Data validation techniques help teams build a trusted data foundation by checking whether data is complete, accurate, consistent, timely, and ready for analytics, AI, and business operations. Without systematic validation, downstream dashboards, reports, and AI agents operate on flawed inputs — producing confident but incorrect outputs that erode trust and drive bad decisions.
This guide covers 10 core validation methods with enterprise examples, explains where validation belongs in the data pipeline, and shows how FineDataLink automates validation as part of a governed data integration layer. For Excel-specific validation, see our dedicated guides on Excel data validation and data validation in Excel.
What Is Data Validation?
Data validation is the process of verifying that data meets defined quality standards before it is used for analysis, reporting, or operational decision-making. It answers five questions:
Complete? Are required fields populated? Are records missing?
Accurate? Do values reflect reality? Are formats correct?
Consistent? Do related fields agree across systems and time?
Unique? Are there unintended duplicates?
Timely? Is data current enough for its intended use?
Validation is distinct from data cleaning (which corrects errors after detection) and data verification (which confirms source authenticity). Validation establishes quality gates that prevent bad data from propagating through the pipeline. In modern architectures, validation must occur at multiple stages — not just at entry — because data degrades through transformation, integration, and aggregation.
Common Use Cases
Data validation is essential in various fields and applications:
Customer Information Accuracy: Businesses validate customer data to ensure accuracy, which is crucial for effective communication and customer relationship management.FineDataLink’s real-time data synchronization ensures that customer information is always up-to-date and accurate.
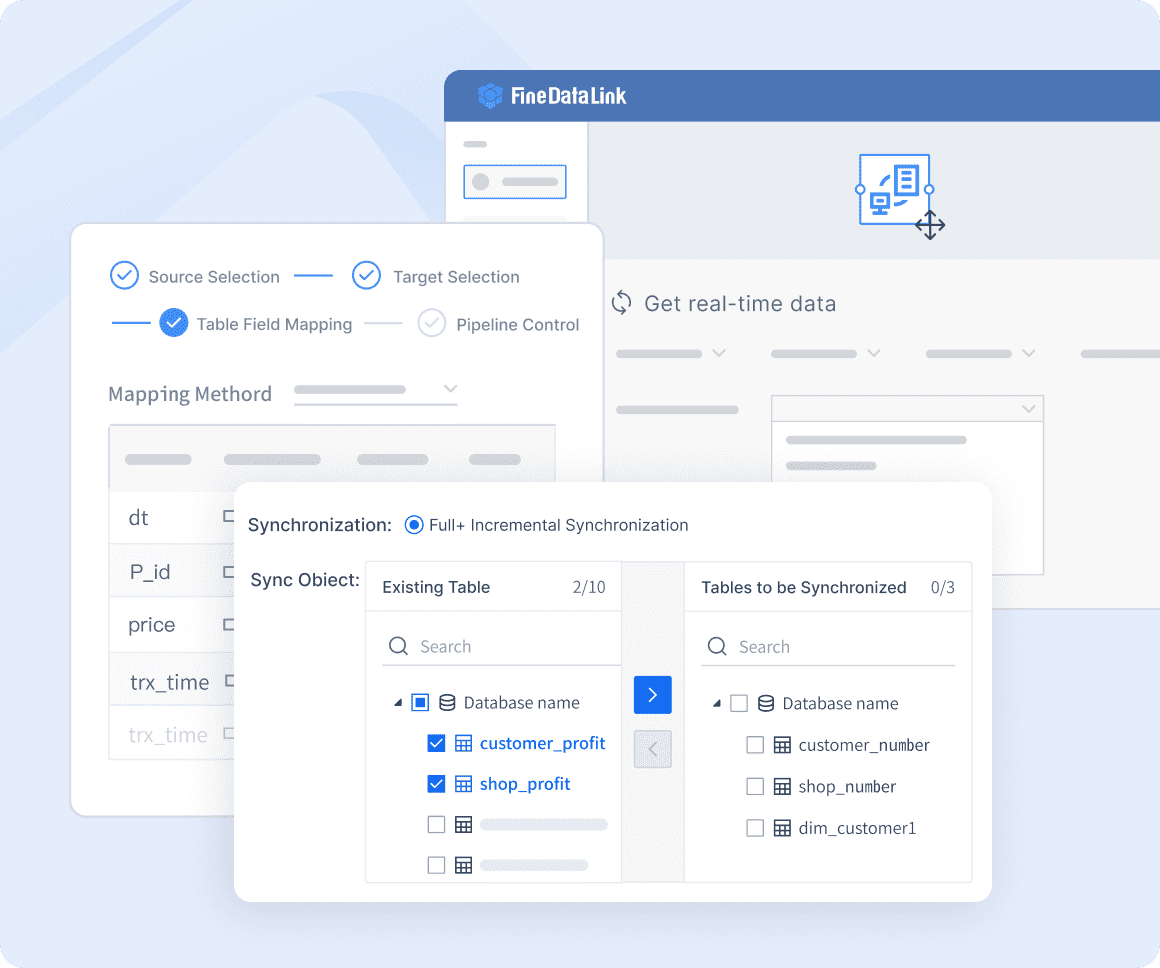
FineDataLink supports real-time data integration
Fraud Prevention in Financial Institutions: Financial institutions validate transaction data to detect and prevent fraudulent activities. FineDataLink’s automated workflows and robust security measures help in maintaining data integrity and identifying inconsistencies quickly.
