Data augmentation means you create new data from your existing data using simple changes. You use it in machine learning to increase diversity and improve how well your models learn. When you apply data augmentation to images, you can boost accuracy. For example, models trained with more diverse images have reached up to 99% detection accuracy in medical tasks. You see fewer misclassifications when you use the right techniques. FineDataLink helps you prepare and integrate data from different sources, making your data pipeline stronger.
Data Augmentation Basics
What Is Data Augmentation
You often hear about data augmentation when you want to improve your models. Data augmentation means you create new data by changing your existing data in simple ways. You can flip, rotate, or zoom in on images to make your dataset larger and more varied. This process helps you train better models, especially when you do not have enough original data.
Here is a table that shows some widely accepted definitions of data augmentation:
You can use data augmentation in many ways. For example, you can add random noise to your data or use advanced methods like Generative Adversarial Networks (GANs) to create new samples. These techniques help you build stronger models, even if you start with a small dataset.
Why It Matters
Data augmentation matters because it helps you solve real problems in machine learning. When you use data augmentation, you make your models see more examples. This helps your models learn better and avoid mistakes. If you only train on a small set of images, your model might not work well on new data. By using data augmentation, you give your model more chances to learn from different situations.
You can see the benefits of data augmentation in several ways:
- It helps prevent overfitting. Overfitting happens when your model learns too much from the training data and does not work well on new data. Data augmentation gives your model more variety, so it does not memorize the training set.
- It improves generalization. Generalization means your model can handle new, unseen data. Studies show that data augmentation helps models recognize objects in different conditions, which is important for tasks like image recognition.
- It makes small datasets more useful. If you do not have much data, data augmentation lets you create more examples, so you do not need to collect as much new data.
Recent research shows that data augmentation can reduce overfitting by a large margin. For example, using simple strategies like TrivialAug can lower the forget rate and improve accuracy by over 40% in some cases.
Here is a table that highlights how data augmentation improves generalization:
You should also know that the choice of data augmentation technique can affect your results. Some methods may introduce variability, so you need to document your process carefully. This helps you repeat your experiments and understand what works best.
Note: While data augmentation is powerful, some techniques have limits. For example, rotating images too much can cause black patches, and some methods may not work well with special types of data, like legal documents.
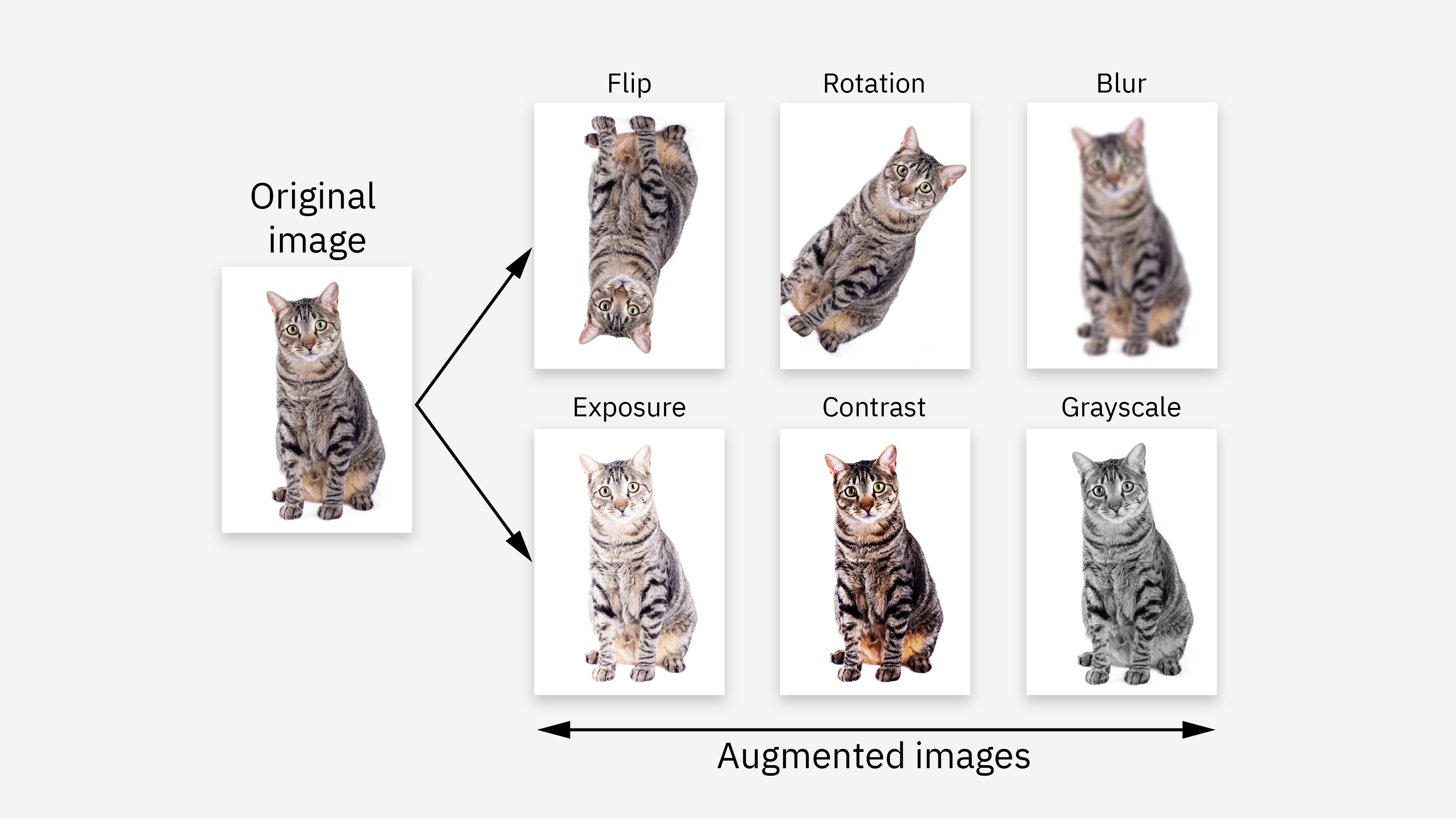
Data Augmentation vs Synthetic Data
Key Differences
You might wonder how data augmentation and synthetic data differ. Both methods help you expand your dataset, but they use different approaches. Data augmentation changes your existing data by applying transformations. For example, you can flip, rotate, or crop images to create new versions. This method works well when you want to increase diversity without changing the core content.
Synthetic data, on the other hand, involves creating entirely new data points. You use algorithms to generate records that do not exist in your original dataset. Researchers often use synthetic data to address bias or under-representation in datasets. For example, you can generate synthetic records to balance groups in a biased dataset. The goals of synthetic data often focus on improving fairness, predictive accuracy, and parameter precision.
Here is a summary of the main differences:
