 합니다. 특히 Fivetran, Informatica, IBM, FineDataLin
Seongbin
2026년 7월 23일

2026년 Data Integration Platform 비교 가이드: ETL·ELT·CDC·Reverse ETL 한눈에 정리
데이터가 늘어날수록 문제는 더 단순해지지 않습니다. 오히려 어디서 데이터를 가져오고, 어떤 방식으로 바꾸고, 어디에 적재하며, 얼마나 빠르게 동기화할 것인가 가 조직의 성과를 좌우하게 됩니다. 그래서 2026년에는 단순한 $1 도구를 넘어, 수집·변환·적재·동기화·모니터링을 함께 다루는 $1 platform 관점으로 도구를 비교하는 것이 중요합니다. 특히 $1, $1, CDC, Reverse
Seongbin
2026년 7월 23일