Healthcare Data Integrity: Healthcare providers verify patient records to maintain accurate and reliable data, which is critical for patient care and regulatory compliance. FineDataLink’s extensive support for healthcare data formats ensures seamless data integration and validation.
Online Registration Forms: Form validation techniques ensure users enter correct information during the registration process. Server-side validation checks data correctness and alignment with project standards. FineDataLink’s low-code development environment simplifies the implementation of such validation processes.
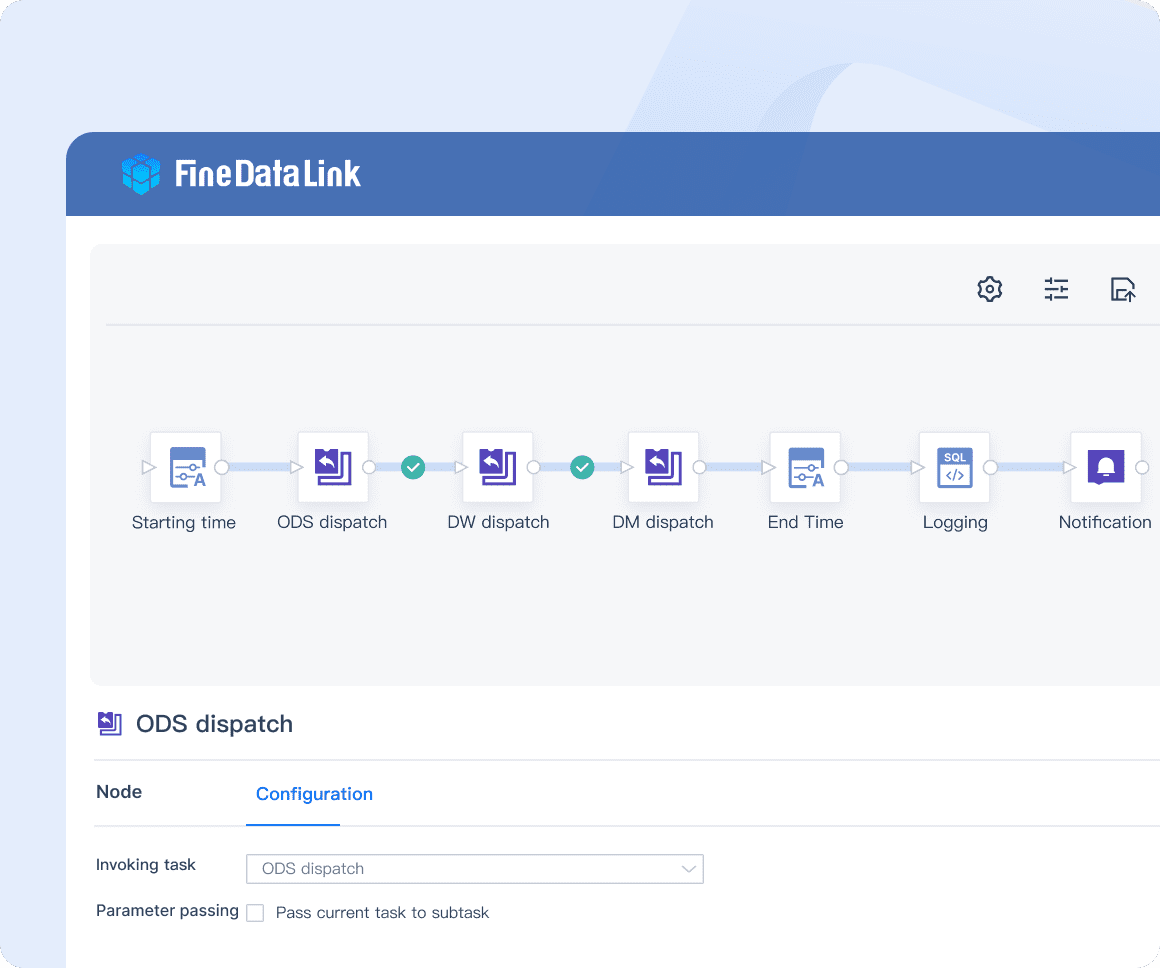
Effective and agile data warehouse construction
Developed by FanRuan, FineDataLink is a powerful data integration platform designed to ensure real-time data synchronization across connected systems, keeping information consistently up-to-date. The platform streamlines complex processes through automated workflows, significantly enhancing operational efficiency. FineDataLink’s low-code environment empowers users to create and deploy integration solutions with minimal coding, making it accessible even to those with limited technical expertise. Moreover, its advanced data processing capabilities facilitate the seamless management of large datasets, enabling precise and timely decision-making.
10 Data Validation Techniques With Examples
Technique
What It Checks
Example
Best Used In
Schema validation
required fields and structure
customer_id must exist
databases, APIs
Format validation
email/date/phone format
valid email address
forms, CRM
Range validation
values within limits
discount < 50%
sales, finance
Completeness check
missing values
no blank invoice amount
ETL pipelines
Uniqueness check
duplicate records
unique order ID
ERP, CRM
Referential integrity
related records match
order has valid customer ID
databases
Cross-field validation
logic between fields
ship date after order date
operations
Consistency validation
same meaning across systems
customer name matches CRM/ERP
integration
Timeliness validation
data freshness
inventory updated hourly
real-time analytics
Business-rule validation
company-specific logic
approval needed above threshold
workflows
Types of Data Validation
Syntactic Validation