- Data augmentation uses transformations on real data, such as flipping or rotating images.
- Synthetic data generation creates new, artificial records, often to target under-represented groups.
- Synthetic data aims to improve fairness and balance, while data augmentation focuses on increasing diversity and reducing overfitting.
Use Cases
You should choose between data augmentation and synthetic data based on your project needs. Data augmentation works best when you want to improve model performance with limited data. For example, you can use it to help your machine learning model generalize better and avoid overfitting. When you work with images, data augmentation can help you create more training examples by applying simple changes.
Synthetic data is useful when you need to address class imbalance or fairness. If your dataset lacks enough examples for certain groups, you can generate synthetic records to fill the gap. This approach helps you build more balanced and fair models.
The table below shows when to use each method:
You can see that both methods play important roles in machine learning. By understanding their differences, you can select the right approach for your data challenges.
Data Augmentation Techniques

Image Data
You can use image data augmentation to improve model optimization and generalization. Common transformations include rotation, flipping, scaling, cropping, and brightness adjustment. For example, you might rotate images by 15 degrees or flip them horizontally. These transformations expose your model to varied representations, which reduces overfitting and enhances robustness. You can also apply color jittering to simulate different lighting conditions. The table below shows popular image transformations and their impact:
Random horizontal flip increases accuracy, while random rotation helps your model handle different orientations. ColorJitter improves efficiency when you have fewer training images. Image data augmentation is a cost-effective way to expand your dataset and develop more accurate models. FineDataLink supports these techniques by integrating and transforming images from multiple sources, making your data pipeline more efficient.
Text Data
Text data augmentation helps you address data scarcity and improve outcomes in natural language processing. You can use transformations such as synonym replacement, random insertion, and sentence shuffling. These methods create augmented data that boosts accuracy and F1-score across diverse NLP tasks. For example, replacing words with synonyms or shuffling sentence order can increase accuracy by up to 15.53%. FineDataLink enables you to prepare and integrate text data from different systems, streamlining your workflow for machine learning projects.
Other Data Types
You can apply data augmentation to audio and tabular data using targeted transformations. In audio, you might inject noise, shift time, change pitch, or adjust volume. These transformations help your model learn from varied audio samples. For tabular data, you can use techniques like SMOTE to generate synthetic examples, especially for minority classes. Heavier augmentation for underrepresented classes prevents overfitting and provides variance. FineDataLink simplifies the integration and transformation of these data types, supporting efficient model optimization and robust machine learning pipelines.

Impact on Machine Learning

When you apply data augmentation in machine learning, you see clear improvements in model performance. You can use transformations like flipping, rotating, and cropping images to create augmented data. This process exposes your model to a wider range of scenarios, which helps it learn broader patterns. You notice that models trained with augmented data often achieve higher accuracy and reliability.
For example, in medical imaging tasks, data augmentation has led to positive changes in prediction rates. The table below shows how model performance improves after using data augmentation:
You can see that data augmentation helps models make better predictions for different groups. This improvement supports model optimization and ensures that your machine learning models work well across diverse populations.
