An ETL tool is a platform that extracts data from multiple sources, transforms it into a usable format, and loads it into a warehouse, lake, application, or operational system for analytics and business workflows.
The 15 Best ETL Platforms Ranked for 2026
Best for fast setup and managed connectors
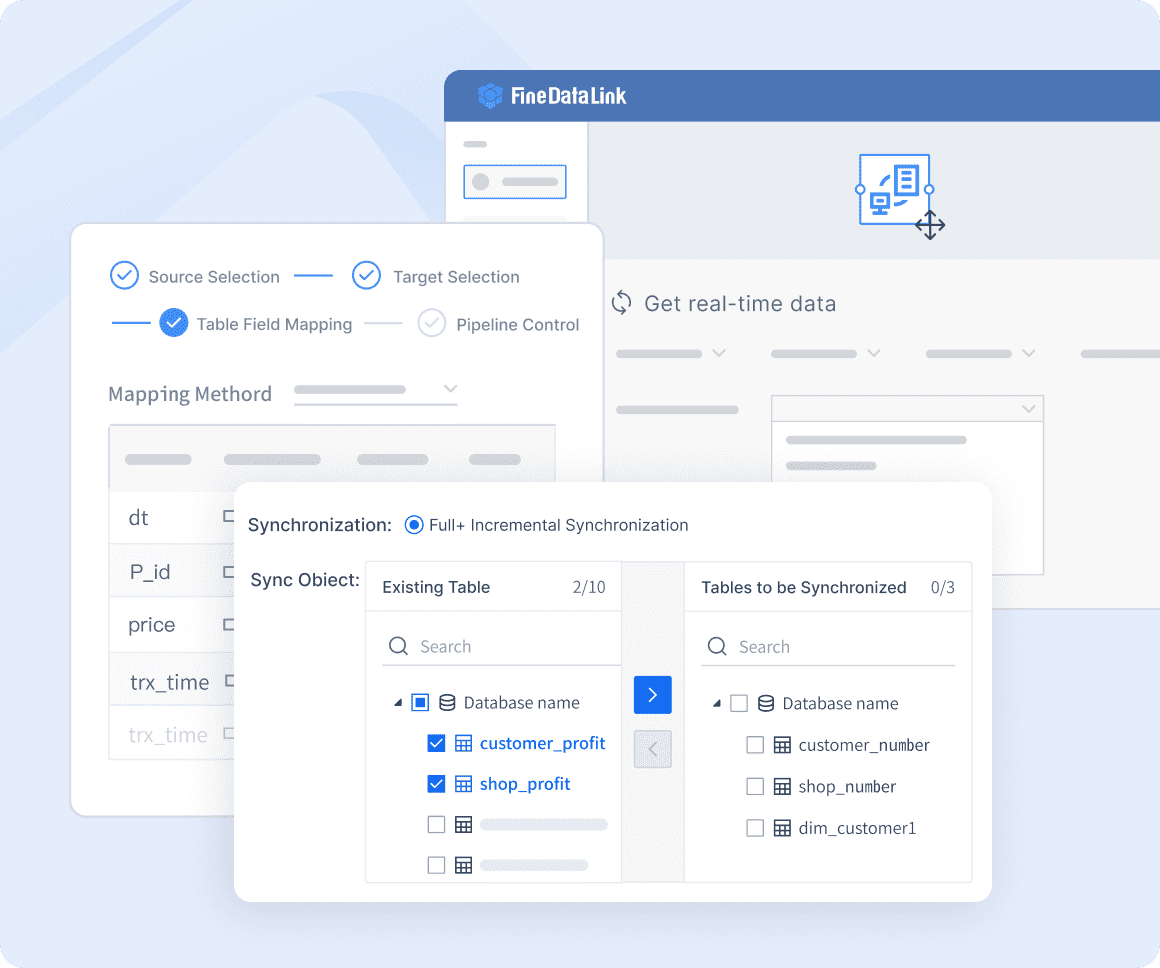
1. FineDataLink
One-sentence overview:FineDataLink is a modern data integration and ETL platform built for teams that need fast pipeline deployment, real-time and batch synchronization, broad connectivity, and lower long-term maintenance effort.
Key Features:
Broad connectivity across databases, cloud platforms, APIs, and business systems
Support for data distribution and multi-target delivery
Centralized management for sync tasks and monitoring
Pros & Cons:
Pros: Strong fit for hybrid ETL scenarios, practical balance of usability and control, supports operational sync as well as analytics pipelines, useful for teams that want to reduce custom connector work.