Syntactic validation checks data format and structure to ensure it conforms to predefined rules.This technique is crucial for catching errors early and preventing incorrect data entry. Examples include:
Email Addresses: Must follow a specific pattern (e.g., user@domain.com).
Phone Numbers: Require a certain number of digits, often formatted with country codes.
Postal Codes: Must adhere to regional formats.
By implementing syntactic validation, organizations can ensure that data collected adheres to expected patterns and structures, thereby maintaining data integrity from the outset. Automated tools like FineDataLink can be configured to perform syntactic validation, streamlining the process and reducing the chances of human error.
Semantic Validation
Semantic validation goes beyond checking format and structure to verify the meaning and context of the data. This method ensures that data values make sense within their specific context, adding an extra layer of verification to enhance data quality. Examples include:
Date of Birth: Must fall within a reasonable range (e.g., not in the future or excessively far in the past).
Product Price: Should not be negative and must fall within a realistic range for the product category.
Inventory Levels: These should not be negative and should correspond to actual stock availability.
Semantic validation helps organizations ensure that their data is not only correctly formatted but also logically sound. This type of validation is essential for maintaining data accuracy and reliability, particularly in industries where precise data is critical, such as healthcare, finance, and retail.
FineDataLink excels in both syntactic and semantic validation, offering robust features that allow users to define validation rules easily. The platform supports real-time data synchronization and automated workflows, ensuring that both syntactic and semantic errors are caught and corrected promptly. By using FineDataLink, organizations can automate their data validation processes, enhancing overall data quality and operational efficiency.
Basic Data Validation Techniques
Manual Data Validation Techniques
Pros and Cons
Manual data validation techniques involve human intervention to verify data accuracy. These techniques offer several advantages:
Flexibility: Humans can adapt to unique data scenarios and handle unexpected data variations.