Generalization
Generalization is a key goal in machine learning. You want your model to perform well on new, unseen data. Data augmentation plays a major role in improving model generalization and generalizability. By increasing dataset diversity, you help your model learn features that apply to many situations.
You can look at statistical evidence to understand the impact. Data augmentation led to a significant increase in prediction performance for the top lines in the testing set, with improvements of 108.4% in NRMSE and 107.4% in MAAPE across traits and datasets. When you apply data augmentation only to the top 20% of lines, the overall prediction accuracy of the whole testing set decreased by 48.6% and 38.9% in terms of NRMSE and MAAPE, respectively. This shows that targeted augmentation can boost performance for specific groups, but broad application is important for overall generalization.
You also see that data augmentation enhances robustness. By simulating various conditions, your models become better equipped to handle real-world variability. This process reduces overfitting and makes your models more reliable in production environments.
Here are some key benefits you gain from data augmentation in machine learning:
- Data augmentation increases dataset diversity, which enhances model generalization.
- It reduces overfitting, making models more reliable in production environments.
- By simulating various conditions, models become better equipped to handle real-world variability.
You can follow these steps to improve generalization in your machine learning projects:
- Generate synthetic data through transformations like rotation and scaling.
- Create a diverse dataset that reflects real-world conditions.
- Build deep learning models that are resilient to inconsistencies in data.
FineDataLink in Practice
You need efficient data integration to support successful machine learning workflows. FineDataLink helps you prepare, synchronize, and transform data from multiple sources, making your data pipeline stronger. When you use FineDataLink, you can integrate images, text, audio, and tabular data with minimal effort. The platform supports real-time data synchronization and advanced ETL/ELT development, which streamlines your data preparation for model training.
FineDataLink enables you to automate data augmentation processes by connecting different systems and managing diverse data formats. You can build a high-quality data layer for business intelligence and machine learning. For example, you can use FineDataLink to collect images from various sources, apply augmentation techniques, and deliver clean, ready-to-use datasets for model training.
You benefit from reduced overfitting and improved reliability when you use FineDataLink in your machine learning projects. The platform's low-code interface and drag-and-drop functionality make it easy for you to set up data pipelines. You can focus on model optimization and generalization, knowing that your data integration is efficient and robust.
The following table highlights how data augmentation and FineDataLink work together to enhance machine learning outcomes:
You can rely on FineDataLink to manage your data efficiently, apply data augmentation techniques, and achieve better model generalization and reliability. This approach prepares your machine learning models for real-world challenges and ensures consistent performance.

Advancements in Data Augmentation
Automated Methods
You now see a shift in machine learning toward automated data augmentation methods. These approaches use algorithms to select and apply the best transformations to your data without manual intervention. Automated methods, such as those found in AutoML frameworks, have outperformed classical techniques on many benchmarks. They handle tasks like data manipulation, integration, and synthesis, which saves you time and reduces the need for expert knowledge.
AutoML platforms automate data cleaning, feature engineering, and scaling. This automation allows you to focus on building better models. For example, you can use AutoML to generate models for image classification or object detection with minimal manual effort. Automated pipelines also support efficient data labeling and hyperparameter tuning, which further improves model performance. Automated feature selection and transformation processes, including handling missing values and encoding categorical variables, are now standard in modern workflows.
FineDataLink supports these advancements by enabling seamless integration and transformation of data from multiple sources. You can build automated data pipelines that synchronize, clean, and augment your data in real time. This approach helps you create high-quality augmented data for your machine learning projects.
Generative Networks
Generative networks, especially generative adversarial networks (GANs), have become essential tools in modern data augmentation strategies. GANs generate high-quality synthetic data, which is crucial when you face data scarcity. In fields like medicine and neuroscience, GANs help you create realistic samples that improve model training and performance. Recent innovations, such as conditional GANs and Wasserstein GANs, have made these techniques even more effective.
You also see new trends like AutoAugment, which uses reinforcement learning to optimize augmentation strategies automatically. Generative models, including large language models and diffusion models, produce high-quality samples that enhance model performance, especially when your dataset is limited or imbalanced. These advancements allow you to scale your machine learning solutions and achieve accuracy scores as high as 97.66% with augmented datasets.
FineDataLink plays a key role by supporting the integration of generative models into your data workflows. You can automate the collection, transformation, and augmentation of data, ensuring your models have access to diverse and high-quality training samples.
Data augmentation plays a vital role in building robust machine learning models. You can improve model performance and reduce overfitting by increasing data diversity and size. A well-structured pipeline, supported by platforms like FineDataLink, helps you integrate and prepare data efficiently. When you explore data augmentation and integration tools, you gain the ability to handle real-world variations and build models that generalize well. Staying updated with new techniques ensures your machine learning outcomes remain strong.