Cons: Buyers should still validate niche connector depth and advanced transformation requirements during a proof of concept.
Best For (Target user/scenario): Mid-market and enterprise teams that want a flexible ETL tool with both batch and real-time capabilities without taking on heavy engineering overhead.
One-sentence overview: Fivetran is a managed ELT platform known for automated connectors, schema change handling, and low day-to-day maintenance.
Key Features:
Large library of prebuilt connectors
Automated schema evolution
Managed pipeline operations
CDC and frequent sync options
Integration with cloud warehouses and dbt workflows
Pros & Cons:
Pros: Very fast to deploy, strong connector reliability, low operational burden.
Cons: Usage-based pricing can rise quickly at scale; transformation flexibility inside the platform is limited compared with engineering-first tools.
Best For (Target user/scenario): Data teams that want turnkey ingestion into cloud warehouses with minimal infrastructure work.
3. Hevo Data
One-sentence overview: Hevo Data is a cloud-native ETL/ELT platform that emphasizes ease of use, no-code setup, and quick integration with common SaaS and database sources.
Key Features:
No-code pipeline setup
Real-time and near-real-time sync
Prebuilt connectors for SaaS apps and databases
Basic transformation support
Monitoring and alerting
Pros & Cons:
Pros: Accessible for smaller teams, quick onboarding, relatively simple user experience.
Cons: Advanced customization can be limited; connector breadth may not match the largest platforms in every category.
Best For (Target user/scenario): Lean analytics teams that need to get data flowing quickly without dedicated platform engineering.
4. Stitch
One-sentence overview: Stitch is a lightweight ETL service focused on straightforward data ingestion into warehouses for analytics use cases.
Key Features:
Simple connector setup
Warehouse-focused replication
Scheduling and sync controls
Support for common SaaS tools and databases
Pros & Cons:
Pros: Easy to understand, suitable for basic ingestion, lower barrier to adoption.
Cons: Less feature depth than broader platforms; complex governance and enterprise controls are not its strongest area.
Best For (Target user/scenario): Startups and small teams with relatively standard ingestion needs.
Best for customization and engineering control
5. Airbyte
One-sentence overview: Airbyte is an open-source and commercial data movement platform that gives engineering teams strong extensibility and custom connector flexibility.
Key Features:
Open-source core
Large and growing connector ecosystem
Self-hosted and managed deployment options
Connector builder and custom source support
API-first operation
Pros & Cons:
Pros: High flexibility, strong for custom integrations, attractive for teams that value portability and transparency.
Cons: Connector quality can vary; self-hosted deployments may increase maintenance workload.
Best For (Target user/scenario): Data engineering teams that need custom connectors or want greater platform control.
6. Matillion
One-sentence overview: Matillion is a cloud-focused ETL/ELT platform designed for teams that want visual orchestration with deeper transformation control inside warehouse-centric architectures.
Key Features:
Pushdown transformations for cloud warehouses
Visual job orchestration
Support for Snowflake, BigQuery, Redshift, Databricks, and Synapse
Scheduling, monitoring, and environment management
Integration with SQL-based workflows
Pros & Cons:
Pros: Good balance of low-code development and technical depth, strong fit for modern warehouse stacks.
Cons: More configuration than fully managed ingestion tools; total cost includes platform plus warehouse compute.
Best For (Target user/scenario): Data teams that want more control over transformations without building every pipeline from scratch.
7. AWS Glue
One-sentence overview: AWS Glue is a serverless ETL service for teams operating heavily within the AWS ecosystem and needing scalable batch or streaming data pipelines.
Key Features:
Serverless Spark-based processing
Data Catalog and crawlers
Glue Studio visual authoring
Batch and streaming ETL
Tight integration with S3, Redshift, RDS, and Lake Formation
Pros & Cons:
Pros: Strong native AWS integration, scalable architecture, no cluster management.
Cons: Pricing can be harder to predict; debugging and developer experience may feel less streamlined for some teams.
Best For (Target user/scenario): AWS-centric organizations with in-house engineering capability.
8. Azure Data Factory
One-sentence overview: Azure Data Factory is Microsoft’s managed data integration service for orchestrating ETL, ELT, and hybrid data movement across cloud and on-prem systems.