Contextual Understanding: Humans can interpret data nuances and complex relationships better than machines, ensuring more accurate validation.
Expert Judgment: Experienced professionals can apply their knowledge and expertise to make informed decisions during the validation process.
However, manual data validation techniques also have drawbacks:
Time-Consuming: Manual processes are labor-intensive and take longer to complete, leading to inefficiencies.
Prone to Errors: Human error is a significant risk, potentially leading to inaccuracies and data inconsistencies.
Scalability Issues: Manual methods are not easily scalable, making it challenging to handle large datasets efficiently.
Best Practices
Adopting best practices enhances the effectiveness of manual data validation techniques:
Standardize Procedures: Establish clear guidelines and protocols for data validation to ensure consistency across the team.
Training: Ensure that team members receive proper training on validation techniques, data integration tools, and best practices.
Regular Audits: Conduct periodic reviews and audits to identify and rectify errors, ensuring ongoing data accuracy.
Documentation: Maintain detailed records of validation processes, decisions made, and issues encountered to improve transparency and accountability.
Leveraging Tools: While primarily manual, incorporating tools like FineDataLink can aid in certain aspects of validation, such as initial data cleansing and error detection, to streamline the process.
By adhering to these best practices, organizations can mitigate the limitations of manual data validation and enhance data quality. Combining human expertise with supportive tools like FineDataLink can provide a balanced approach, leveraging the strengths of both manual and automated validation methods. This hybrid approach ensures data accuracy, reliability, and integrity, supporting better decision-making and operational efficiency.
Automated Data Validation Techniques
Tools and Software
Automated data validation techniques harness advanced technology to ensure data accuracy and integrity. Several data validation tools and software options facilitate this process:
Data Quality Tools: These tools, such as FineDataLink, promptly identify and rectify data errors. They provide real-time monitoring and correction capabilities, enhancing overall efficiency and accuracy.
Automated Data Validation Tools: Leveraging artificial intelligence (AI) and machine learning (ML), these tools detect low-quality data, flag inconsistencies, and alert stakeholders. They adapt to evolving data patterns, improving validation outcomes.
Benefits of Automated Tools
Automated tools offer several compelling advantages:
Speed: They validate large datasets rapidly, reducing processing time compared to manual methods.
Consistency: By standardizing validation processes, these tools minimize human error and ensure uniformity across data entries.
Efficiency: Automated systems reduce manual labor, allowing teams to focus on more strategic tasks and improving overall productivity.
Implementation Steps
Effectively implementing automated data validation techniques involves several key steps:
Select Appropriate Tools: Choose tools that align with your specific validation requirements. Consider factors like compatibility with existing systems, scalability, and feature sets. For instance, FineDataLink offers robust data integration and validation capabilities, making it a strong candidate for many organizations.
Define Validation Rules: Establish clear criteria for data accuracy and quality. This includes setting up rules for format checks, data ranges, and consistency requirements. FineDataLink allows for customizable validation rules to suit diverse data needs.
Integrate with Existing Systems: Ensure seamless integration with current data management and processing systems. Proper integration facilitates smooth data flow and consistency across platforms.
Monitor and Adjust: Continuously monitor the validation processes and assess performance. Regularly review and adjust validation rules to adapt to changing data patterns and business needs. Automated tools like FineDataLink offer real-time analytics and adjustment capabilities to keep the validation process optimized.
Automated data validation techniques streamline data management processes, ensuring high data quality with minimal human intervention. By leveraging advanced tools and following best practices, organizations can achieve greater efficiency, accuracy, and consistency in their data validation efforts.
Use Manual Validation When...
Use Automated Validation When...
dataset is small
data updates daily or hourly
business rules are still being explored
rules are stable and repeatable
one-time audit is needed
data feeds multiple dashboards or AI agents
human judgment is required
errors need to be caught before reports
Decision framework: If you perform the same validation more than twice, automate it. Reserve manual validation for rule discovery, exception handling, and periodic audit of automated systems. The goal is not to eliminate human judgment but to apply it where it creates unique value.
Where Data Validation Happens in the Data Pipeline
Validation is not a single checkpoint. It must be embedded at every stage where data transforms, moves, or aggregates. Gaps between stages are where quality silently degrades.