Integration with Azure Synapse and Microsoft services
Scheduling, triggers, and data flow support
Pros & Cons:
Pros: Strong for Microsoft environments, hybrid deployment support, flexible orchestration.
Cons: Complex implementations can become difficult to manage; non-Azure environments may not get the same operational advantages.
Best For (Target user/scenario): Organizations standardized on Azure and Microsoft data services.
9. Apache NiFi
One-sentence overview: Apache NiFi is a flow-based data integration platform built for routing, transformation, and movement of data with fine-grained operational control.
Key Features:
Visual flow-based design
Real-time data routing
Provenance tracking
Extensive processors and extensibility
On-prem and hybrid deployment flexibility
Pros & Cons:
Pros: Strong operational visibility, flexible routing logic, good for complex internal data movement patterns.
Cons: Requires more operational expertise; not the easiest option for warehouse-first business teams.
Best For (Target user/scenario): Technical teams managing internal data flows, streaming patterns, and infrastructure-heavy environments.
Best for enterprise governance and scale
10. Informatica Intelligent Data Management Cloud
One-sentence overview: Informatica is an enterprise-grade ETL and data management platform known for governance, metadata, compliance, and large-scale integration programs.
Key Features:
Cons: Higher complexity and cost; often more platform than smaller teams need.
Best For (Target user/scenario): Large enterprises with strict compliance, governance, and multi-team data integration requirements.
11. Talend Data Fabric
One-sentence overview: Talend is a long-standing data integration platform that combines ETL, data quality, and governance for complex enterprise environments.
Key Features:
Broad connector support
Data quality tooling
Batch and near-real-time integration
Hybrid deployment options
Metadata and governance features
Pros & Cons:
Pros: Strong data quality orientation, good for mixed environments, flexible integration patterns.
Cons: Can require more setup and specialized knowledge than managed SaaS ETL tools.
Best For (Target user/scenario): Enterprises that need ETL plus data quality and hybrid deployment support.
12. IBM DataStage
One-sentence overview: IBM DataStage is an enterprise ETL platform built for large-scale transformation, governance, and integration in regulated environments.
Key Features:
Pros: Designed for large-scale, mission-critical environments, strong enterprise management.
Cons: Cost and implementation effort are significant; not ideal for small teams seeking rapid time to value.
Best For (Target user/scenario): Large regulated organizations with established enterprise data programs.
13. Oracle Data Integrator
One-sentence overview: Oracle Data Integrator is an enterprise data integration platform optimized for Oracle-heavy ecosystems and large-scale transformation workloads.
Key Features:
ELT-oriented architecture
Strong Oracle ecosystem integration
Metadata-driven design
High-volume processing support
Enterprise administration controls
Pros & Cons:
Pros: Strong fit for Oracle estates, scalable enterprise processing model.
Cons: Less attractive outside Oracle-centered stacks; licensing and administration can be complex.
Best For (Target user/scenario): Enterprises deeply invested in Oracle databases and applications.
Best value for lean teams
14. Dataddo
One-sentence overview: Dataddo is a no-code ETL/ELT platform that aims to keep setup simple and pricing easier to understand for smaller teams.
Pros: Accessible interface, good for smaller business teams, relatively quick time to implementation.
Cons: Advanced engineering and governance requirements may outgrow the platform.
Best For (Target user/scenario): SMBs and lean analytics teams that need simple, business-friendly data movement.
15. Meltano
One-sentence overview: Meltano is an open-source, code-first data integration platform built for teams that want Singer-based flexibility with modern workflow management.
Key Features:
Open-source framework
Singer tap and target compatibility
CLI-first workflow
Integration with version control and developer tooling
Extensible orchestration options
Pros & Cons:
Pros: Cost-effective for technical teams, transparent workflows, strong fit for engineering-driven stacks.
Cons: Higher maintenance than managed platforms; not aimed at non-technical users.
Best For (Target user/scenario): Small but technical teams that prioritize flexibility and open tooling over convenience.
ETL Tools List for 2026: How to Compare Platforms Before You Buy
Choosing from any etl tools list is easier when you evaluate platforms against your actual workloads instead of headline feature counts.
Start by defining your primary use case:
Batch pipelines: Scheduled movement from transactional systems into warehouses or lakes.
Real-time sync: Low-latency replication for dashboards, operational analytics, and event-driven use cases.
Reverse ETL: Sending modeled warehouse data back into CRMs, marketing platforms, and support tools.