Pipeline Stage
Validation Focus
Example Checks
Responsible Layer
Source system
Origin data quality at point of creation
Form input validation, ERP master data controls, IoT sensor calibration
Application owners, device firmware
Ingestion
Schema, format, completeness upon arrival
File structure verification, API response validation, CDC change detection
Integration platform (FineDataLink)
Transformation
Logic correctness after joins, aggregations, derivations
Input data fitness for model inference or NL generation
Feature drift detection, distribution shift alerts, grounding verification against source
ML ops / AI agent governance
Skipping validation at any stage creates technical debt that compounds downstream. A format error caught at ingestion costs seconds to fix; the same error discovered in an executive dashboard costs hours of investigation and eroded stakeholder trust.
Advanced Data Validation Techniques
Statistical Data Validation Techniques
Outlier Detection
Outlier detection identifies data points that deviate significantly from the rest of the dataset. These outliers can indicate errors, anomalies, or rare events. Data professionals use various statistical methods to detect these outliers, ensuring data accuracy and reliability. Common techniques include:
Z-Score Analysis: This method measures how many standard deviations a data point is from the mean. A high Z-score indicates that the data point is an outlier.
Interquartile Range (IQR): IQR identifies outliers by measuring the spread of the middle 50% of the data. Any data point lying beyond 1.5 times the IQR from the quartiles is considered an outlier.
Box Plots: These visual tools display data distribution and highlight outliers, providing a clear picture of any anomalies within the dataset.
Outlier detection enhances data quality by either removing or investigating these anomalies. This process ensures that subsequent analyses and decisions are based on accurate data.
Data Imputation
Data imputation addresses missing or incomplete data, a common issue that can skew results and lead to incorrect conclusions.Data professionals use various techniques to fill in these gaps, maintaining the integrity and robustness of the dataset. Key techniques include:
Mean/Median Imputation: This straightforward method replaces missing values with the mean or median of the dataset, maintaining central tendency.
Regression Imputation: More sophisticated, this technique uses regression models to predict and replace missing values based on other variables in the dataset.
K-Nearest Neighbors (KNN): KNN fills in missing data based on the values of similar data points, ensuring that the imputed values reflect the structure of the data.
Effective data imputation is crucial for maintaining dataset integrity, ensuring that analyses remain robust and reliable. Using advanced tools like FineDataLink, which offers comprehensive data imputation features, can automate and enhance this process, providing more accurate and consistent results.
By integrating these statistical data validation techniques into their workflows, organizations can significantly improve data quality, leading to better, more informed decision-making.
Machine Learning Approaches for Data Validation Techniques
Anomaly Detection
Anomaly detection leverages machine learning to identify unusual patterns within datasets, which can signal errors, fraud, or significant events.Machine learning models are trained on historical data to recognize these deviations. Common algorithms include:
Isolation Forest: This algorithm isolates anomalies by creating random partitions in the data. By focusing on the number of partitions required to isolate a data point, it effectively identifies outliers.
One-Class SVM: This method classifies data points into "normal" or "anomalous" categories based on training data. It is effective for detecting deviations in datasets with a high number of features.
Autoencoders: These are neural networks designed to compress and reconstruct data. By learning the normal data distribution, autoencoders can highlight anomalies that deviate significantly from the learned patterns.
Anomaly detection with machine learning automates the identification of irregularities, greatly enhancing the accuracy and efficiency of data validation techniques. Tools like FineDataLink integrate advanced anomaly detection algorithms, offering robust solutions for real-time monitoring and error detection.
Predictive Validation
Predictive validation employs machine learning to forecast potential data quality issues before they manifest.This proactive approach allows organizations to address problems before they affect analyses and decision-making. Key steps in predictive validation include:
Data Collection: Gather and prepare historical data to train the predictive models. High-quality, comprehensive datasets are crucial for accurate predictions.
Feature Engineering: Identify and select relevant features that significantly impact data quality. Effective feature engineering improves model performance and prediction accuracy.
Model Training: Train machine learning models using the prepared data to predict potential data quality issues. Techniques such as regression analysis, classification, and ensemble methods are commonly used.
Validation and Testing: Assess the model's performance using test datasets to ensure it accurately predicts data quality issues. Continuous monitoring and adjustment are necessary to maintain model reliability.
Predictive validation helps in proactive data management by forecasting and mitigating potential quality issues. This technique ensures that data remains reliable and accurate, thus supporting more informed decision-making. Platforms like FineDataLink utilize advanced predictive analytics to provide early warnings of data quality concerns, enabling timely intervention and maintaining data integrity.
By incorporating these machine learning approaches, organizations can significantly improve their data validation processes, leading to more accurate, reliable, and actionable data.
How FineDataLink Automates Data Validation
FineDataLink is the data movement and integration layer that makes trusted, timely data available for analysis and AI. It embeds validation directly into data pipelines rather than treating it as a separate, after-the-fact activity.
Specifically, FineDataLink helps teams:
Connect data across systems: Native connectors to databases, APIs, ERP, CRM, SaaS platforms, and file sources ensure schema and format validation occurs at the point of extraction — before bad data enters the pipeline.
Transform data across formats: Encoding conversion, type casting, hierarchical flattening, and field mapping include inline validation rules that catch truncation, overflow, and mapping errors during transformation rather than after loading.
Build real-time or scheduled data pipelines: CDC-based synchronization and batch schedules include configurable validation checkpoints with automatic error handling, quarantine, and alerting — preventing silent failures.
Standardize validation rules: Centralized rule definitions ensure the same completeness, uniqueness, and referential integrity checks apply consistently across all pipelines consuming the same source — eliminating departmental variation.
Reduce manual ETL and repetitive data preparation: Automated validation replaces spreadsheet-based spot checks and manual reconciliation, freeing analysts for higher-value interpretation and decision support.
Make trusted, timely data available for analytics and AI: Validated, governed data flows directly into warehouses, BI platforms, and AI agents — ensuring downstream consumers operate on reliable foundations.
After FineDataLink establishes a validated, governed data foundation, Dora enables business users to act on that trusted data through AI-powered interaction:
Natural-language data Q&A: Users ask questions like "What drove last week's margin decline?" and receive answers grounded in validated FineDataLink-sourced data — not raw, unverified inputs.
Insight push: Scheduled briefings highlight validated metric changes, anomalies, and trends without requiring users to navigate dashboards.
Alerts and reminders: Threshold breaches detected against validated data trigger proactive notifications before issues escalate.
Repeated analysis as reusable data Skills: Frequently asked validation-dependent questions become codified Skills that standardize how specific business questions are answered across the organization.
Workflow and action integration: Validated insights trigger downstream actions (task creation, approval routing, notification dispatch) within governed workflows.
Dora does not validate data itself. It relies entirely on the trusted foundation that FineDataLink provides. This separation ensures AI-generated outputs inherit the same quality guarantees as the underlying data — making AI-assisted decisions as reliable as the validation program that supports them.
Access a wealth of case studies, industry insights, and solution guides to accelerate digital transformation.
FAQ
Why is data validation important?
Data validation stands as an essential linchpin in maintaining data integrity. Accurate data optimizes business operations and supports reliable decision-making. Companies can guarantee the accuracy, reliability, and security of their valuable data assets by implementing strong data validation practices.
How do automated data validation techniques work?
Automated data validation techniques leverage technology to ensure data accuracy. Tools and software perform validation checks quickly and consistently. These tools use predefined rules and criteria to identify and rectify errors. Automated validation reduces human error and increases efficiency.
What are the benefits of using machine learning for data validation?
Machine learning enhances data validation by identifying unusual patterns and predicting data quality issues. Algorithms like Isolation Forest and Autoencoders detect anomalies. Predictive models forecast potential data quality problems. Machine learning automates the identification of irregularities, improving accuracy and efficiency.
What role does data validation play in data analysis?
Data validation ensures that data used in analysis is accurate and reliable. Validated data leads to better insights and more informed decision-making. Data validation helps prevent incorrect data entry, ensuring that analyses are based on high-quality data.
Can data validation improve data security?
Yes, data validation can improve data security. By ensuring data accuracy and reliability, validation practices help protect valuable data assets. Strong data validation practices reduce the risk of data breaches and unauthorized access.