Hybrid use cases: A mix of batch, CDC, operational sync, and analytics delivery.
Next, separate must-have requirements into clear buckets:
Maintenance effort: How much engineering time is needed for setup, monitoring, schema changes, and upgrades.
Finally, decide how your team will weigh trade-offs between:
Speed of setup
Long-term ownership cost
Engineering control
This is where many buyers misjudge tools. A platform that looks inexpensive at entry level may become costly through row-based pricing, premium connectors, or hidden maintenance work. Conversely, a platform with a higher subscription price may reduce engineering burden enough to lower total cost of ownership.
Ranking Criteria: Connectors, Cost, and Maintenance Overhead
Connector breadth and ecosystem fit
Connector coverage is often the first filter in an etl tools list, but raw connector count is not enough. A platform with 500 connectors is not automatically a better fit than one with 150 if the latter covers your core systems more reliably.
When comparing connector breadth, review support across:
Databases
SaaS applications
Cloud warehouses
Lakehouses
File systems
APIs
Streaming platforms
On-prem sources
Then go deeper into connector quality:
Reliability: Do syncs fail often under production load?
Refresh frequency: Can the platform meet your latency requirements?
Schema change handling: Does it adapt automatically or require manual intervention?
Custom source support: Can your team build or request additional connectors?
Tools such as Fivetran and Hevo prioritize managed connectors and simple setup. Platforms like Airbyte and Meltano offer more customization. FineDataLink stands out for teams that need both mainstream integration coverage and practical support for hybrid, real-time, and multi-destination scenarios.
Pricing model and total cost of ownership
ETL pricing is rarely simple. Buyers need to compare more than the starting monthly fee.
Warehouse compute generated by transformation workloads
For example:
Usage-based tools can be efficient for light workloads but expensive at large data volumes.
Compute-based tools offer flexibility but can be difficult to forecast.
Enterprise license models may look expensive upfront but make sense for large, stable environments.
A useful buying question is: What will this tool cost after 12 months of growth, not on day one?
Maintenance, reliability, and team workload
Maintenance overhead is where tool economics often change.
Review:
Setup complexity
Pipeline monitoring
Alerting
Retry logic
Versioning
Documentation quality
Testing support
Upgrade management
Security review requirements
Then estimate ongoing work tied to:
Connector fixes
Schema drift
Transformation changes
Infrastructure management
User access control
Incident response
Fully managed tools reduce operational burden but may limit customization. Engineering-first and self-hosted tools offer flexibility but often shift support responsibilities onto your team. FineDataLink, Fivetran, and Hevo are often evaluated by teams trying to minimize maintenance, while Airbyte, Meltano, NiFi, and cloud-native services like Glue or ADF appeal to teams comfortable owning more of the stack.
Side-by-Side Comparison of Features, Trade-Offs, and Pricing
Connector coverage and data source support
Here is a practical way to compare the 15 tools by connector profile rather than marketing claims.
Best managed connector breadth: Fivetran, Informatica
Best open extensibility: Airbyte, Meltano, NiFi
Best cloud ecosystem fit: AWS Glue, Azure Data Factory, Matillion
Best balance of broad integration and practical maintenance:FineDataLink
Pricing trade-offs by team size
Pricing fit often changes by company size and pipeline complexity.
Startups
Best options typically include:
Stitch
Dataddo
Hevo Data
Meltano
Airbyte
These platforms fit smaller budgets or technical teams willing to trade convenience for lower software spend. However, usage-based pricing can become less favorable as data volumes grow.
Mid-market buyers usually need a better balance between connector reliability, governance, and manageable maintenance. This is where a tool like FineDataLink can be attractive because it supports both fast implementation and more complex sync requirements without forcing an all-in enterprise platform purchase.
Large organizations care more about governance, deployment flexibility, auditability, and support models than about the lowest entry-level subscription.
Operational overhead and maintenance profile
A simple way to understand operational overhead is to group tools into three categories.
These platforms offer more flexibility or enterprise depth, but they usually require more active management, design discipline, and internal ownership.
Highest maintenance but strongest control
Airbyte self-hosted
Meltano
Apache NiFi
IBM DataStage
Oracle Data Integrator in complex deployments
These are better suited for organizations that value customization, platform control, or strict architecture alignment over convenience.
Common buyer questions and real-world evaluation signals
Will we get locked in?
Vendor lock-in usually appears in three places:
Proprietary pipeline logic
Proprietary connectors
Migration-heavy metadata models
Open and code-first tools reduce lock-in risk but increase ownership burden. Managed tools reduce effort but may make migration harder later.
How hard is migration?
Check:
Export options
Reusability of SQL/dbt models
Ability to recreate connectors elsewhere
Dependency on vendor-specific monitoring and metadata
What is the debugging experience like?
This matters more than many buyers expect. Ask:
Are logs readable?
Can you replay failed syncs?
Is lineage visible?
Can you isolate a schema drift issue quickly?
What does the user community say?
Strong evaluation signals include:
Connector issue resolution speed
Documentation depth
Frequency of product updates
Community activity
Transparency around outages or breaking changes
How to Choose the Right ETL Tool for Your Team
Choose based on your architecture and data maturity
Your best choice depends on both your current stack and how mature your data practice is.
A reporting output to warehouse or operational destination
During the proof of concept, score each tool on:
Setup time
Connector reliability
Logging quality
Alerting
Change management
Documentation
Support responsiveness
Estimated monthly cost at current and projected scale
This is often where theoretical rankings change. A platform that looks ideal on paper may fail on one critical connector or become too expensive once realistic data volume is modeled.
Use a final decision checklist
Before buying, confirm the following:
Connector fit
Does the tool support all critical systems today?
How are new connectors requested or built?
How does it handle APIs, files, and edge-case sources?
Are premium connectors or support charged separately?
Observability
Are monitoring, logs, and alerts usable for day-to-day operations?
Can failures be diagnosed without vendor support every time?
SLA expectations
What uptime and support response commitments are available?
Are enterprise support tiers required for acceptable service?
Support quality
Is onboarding effective?
Are docs current and technical enough for your team?
Future scalability
Can the platform handle more sources, more destinations, and stricter governance later?
Will it still fit if your use cases expand from batch analytics to real-time sync or reverse ETL?
Final Verdict on the Best ETL Tools List for 2026
If you need the shortest path to reliable data movement, managed platforms remain the safest option. If you need deeper customization, open and engineering-first tools still offer the most control. If you operate under strict governance or hybrid architecture constraints, enterprise platforms justify their complexity.
For many modern teams, the right choice is not the platform with the biggest connector count or the lowest advertised starting price. It is the one that matches your architecture, keeps maintenance predictable, and scales without forcing a full rebuild later.
Among this etl tools list, FineDataLink is especially worth shortlisting for teams that want a practical mix of connector coverage, real-time and batch integration, manageable ownership cost, and lower maintenance pressure. It is particularly well suited for organizations that need more than simple warehouse ingestion but do not want the operational burden of stitching together multiple tools.
If you are evaluating ETL platforms for 2026, build a shortlist around your real workloads, test failure scenarios early, and compare total ownership cost instead of feature counts alone. That is how you choose a platform that will still work for your team a year after implementation, not just during procurement.
FAQs
Focus on connector coverage, pricing model, ease of setup, transformation depth, real-time or batch support, and expected maintenance effort. The best choice depends on your data sources, team skills, and whether you need simple ingestion or more advanced pipeline control.
ETL transforms data before loading it into the destination, while ELT loads data first and performs transformations inside the warehouse or lake. ELT is often preferred in cloud data stacks because it can scale with warehouse compute.
Managed ETL tools are usually faster to deploy and require less day-to-day maintenance, which makes them attractive for lean teams. Open-source platforms can offer more flexibility and custom connector options, but they often demand more engineering time and operational ownership.
Tools with CDC and streaming or near-real-time sync are typically the best fit for low-latency pipelines. Platforms such as FineDataLink, Hevo Data, Fivetran, and AWS Glue are commonly considered when teams need fresher data delivery.
ETL pricing varies widely by vendor and may be based on usage, rows processed, connectors, compute, or fixed subscriptions. Total cost should include not just license fees, but also engineering time, infrastructure, and ongoing maintenance.
Product Trial
FineReport
Pixel-perfect reports · Interactive dashboards · Easy data entry · Digital twins
 Key Features:
Key Features: Key Features:
Key Features: Key Features:
Key Features: Key Features:
Key Features: Key Features:
Key Features: Key Features:
Key Features: Key Features:
Key Features: Key Features:
Key Features: Key Features:
Key Features: Key Features:
Key Features: Key Features:
Key Features: Key Features:
Key Features:






